单词
efficacy: 功效decompose: 分解suboptimal: 次优的exploit: 利用
论文
综述记录:
- Recent researches have mainly investigated three important factors of networks: depth, width, and cardinality.
- VGGNet shows that stacking blocks with the same shape gives fair results.
- GoogLeNet shows that width is another important factor to improve the performance of a model.
- Xception and ResNeXt come up with to increase the cardinality of a network. They empirically show that cardinality not only saves the total number of parameters but also results in stronger representation power than the other two factors: depth and width.
- CBAM can be used as a plug-and-play module for pre-existing base CNN architectures.
注:宽度表示的即是通道数,基数(cardinality)相当于多分支网络快中的分支数(比如下图中的cardinality=32)。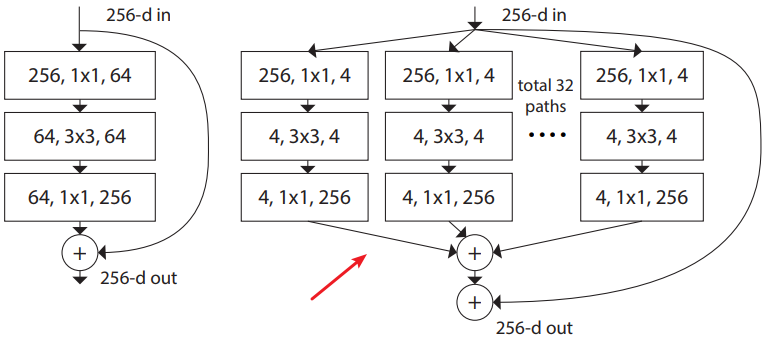
思想
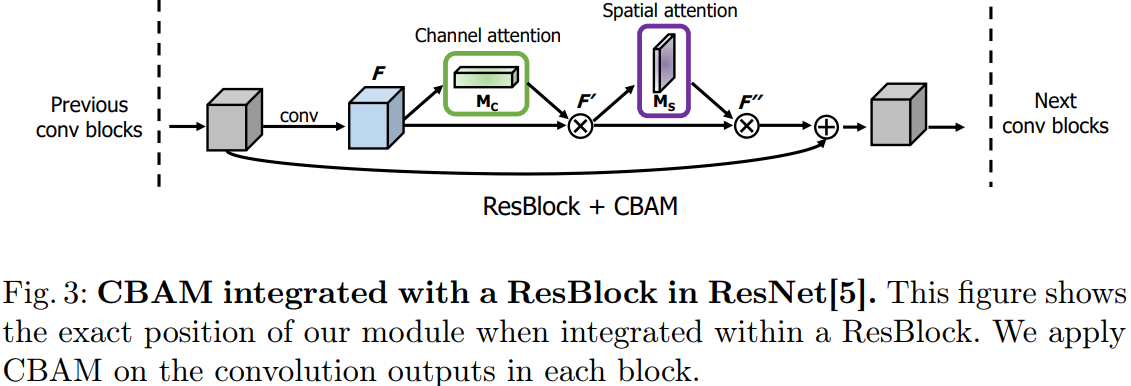
从channel和spatial两个维度增加注意力机制,其中的channel解决‘what’的问题,spatial解决‘where’的问题。
设 为中间的feature map,CBAM会产生一维的channel注意力map
为中间的feature map,CBAM会产生一维的channel注意力map 以及二维spatial注意力map
以及二维spatial注意力map ,最终将注意力权值信息作用于原feature map:
,最终将注意力权值信息作用于原feature map: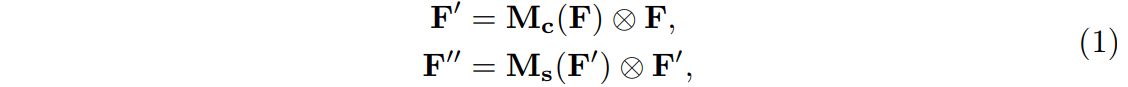
其中: 表示的是元素级别的乘法操作。
表示的是元素级别的乘法操作。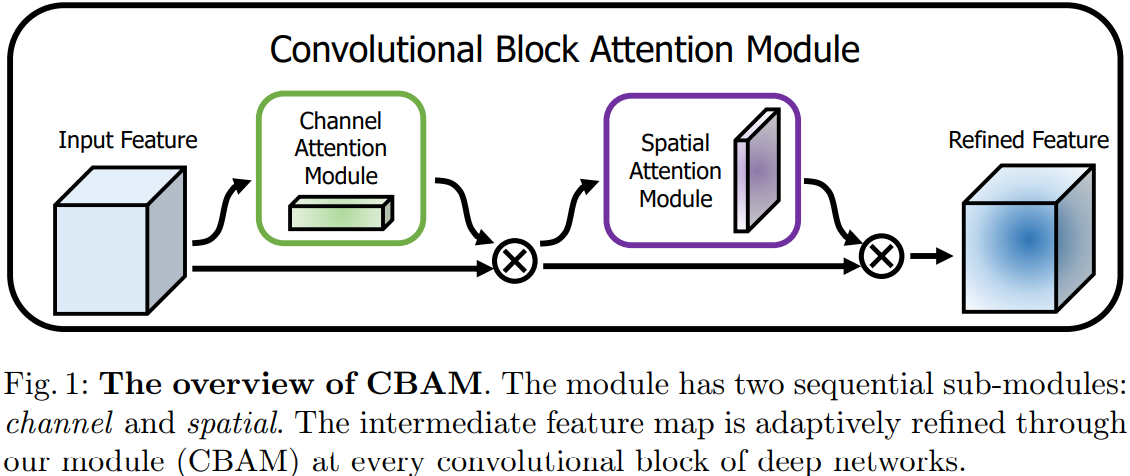
Channel attention module
作者认为,MaxPool同样能够提取到具有区分性的特征,所以在聚合spatial信息的时候,同时采用MaxPool和AvgPool。通过两个Pool之后分别产生: 以及
以及 。然后两者被送入共享的多层感知机(MLP),其操作方式和SE-Block很相似。为了减少参数量,MLP中间层为
。然后两者被送入共享的多层感知机(MLP),其操作方式和SE-Block很相似。为了减少参数量,MLP中间层为 ,实现了降维。通过MLP之后,两种Pool的结果进行向量加法运算,产生最终的Channel Attention。
,实现了降维。通过MLP之后,两种Pool的结果进行向量加法运算,产生最终的Channel Attention。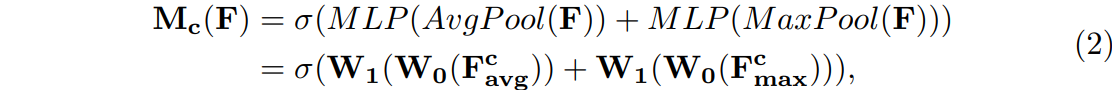
