监督学习
预测房价
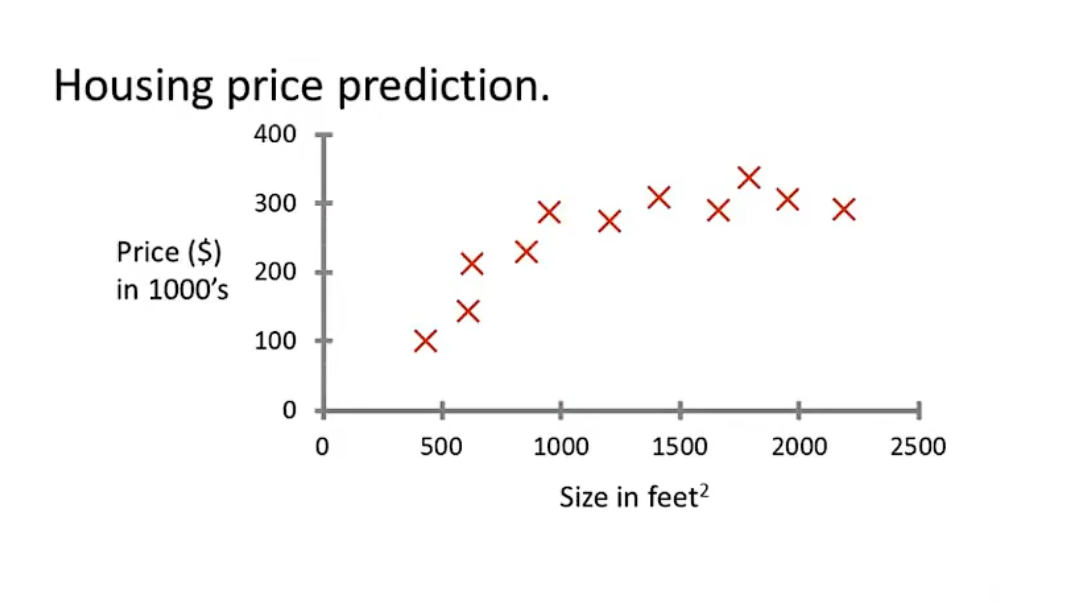
假设根据给定的数据集,我们可以绘制出如上图所示的图 如果现在需要预测750平方的房屋,可以售卖出多少钱的价格,如何使用学习算法来完成这项工作
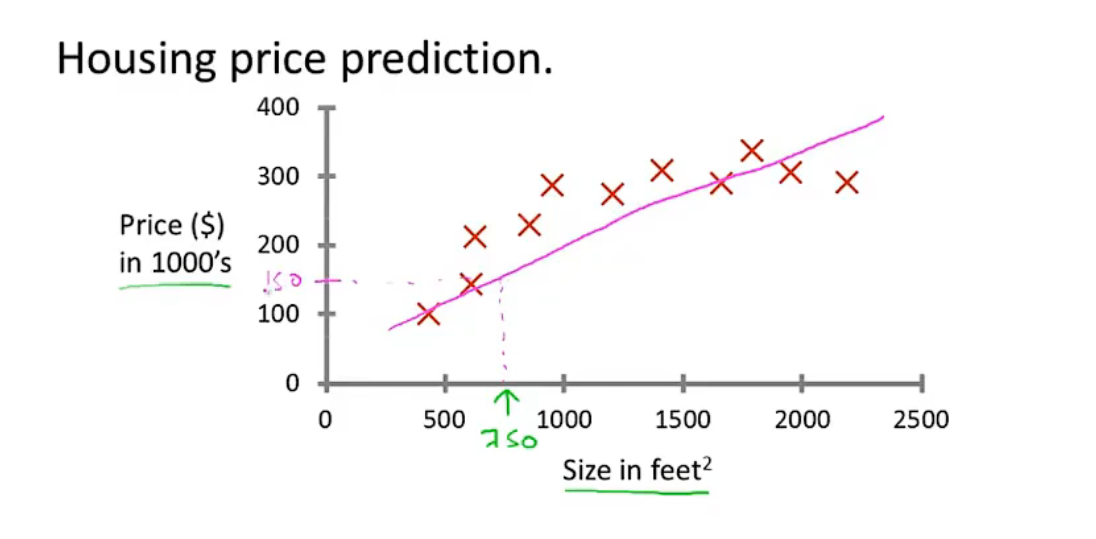
可以选择使用一条直线来对样本数据进行拟合,从而对750平方的房屋售价进行预测
使用直线对数据进行拟合的过程,其实就是在对数据进行一个预测
但并不是所有的样本数据都可以很好地使用直线进行拟合,有时候也需要使用其他的函数(比如二次函数)进行拟合,假如我们使用二次函数进行拟合,那么结果会如下所示: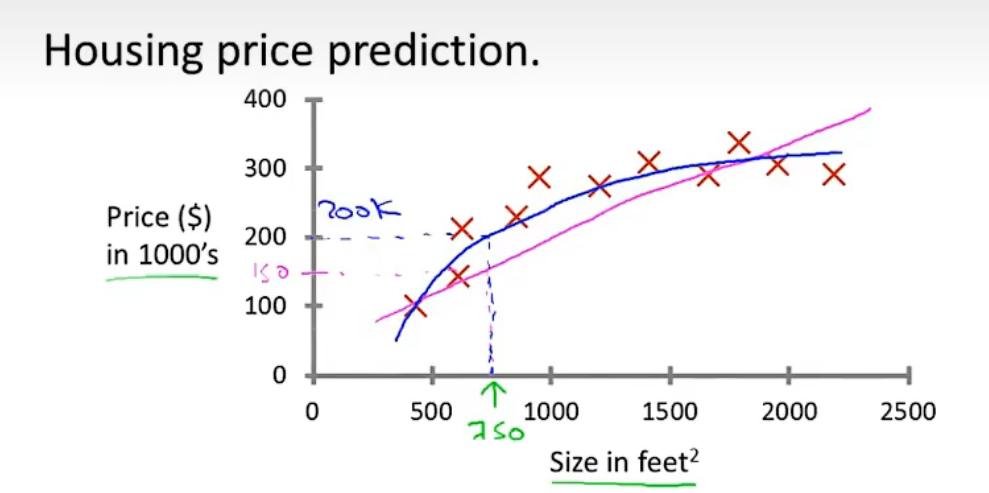
