
基础应用知识题(15分)
- 关系代数,使用关系代数进行查询
- 相关概念、定义
SQL应用题(40分)
SQL代码相关知识
- DDL:数据的定义(创建表等等)
- DML:数据的查询和更新
- DCL:数据控制(授权和回收权限)
与创建相关的
如何创建索引
CREATE TABLE table_name [col_name data_type][UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC | DESC]
UNIQUE:唯一索引FULLTEXT:全文索引SPATIAL:空间索引
当不显式写出是哪一种索引的时候,那么就是默认的普通索引
在创建表的时候创建索引
创建普通索引
CREATE TABLE book(book_id INT ,book_name VARCHAR(100),authors VARCHAR(100),info VARCHAR(100) ,comment VARCHAR(100),year_publication YEAR,INDEX(year_publication));
创建唯一索引
CREATE TABLE test1(id INT NOT NULL,name varchar(30) NOT NULL,UNIQUE INDEX uk_idx_id(id));
创建组合索引
CREATE TABLE test3(id INT(11) NOT NULL,name CHAR(30) NOT NULL,age INT(11) NOT NULL,info VARCHAR(255),INDEX multi_idx(id,name,age));
在创建表之后,创建索引
使用
alter table创建索引
ALTER TABLE table_nameADD [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name[length],...) [ASC | DESC]
使用
create index创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_nameON table_name (col_name[length],...) [ASC | DESC]