其中: 表示Relu非线性激活运算,
表示Relu非线性激活运算, 和
和 是MLP的weights。
是MLP的weights。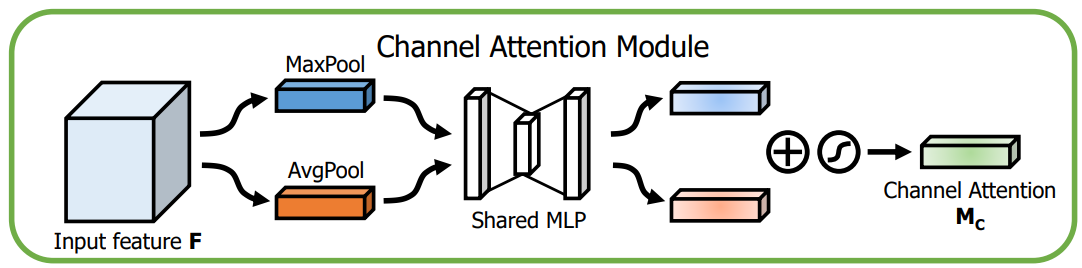
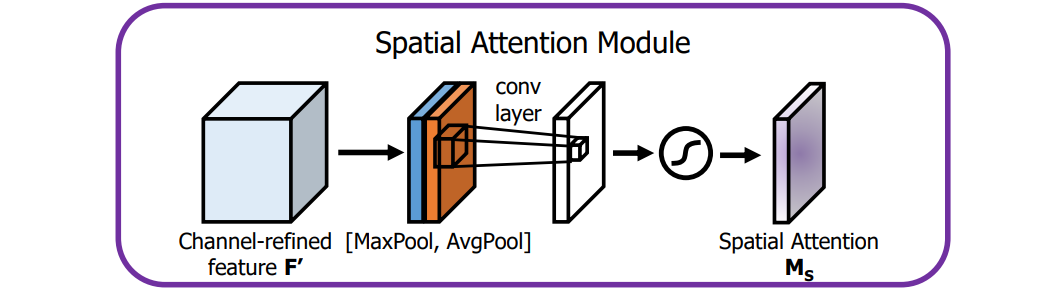
Spatial attention module
为了产生spatial attention map,首先按channel维度进行两种Pool操作(MaxPool和AvgPool)产生两个2D的maps ,对于这两个maps按channel连接之后,通过一个
,对于这两个maps按channel连接之后,通过一个 的卷积层产生最终的Spatial Attention Map:
的卷积层产生最终的Spatial Attention Map: ,公式展示如下:
,公式展示如下: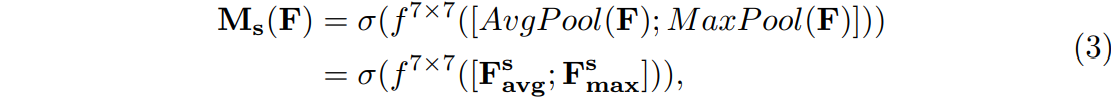
对于以上的两种注意力机制,作者的实验表示:
- MaxPool仍旧有意义;
- Pool操作相对于
 卷积效果更好;
卷积效果更好; - Spatial Attention中大的卷积核效果更好;
- 两种Attention的串联结构比并联效果好;
- Channel Attention位于Spatial Attention之前更佳;
利用Grad-CAM进行可视化对比


代码
class ChannelAttention(nn.Module):def __init__(self, in_planes, ratio=16):super(ChannelAttention, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.max_pool = nn.AdaptiveMaxPool2d(1)self.fc1 = nn.Conv2d(in_planes, in_planes // 16, 1, bias=False)self.relu1 = nn.ReLU()self.fc2 = nn.Conv2d(in_planes // 16, in_planes, 1, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))out = avg_out + max_outreturn self.sigmoid(out)
class SpatialAttention(nn.Module):def __init__(self, kernel_size=7, padding=3):super(SpatialAttention, self).__init__()self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)self.sigmoid = nn.Sigmoid()def forward(self, x):# x: batch * channel * h * wavg_out = torch.mean(x, dim=1, keepdim=True)max_out = torch.max(x, dim=1, keepdim=True)[0]x = torch.cat([avg_out, max_out], dim=1)x = self.conv1(x)return self.sigmoid(x)
对于上面两种方式产生的权值,按*操作乘到原feature maps即可。
总结
可以看到,一维数组的变换通常就是利用FC进行,二维或者三维的即是利用Conv层。(通过网络自己对变换操作的学习来完成自己想要的结果)

若有收获,就点个赞吧
0 人点赞