监督学习定义:对于给定的样本数据集,其中包含了所有合适且正确的结果,我们需要对这些数据进行分析,给出一种方案(公式),能够预测出更多我们需要的内容。而对于上述预测房价此类问题,虽然钱财只能四舍五入到分,但是我们一般将房价看作是连续的,属于回归分析问题
肿瘤分析
假设肿瘤是否为恶性仅仅与肿瘤的大小有关,并且将恶性视为1,良性视为0,我们得到如下数据集
假如我们现在需要对某个大小的肿瘤进行分析、预测
很明显,这是对一个离散的值进行预测
但假如我们现在知道,肿瘤的良性与否和人的年龄、肿瘤的大小同时相关
那么,我们实际得到的数据集对应的图,可能为如下所示: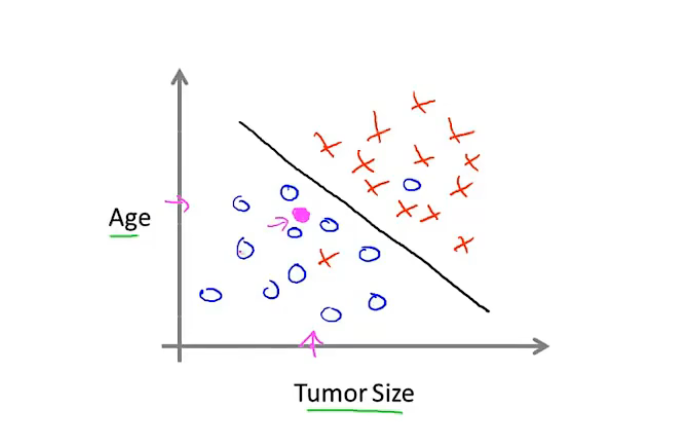
我们可以选择合适的学习算法,将良性和恶性肿瘤的数据集给区分开,并对其他可能的数据进行预测。
无监督学习
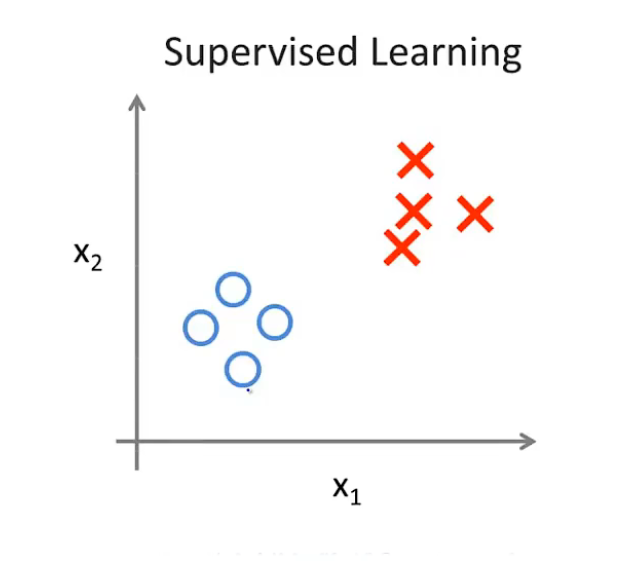
在监督学习中,我们根据数据集,可以得到如上图所示的数据图
使用蓝色圆圈表示良性肿瘤,使用红色叉叉表示恶性肿瘤