alter table actor add unique index uniq_idx_firstname(first_name);alter table actor add index idx_lastname(last_name);
或
create unique index uniq_idx_firstname on actor(first_name);create index idx_lastname on actor(last_name);
如何创建视图
对视图的理解:
- 视图是一种
虚拟表,本身是不具有任何数据的,占用很少的内存空间- 对视图的创建和删除只会影响视图本身,不会影响到对应的基表
- 但是对视图中的数据进行增加、删除和修改的时候,数据表中的数据会相应地发生变化,反之亦然。
- 向视图提供内容的语句是SELECT语句的时候,视图可以看作是存储起来的SELECT语句
创建视图
完整版
CREATE [OR REPLACE][ALGORITHM = {UNDEFINED | MERGE | TEMPTABLE}]VIEW 视图名称 [(字段列表)]AS 查询语句[WITH [CASCADED|LOCAL] CHECK OPTION]
精简版
CREATE VIEW 视图名称AS 查询语句
创建单表视图
CREATE VIEW empvu80ASSELECT employee_id, last_name, salaryFROM employeesWHERE department_id = 80;
查询视图
SELECT *FROM salvu80;
创建多表联合视图
CREATE VIEW empviewASSELECT employee_id emp_id,last_name NAME,department_nameFROM employees e,departments dWHERE e.department_id = d.department_id;
CREATE VIEW emp_deptASSELECT ename,dnameFROM t_employee LEFT JOIN t_departmentON t_employee.did = t_department.did;
CREATE VIEW dept_sum_vu(name, minsal, maxsal, avgsal)ASSELECT d.department_name, MIN(e.salary), MAX(e.salary),AVG(e.salary)FROM employees e, departments dWHERE e.department_id = d.department_idGROUP BY d.department_name;
