这部分还未涉及到语言中的API,直接使用API调试工具就可以了
索引
类比到关系型数据库,创建索引等同于创建数据库,下面都以创建
**shopping**索引为例
创建
请求地址:[http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping) PUT
响应结果:
{"acknowledged": true,//响应结果"shards_acknowledged": true,//分片结果"index": "shopping"//索引名称}
在ES中,索引是唯一的,因此如果再次发起请求,则会收到服务器的错误提示:
{"error": {"root_cause": [{"type": "resource_already_exists_exception","reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists","index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ","index": "shopping"}],"type": "resource_already_exists_exception","reason": "index [shopping/J0WlEhh4R7aDrfIc3AkwWQ] already exists","index_uuid": "J0WlEhh4R7aDrfIc3AkwWQ","index": "shopping"},"status": 400}
查询&删除
查看所有索引
请求地址:[http://127.0.0.1:9200/_cat/indices?v](http://127.0.0.1:9200/_cat/indices?v) GET
响应结果:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open shopping J0WlEhh4R7aDrfIc3AkwWQ 1 1 0 0 208b 208b
查询单个索引
请求地址:[http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping) GET
{"shopping": {//索引名"aliases": {},//别名"mappings": {},//映射"settings": {//设置"index": {//设置 - 索引"creation_date": "1617861426847",//设置 - 索引 - 创建时间"number_of_shards": "1",//设置 - 索引 - 主分片数量"number_of_replicas": "1",//设置 - 索引 - 主分片数量"uuid": "J0WlEhh4R7aDrfIc3AkwWQ",//设置 - 索引 - 主分片数量"version": {//设置 - 索引 - 主分片数量"created": "7080099"},"provided_name": "shopping"//设置 - 索引 - 主分片数量}}}}
删除单个索引
请求地址:[http://127.0.0.1:9200/shopping](http://127.0.0.1:9200/shopping) DELETE
请求结果:
{"acknowledged": true // 删除成功}
文档
文档其实就相当于关系型数据库中的每一条记录,但是在ES中,记录的类型是可以不同的
创建文档
请求地址:[http://127.0.0.1:9200/shopping/_doc](http://127.0.0.1:9200/shopping/_doc) POST
请求体中的数据:
{"title":"小米手机","category":"小米","images":"http://www.gulixueyuan.com/xm.jpg","price":3999.00}
响应结果:
{"_index": "shopping",//索引"_type": "_doc",//类型-文档"_id": "ANQqsHgBaKNfVnMbhZYU",//唯一标识,可以类比为 MySQL 中的主键,随机生成"_version": 1,//版本"result": "created",//结果,这里的 create 表示创建成功"_shards": {//"total": 2,//分片 - 总数"successful": 1,//分片 - 总数"failed": 0//分片 - 总数},"_seq_no": 0,"_primary_term": 1}
- 注意:上述的方法中不能使用PUT请求,而是只能使用POST请求
_id就相当于数据库中的主键,作为数据的唯一标识。
- 默认情况下,如果不指定,那么ES会随机生成一个
- 如果需要自定义唯一标识,那么就需要在请求的时候进行指定,如:
[http://127.0.0.1:9200/shopping/_doc/1](http://127.0.0.1:9200/shopping/_doc/1)- 另外,如果指定了唯一标识:ID,那么请求方式可以使用
PUT
查询文档
主键查询
请求地址:[http://127.0.0.1:9200/shopping/_doc/1](http://127.0.0.1:9200/shopping/_doc/1) GET
返回结果:
{"_index": "shopping","_type": "_doc","_id": "1","_version": 1,"_seq_no": 1,"_primary_term": 1,"found": true,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}}
如果是查找不存在的内容,ES服务器则会返回found: false