换而言之,我们已经知道了数据的标签,也就是分类
而在无监督学习中,我们得到的数据是不带有标签的
对应的数据图可能是下面这个样子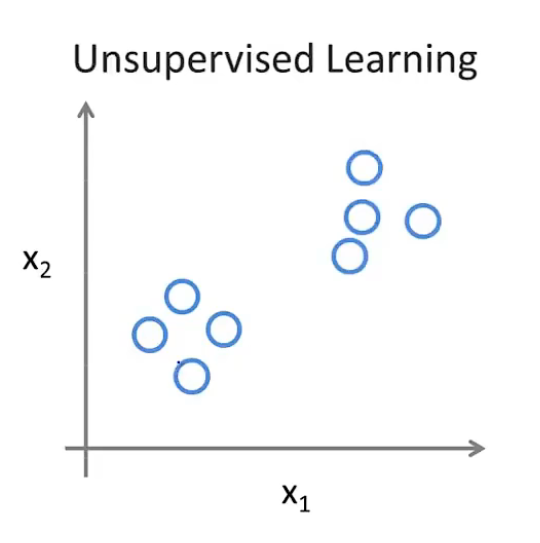
我们目前只有这么一些数据,但是我们需要通过无监督学习方法,对数据集中既没有标签,也没有分类的数据进行分析,并最终得到他们应该被分成的结构
比如对于上面给定的数据,我们可以学习算法,将他们分为下图所示的两簇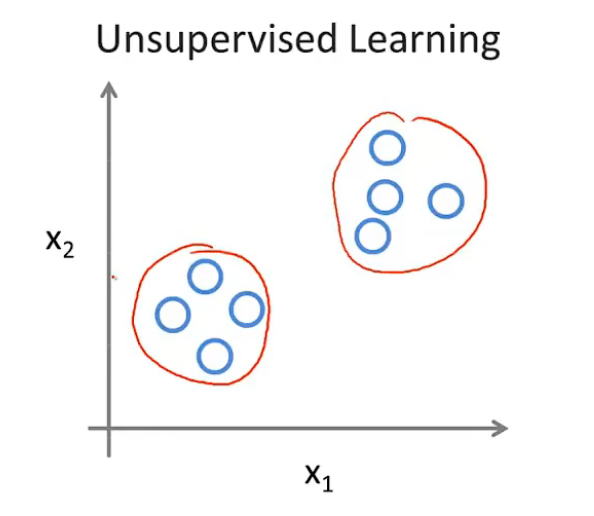
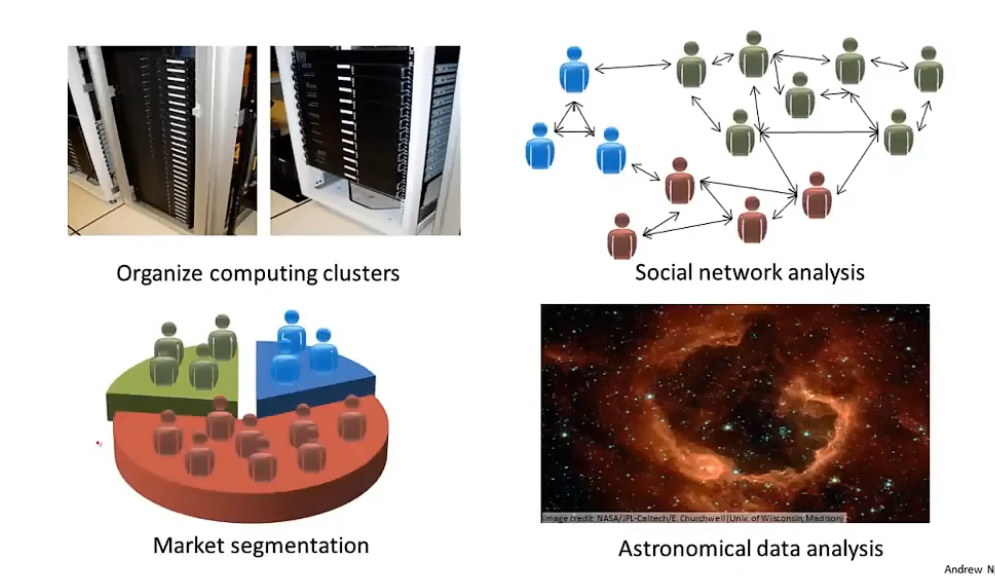
同样,无监督学习算法还可以应用于下图所示的场景
比如可以对社交网络进行分析,根据他们各自是否拥有彼此的联系方式,或是否有相同的兴趣爱好,可以自动的将一个社交网络中的所有用户分成一个个独立的圈子(簇)

若有收获,就点个赞吧
0 人点赞