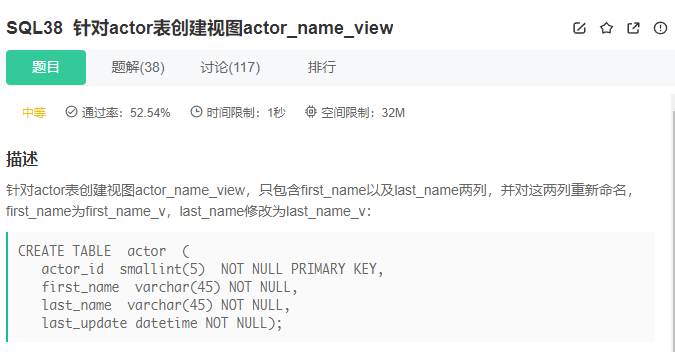
create view actor_name_viewas (selectfirst_name `first_name_v`,last_name `last_name_v`fromactor);
如何创建触发器
触发器是事件来触发某个操作,这个事件包括
INSERT、UPDATE、DELETE等事件 在数据库中数据插入、更新或删除后,需要执行一定的操作,可以使用触发器来实现。创建语法
CREATE TRIGGER 触发器名称{BEFORE|AFTER} {INSERT|UPDATE|DELETE} ON 表名FOR EACH ROW触发器执行的语句块;
举例:在插入一条数据后,在对应的日志表中插入一条操作日志
CREATE TABLE test_trigger (id INT PRIMARY KEY AUTO_INCREMENT,t_note VARCHAR(30));CREATE TABLE test_trigger_log (id INT PRIMARY KEY AUTO_INCREMENT,t_log VARCHAR(30));
DELIMITER //CREATE TRIGGER before_insertBEFORE INSERT ON test_triggerFOR EACH ROWBEGININSERT INTO test_trigger_log (t_log)VALUES('before_insert');END //DELIMITER ;
此时,如果往
test_trigger中插入数据,test_trigger_log中也会自动添加一条数据注意:考试的时候可以不用写重定义分隔符
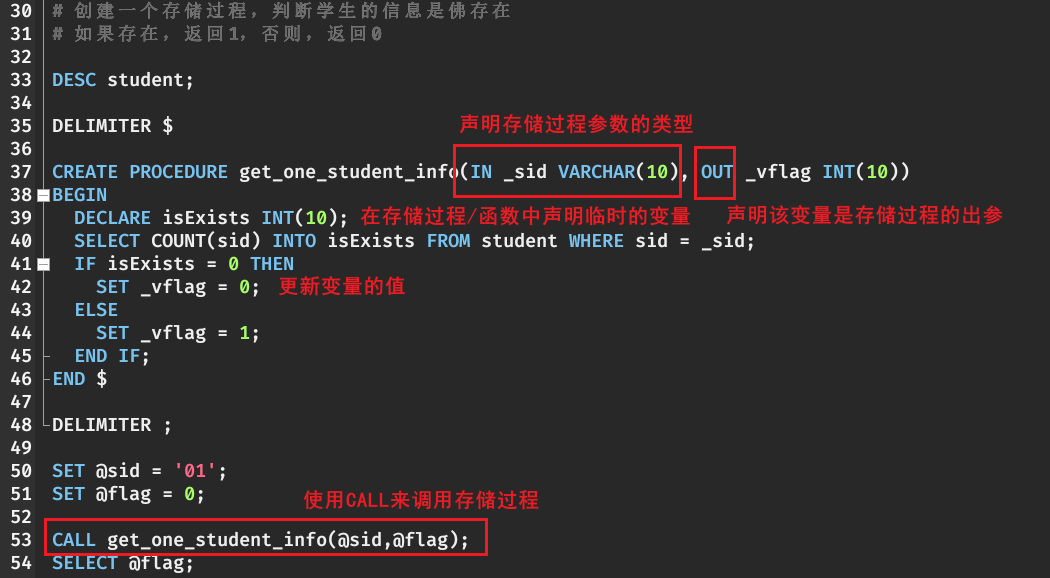
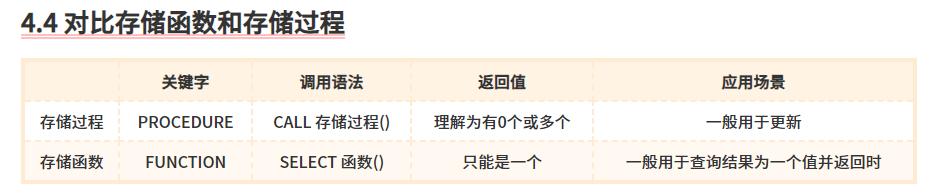
如何创建存储过程和存储函数
存储过程
- 参数类型
- 没有参数
- 仅仅有IN类型的参数
- 仅仅有OUT类型
- 既有IN,又有OUT类型
- 带INOUT(既是入参也可以作为返回值)
创建存储过程 在创建存储过程之前,需要使用
DELIMITER改变语句的结束符
DELIMITER $CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...)[characteristics ...]BEGINsql语句1;sql语句2;END $
示例:
举例1:创建存储过程select_all_data(),查看 emps 表的所有数据
DELIMITER $CREATE PROCEDURE select_all_data()BEGINSELECT * FROM emps;END $DELIMITER ;