{"_index": "shopping","_type": "_doc","_id": "1001","found": false}
查询所有数据
{"took": 133,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 2,"relation": "eq"},"max_score": 1,"hits": [{"_index": "shopping","_type": "_doc","_id": "ANQqsHgBaKNfVnMbhZYU","_score": 1,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}},{"_index": "shopping","_type": "_doc","_id": "1","_score": 1,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}}]}}
全量修改 & 局部修改 & 删除
全量修改
全量修改就是直接将原有的数据进行覆盖操作
请求地址:[http://127.0.0.1:9200/shopping/_doc/1](http://127.0.0.1:9200/shopping/_doc/1) POST
请求内容:
{"title":"华为手机","category":"华为","images":"http://www.gulixueyuan.com/hw.jpg","price":1999.00}
响应结果:
{"_index": "shopping","_type": "_doc","_id": "1","_version": 2,"result": "updated",//<-----------updated 表示数据被更新"_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 2,"_primary_term": 1}
局部修改
只修改数据中的一部分,而不是使用新数据覆盖原有的数据
请求地址:[http://127.0.0.1:9200/shopping/_update/1](http://127.0.0.1:9200/shopping/_update/1) POST
请求内容:
{"doc": {"title":"小米手机","category":"小米"}}
响应结果:
{"_index": "shopping","_type": "_doc","_id": "1","_version": 3,"result": "updated",//<-----------updated 表示数据被更新"_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 3,"_primary_term": 1}
更新后的结果:
{"_index": "shopping","_type": "_doc","_id": "1","_version": 3,"_seq_no": 3,"_primary_term": 1,"found": true,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/hw.jpg","price": 1999}}
局部修改的时候,如果使用到的字段是原本数据中不存在的,那么就会将进行更新操作,添加一个新的字段
删除
删除一个文档并不会直接将其从磁盘上删除,执行的只是逻辑删除操作,只是对文档进行了删除标记
请求地址:[http://127.0.0.1:9200/shopping/_doc/1](http://127.0.0.1:9200/shopping/_doc/1) DELETE
返回结果:
{"_index": "shopping","_type": "_doc","_id": "1","_version": 4,"result": "deleted",//<---删除成功"_shards": {"total": 2,"successful": 1,"failed": 0},"_seq_no": 4,"_primary_term": 1}
高级查询
条件查询&分页查询&查询排序
现在假设有如下数据:
{"took": 5,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 6,"relation": "eq"},"max_score": 1,"hits": [{"_index": "shopping","_type": "_doc","_id": "ANQqsHgBaKNfVnMbhZYU","_score": 1,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}},{"_index": "shopping","_type": "_doc","_id": "A9R5sHgBaKNfVnMb25Ya","_score": 1,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}},{"_index": "shopping","_type": "_doc","_id": "BNR5sHgBaKNfVnMb7pal","_score": 1,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}},{"_index": "shopping","_type": "_doc","_id": "BtR6sHgBaKNfVnMbX5Y5","_score": 1,"_source": {"title": "华为手机","category": "华为","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}},{"_index": "shopping","_type": "_doc","_id": "B9R6sHgBaKNfVnMbZpZ6","_score": 1,"_source": {"title": "华为手机","category": "华为","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}},{"_index": "shopping","_type": "_doc","_id": "CdR7sHgBaKNfVnMbsJb9","_score": 1,"_source": {"title": "华为手机","category": "华为","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}}]}}