举例2:创建存储过程avg_employee_salary(),返回所有员工的平均工资
DELIMITER //CREATE PROCEDURE avg_employee_salary ()BEGINSELECT AVG(salary) AS avg_salary FROM emps;END //DELIMITER ;
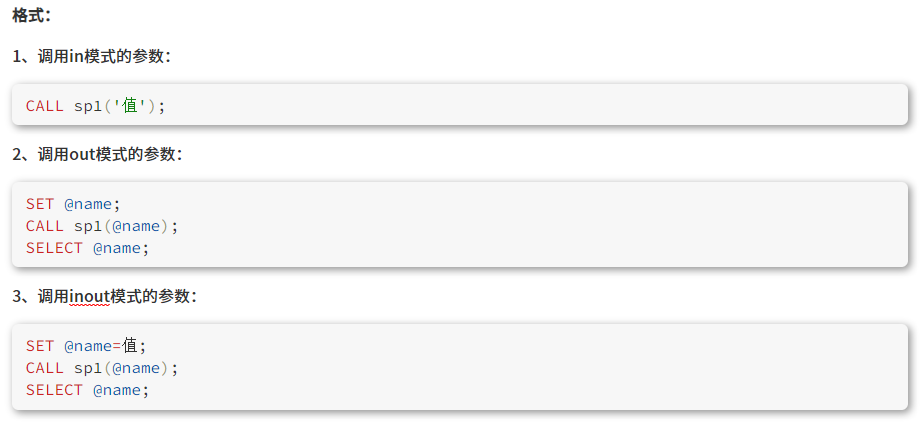
调用存储过程
存储过程有多种调用方法,必须使用CALL进行调用
CALL 存储过程名(实参列表)
存储函数
可以将一些操作封装成一个具体的函数,这样就可以在其他的地方进行函数的调用。 MySQL支持自定义函数,定义完成后,可以像系统预定义的函数一样进行调用
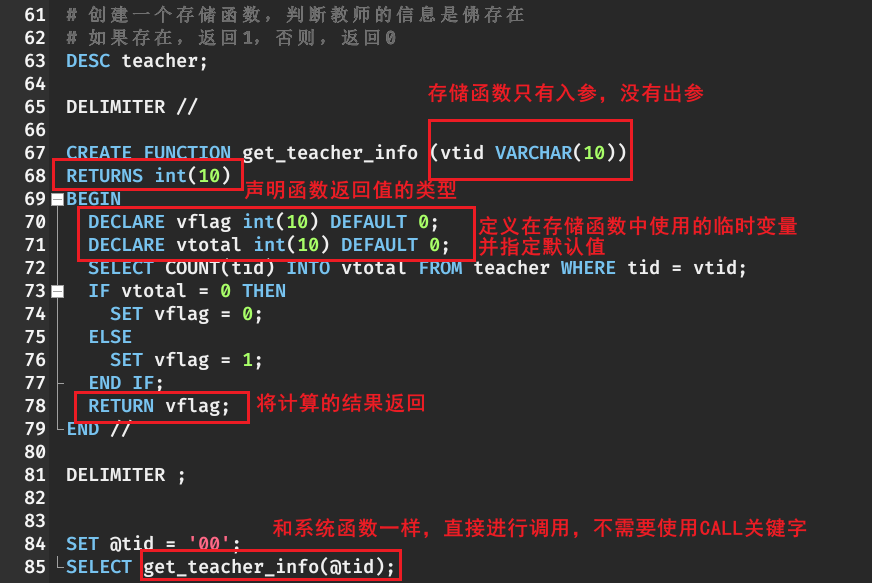
定义函数
CREATE FUNCTION 函数名(参数名 参数类型,...)RETURNS 返回值类型[characteristics ...]BEGIN函数体 #函数体中肯定有 RETURN 语句END
- 与存储过程不同的是,存储函数的参数默认是IN类型,也就是入参
- RETURNS type 语句表示函数返回数据的类型
- 函数体必须包含RETURN语句
调用函数
在MySQL中,存储函数的使用方法与MySQL内部函数的使用方法是一样的。换言之,用户自己定义的存储函数与MySQL内部函数是一个性质的。区别在于,存储函数是用户自己定义的,而内部函数是MySQL的开发者定义的。
SELECT 函数名(实参列表)
使用举例:
创建存储函数,名称为email_by_name(),参数定义为空,该函数查询Abel的email,并返回,数据类型为字符串型。
DELIMITER //CREATE FUNCTION email_by_name()RETURNS VARCHAR(25)DETERMINISTICCONTAINS SQLBEGINRETURN (SELECT email FROM employees WHERE last_name = 'Abel');END //DELIMITER ;
函数的调用:
SELECT email_by_name();
与用户、权限相关的
如何创建用户
create user [IF NOT EXISTS] username identified by password;
username:新建用户的用户名,格式:用户名@'主机名'
比如:
# 用户名密码为:yxr 和 123456create user 'yxr'@'localhost' identified by '123456';
- 用户名为空的时候表示是匿名用户
- 主机名为空的时候表示用户可以通过任何一台主机进行连接