条件查询
URL带参查询
假如现在需要查询category为小米的文档,可向ES服务器发送请求:
请求地址:[http://127.0.0.1:9200/shopping/_search?q=category:](http://127.0.0.1:9200/shopping/_search?q=category:)小米 GET
返回结果:
{"took": 94,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 3,"relation": "eq"},"max_score": 1.3862942,"hits": [{"_index": "shopping","_type": "_doc","_id": "ANQqsHgBaKNfVnMbhZYU","_score": 1.3862942,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 3999}},{"_index": "shopping","_type": "_doc","_id": "A9R5sHgBaKNfVnMb25Ya","_score": 1.3862942,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}},{"_index": "shopping","_type": "_doc","_id": "BNR5sHgBaKNfVnMb7pal","_score": 1.3862942,"_source": {"title": "小米手机","category": "小米","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}}]}}
并不推荐直接将查询的内容放在路径中,这样对数据不安全,并且很有可能因为中文而出现乱码的情况,为了避免这种情况,我们需要将查询的数据放入请求体中,并使用
json格式进行封装
请求体带参查询
需求如上,还是查询category为小米的文档,请求方式如下:
请求地址:[http://127.0.0.1:9200/shopping/_search](http://127.0.0.1:9200/shopping/_search) GET
请求体:
{"query":{"match":{"category":"小米"}}}
最后同样可以得到预期的查询结果
请求体查询所有
将JSON数据中的match字段更换成match_all即可
请求地址:[http://127.0.0.1:9200/shopping/_search](http://127.0.0.1:9200/shopping/_search) GET
请求体:
{"query":{"match_all":{}}}
指定数据字段
同数据库中的操作一样,我们有些时候是不需要查询出所有的字段的,因此可以对数据字段进行限制
{"query":{"match_all":{}},"_source":["title"]}
这样,最后查询出来的数据中,就只有title字段
"hits": [{"_index": "shopping","_type": "_doc","_id": "ANQqsHgBaKNfVnMbhZYU","_score": 1,"_source": {"title": "小米手机"}},{"_index": "shopping","_type": "_doc","_id": "A9R5sHgBaKNfVnMb25Ya","_score": 1,"_source": {"title": "小米手机"}},{"_index": "shopping","_type": "_doc","_id": "BNR5sHgBaKNfVnMb7pal","_score": 1,"_source": {"title": "小米手机"}},{"_index": "shopping","_type": "_doc","_id": "BtR6sHgBaKNfVnMbX5Y5","_score": 1,"_source": {"title": "华为手机"}},{"_index": "shopping","_type": "_doc","_id": "B9R6sHgBaKNfVnMbZpZ6","_score": 1,"_source": {"title": "华为手机"}},{"_index": "shopping","_type": "_doc","_id": "CdR7sHgBaKNfVnMbsJb9","_score": 1,"_source": {"title": "华为手机"}}]
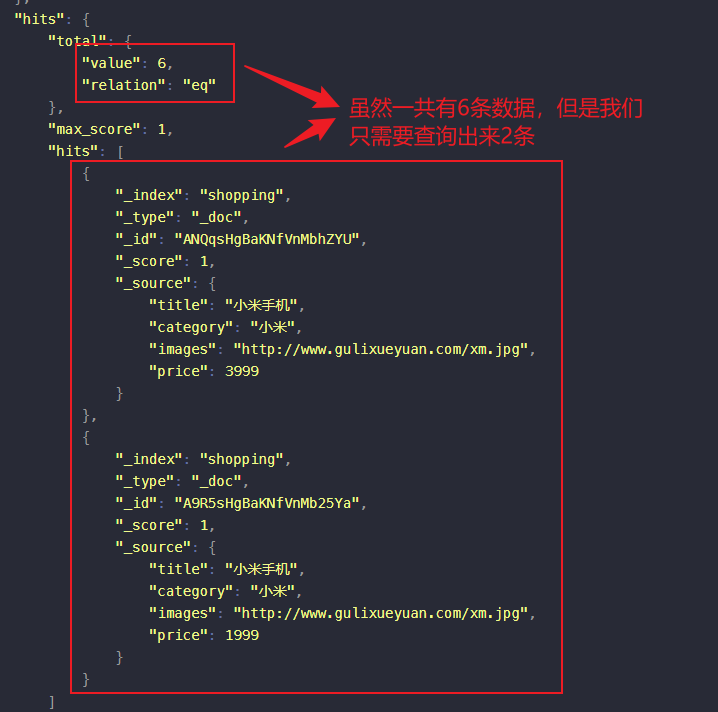
分页查询
在JSON数据体中使用from和size两个字段来进行设置分页查询
{"query":{"match_all":{}},"from":0,"size":2}
查询排序
在查询的时候,有时候我们想要查询出来的数据按照某种指定的方式进行排序,比如按照价格,按照创建时间等等,这可以通过在JSON数据中的sort字段来进行设置