如何修改用户信息
修改用户信息一般使用
ALTER USER或者RENAME USER
ALTER USER:可以用来修改除了用户名之外的任何一个选项RENAME USER:用来进行重命名用户名

修改用户密码

删除用户

角色管理

权限类别:
- Routine级别:可以对存储过程和存储函数操作的权限
- Table级别:对表或者视图赋予的权限
- Database级别:对数据库操作授予的权限
- Global级别:对服务器内所有对象赋予的权限
- Column级别:可以对列赋予的权限
用户授权和回收权限



示例
赋予用户
yxr,control_man角色grant control_man to 'yxr'@'localhost';
授予用于hf@%对数据库sct所有表的SELECT、INSERT、UPDATE和DELETE的权限
grant SELECT,INSERT,UPDATE,DELETE on sct.* to 'hf'@'%';
授予用户hf@%对数据库sct在sc表中score列数据的UPDATE权限,和对数据列sno和cno的查询权限
grant update(score),select(sno,cno) on sct.sc to 'hf'@'%';
授予用户hf@localhost对数据库sct中名为
spGetstNames‘存储过程的执行权限grant execute on procedure sct.spGetstNames to 'hf'@'localhost';
收回用户st@localhost对数据库sct中名为
spGetNames存储过程的执行权限revoke execute on procedure sct.spGetNames from 'hf'@'localhost';
与数据表相关联的
创建和管理数据库
创建数据库
直接创建数据库
CREATE DATABASE 数据库名;
创建数据库并指定字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集;
修改数据库
更新数据库的字符集
alter table 数据库名 character set 字符集; # GBK和utf8
删除数据库
DROP DATABASE 数据库名;
DROP DATABASE IF EXISTS 数据库名;
创建表
直接创建
CREATE TABLE [IF NOT EXISTS] 表名(字段1, 数据类型 [约束条件] [默认值],字段2, 数据类型 [约束条件] [默认值],字段3, 数据类型 [约束条件] [默认值],……[表约束条件]);
利用查询进行创建
CREATE TABLE dept80ASSELECT employee_id, last_name, salary*12 ANNSAL, hire_dateFROM employeesWHERE department_id = 80;
添加一列
alter table 表名 add [column] 字段名 字段类型 [first|after 字段];
ALTER TABLE dept80ADD job_id varchar(15);
修改某列的信息
ALTER TABLE 表名 MODIFY 【COLUMN】 字段名1 字段类型 【DEFAULT 默认值】【FIRST|AFTER 字段名2】;
- 对默认值的修改只会影响之后数据的默认值
- 通过这种方法还可以修改字段的约束
重命名某一列
使用change old_column new_column dataType来修改某一列的名称alter table 表名 change [column] 列名 新列名 新数据类型;
ALTER TABLE dept80CHANGE department_name dept_name varchar(15);
重命名表
方式一:使用
RENAMErename table xxx to xxx;
rename table department to dept;
方式二:使用 alter table
alter table xxx rename [to] xxx;
alter table department rename [to] dept;
删除表(drop)
drop table if exists department,[user];
清空表(truncate)
删除表中所有的数据
释放表的存储空间
truncate table tttttest;
truncate语句不能回归,但是使用delete语句删除时,可以进行回滚。
和流程控制相关的
IF分支结构
IF语句的语法结构 注意:
- 可以没有ELSEIF,取决于具体的逻辑。
- 最后的END IF后面,需要有一个分号作为结尾。
IF expression1 THEN operate1ELSEIF expression2 THEN operate2ELSE operate3END IF;
CASE分支结构
CASE语句的语法结构:
-- 语法结构1:类似于switchCASE expressionWHEN value1 THEN 结果1或语句1WHEN value2 THEN 结果2或语句2ELSE 结果n或语句nEND [case];
-- 语法结构2:类似于多重ifCASEWHEN expression1 THEN operate1WHEN expression2 THEN operate2ELSE 结果n或语句nEND [case];
使用CASE流程控制语句的第二种形式,判断参数
val是否为空、小于0、大于0或等于0。
CASEWHEN val IS NULL THEN SELECT 'the val is NULL';WHEN val < 0 THEN SELECT 'the val less than 0';WHEN val > 0 THEN SELECT 'the val greater than 0';ELSE SELECT 'val is 0';END CASE;
循环结构LOOP
和约束相关的
非空约束
添加非空约束的两种方式:
创建表时
CREATE TABLE student(sid int,sname varchar(20) not null,tel char(11) ,cardid char(18) not null);
修改表时
alter table xxx modify 字段名 字段类型 not null;
删除非空约束的时候就是将
alter最后的not null给删除
唯一约束
创建唯一约束的两种方式:
建表时
create table t_user (name varchar(20) unique,phone varchar(20) unique key,id_card varchar(40),gender char(1),constraint uk_id_card unique(id_card));
建表后 ```plsql — 方式1: alter table xxx add unique key(字段列表);
— 方式2: alter table xxx modify 字段名 字段类型 unique;
<a name="l3NQN"></a>#### 主键约束1. 建表时添加主键约束```plsql-- 列级约束create table t_user(id int(10) primary key,name varchar(20));-- 表级约束create table t_user (id int(10),name varchar(20),gender char(1),constraint pk_id_name primary key(id,name));
- 建表后 ```plsql — alter table xxx add primary key(字段列表);
— 创建复合主键 alter table t_stu add primary key(sid,name); ```
数据建模与数据库设计应用(20分)
- 根据给定的需求分析出有哪些实体
- 分析实体之间存在哪些联系,画出ER图
- 根据ER图和需求,进行逻辑设计

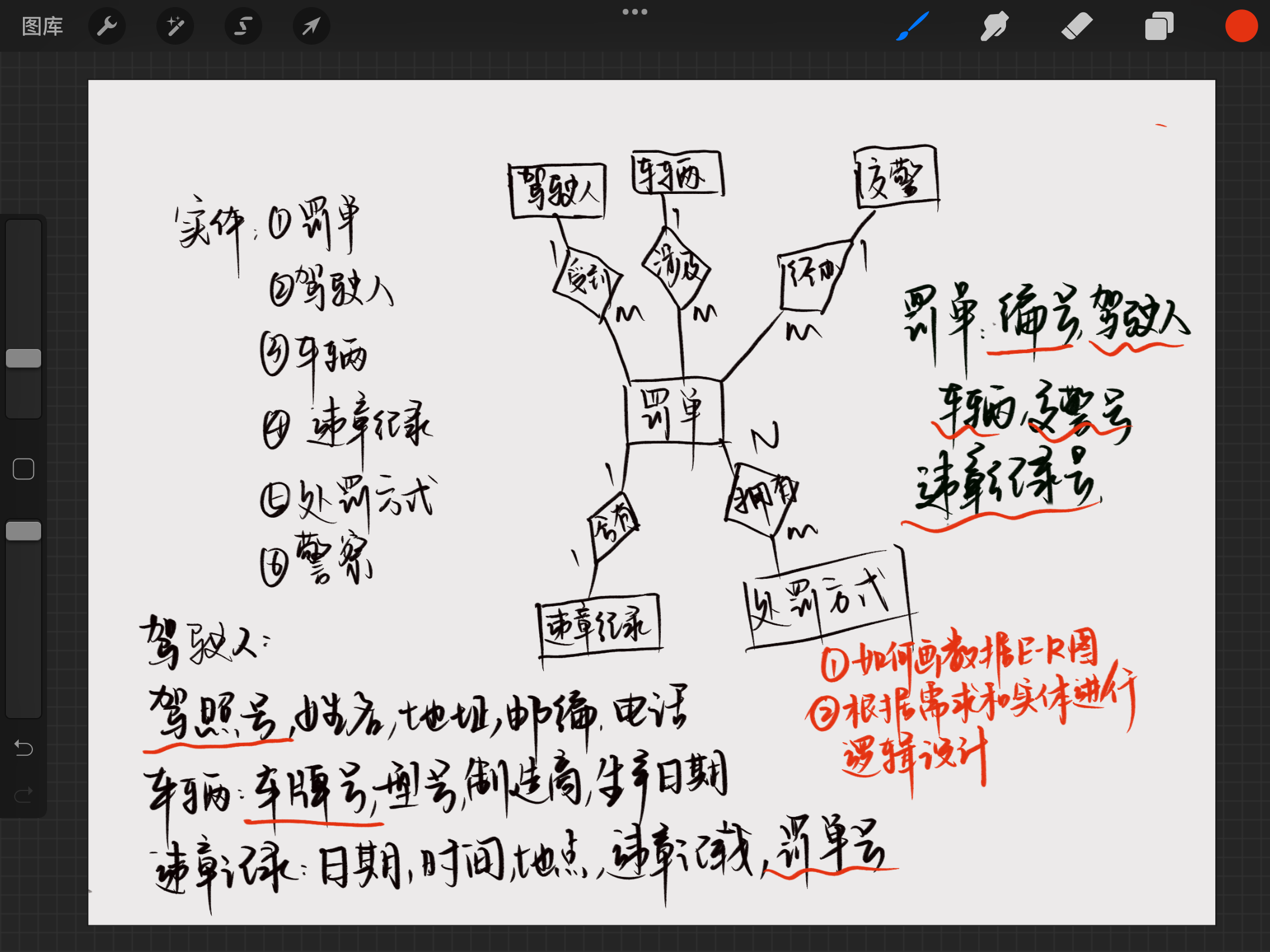

数据库分析题(25分)

并发控制
事务日志分析题
根据事务日志进行
重做和撤销操作,可以分为以下三个阶段
- 分析阶段:根据给定的事务日志记录,分析
redo-set和undo-set- 撤销(undo)阶段:从事务日志尾部扫描,对在
undo-set中的记录,进行撤销操作- 重做(redo)阶段:从事务日志头部扫描,对在
redo-set中的记录,进行重做操作最后各个数据的值,取决于所有操作的叠加

三层封锁协议
共享锁和排它锁:
- 共享锁(S锁):获得S锁,可以对加锁对象进行读操作,但是不能进行写操作
- 排它锁(X锁):获得X锁,可以对加锁对象进行读写操作
共享锁和共享锁是相容的。 排它锁和共享锁、排它锁之间是不相容的。
一级封锁协议:
规定:事务T在修改数据R之前必须对R加上X锁,直到事务结束才释放,事务结束包括正常结束(Commit)和异常回滚(RollBack)
- 一级封锁协议可以防止丢失修改
- 但是不能防止读脏数据,也不能保证可重复读
二级封锁协议
规定:在一级封锁协议的基础上,在读数据R之前必须加上S锁,在读取完之后就释放S锁。
- 二级封锁协议可以防止丢失修改和读“脏”数据
- 但是不能保证可重复读
三级封锁协议
规定:在一级封锁协议的基础上,事务T在读取数据R之前,必须对R加上S锁,直到事务结束才释放
- 三级封锁协议可以防止丢失修改、读脏数据和不可重复读

若有收获,就点个赞吧
0 人点赞