假设我们现在需要通过
price字段来进行降序排序,那么传输的数据如下所示:
{"query":{"match_all":{}},"sort":{"price":{"order":"desc"}}}
多条件查询&范围查询
多条件查询
在关系型数据库中,我们的SQL语句,查询条件往往也不止一个,在ES中也同样如此
假设我们现在需要查询手机品牌为小米,并且价格为3999元的所有数据,
那么请求体中的JSON数据如下所示:
{"query":{"bool":{"must":[{"match":{"category":"小米"}},{"match":{"price":3999.00}}]}}}
must字段表示,我们的查询条件是与的关系,也就是需要同时满足后续设定的所有查询条件
而如果我们想要查询出手机品牌为小米或华为的所有数据,很显然这是一种或的关系,那么就需要使用should关键字,表示只要满足后续查询条件中的一个即可
{"query": {"bool": {"should": [{"match": {"category": "小米"}},{"match": {"category": "华为"}}]},}}
范围查询
假设现在需要查询出手机品牌为小米或华为,并且价格要大于2000元的所有手机
{"query": {"bool": {"should": [{"match": {"category": "小米"}},{"match": {"category": "华为"}}],"filter": {"range": {"price": {"gt": 2000}}}}}}
全文检索&完全匹配&高亮查询
全文检索
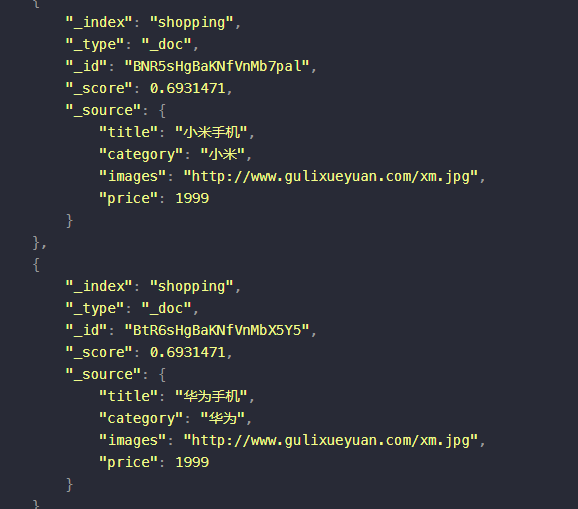
全文检索的功能类似于搜索引擎,会尽可能的关联所有可能存在关联关系的数据
比如搜索时输入category为小华,但是查询出来的结果既有小米也有华为
{"query":{"match":{"category" : "小华"}}}
完全匹配
完全匹配和全文检索则不同,更类似于数据库中的模糊查询
完全匹配使用的字段是match_phrase,示例如下:
{"query":{"match_phrase":{"category" : "为"}}}
{"took": 2,"timed_out": false,"_shards": {"total": 1,"successful": 1,"skipped": 0,"failed": 0},"hits": {"total": {"value": 3,"relation": "eq"},"max_score": 0.6931471,"hits": [{"_index": "shopping","_type": "_doc","_id": "BtR6sHgBaKNfVnMbX5Y5","_score": 0.6931471,"_source": {"title": "华为手机","category": "华为","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}},{"_index": "shopping","_type": "_doc","_id": "B9R6sHgBaKNfVnMbZpZ6","_score": 0.6931471,"_source": {"title": "华为手机","category": "华为","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}},{"_index": "shopping","_type": "_doc","_id": "CdR7sHgBaKNfVnMbsJb9","_score": 0.6931471,"_source": {"title": "华为手机","category": "华为","images": "http://www.gulixueyuan.com/xm.jpg","price": 1999}}]}}
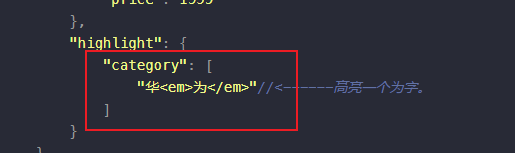
高亮查询
可以使用highlight字段来表示高亮的字段
{"query":{"match_phrase":{"category" : "为"}},"highlight":{"fields":{"category":{}//<----高亮这字段}}}
聚合查询
聚合查询和数据库中的聚合查询操作(group by)类似,可以对存储的数据进行统计分析,比如取数据中的最大值、平均值等等
比如对上述的数据,按照price字段进行分组操作:
{"aggs": { //聚合操作"price_group": { //名称,随意起名"terms": { //分组"field": "price" //分组字段}}}}
返回结果中可能会存在原始数据,但是我们需要的分组后的数据如下所示: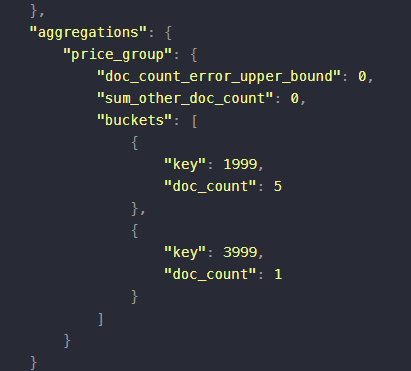
如果我们不想要获取原始数据,可以在请求时的JSON数据中,使用size字段来进行限制
{"aggs":{"price_group":{"terms":{"field":"price"}}},"size":0}
这样,我们的请求结果中,就只有聚合查询后的数据了
如果是想要查询手机价格的平均值,那么在请求的数据中使用avg字段即可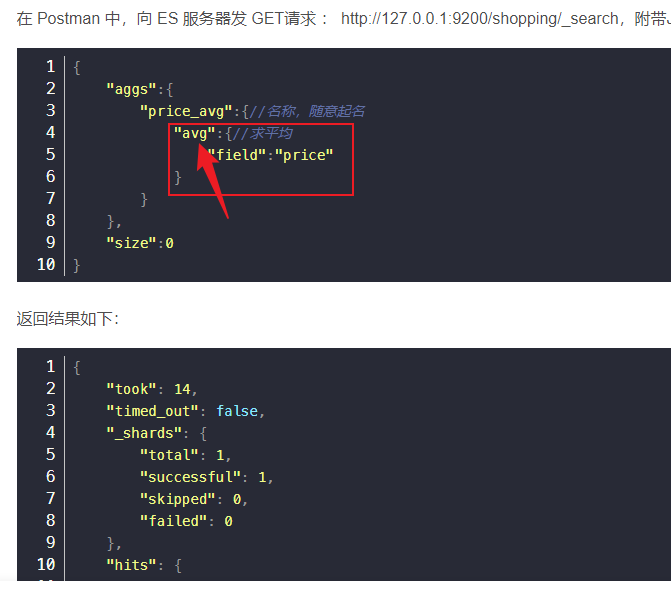
映射关系
有了索引库,其实有了数据库
那么后面就需要创建索引库index的映射了,其类似于数据库中的表结构
创建数据库的时候,我们需要知道字段的名称,长度,约束等等;索引库也同样如此,我们需要这个类型下有哪些字段,每个字段有哪些约束信息,这个关系就叫做映射(mapping)

若有收获,就点个赞吧
0 人点赞
