缓存穿透
根据个人理解,认为应该叫做:穿透缓存
描述:key 对应的数据在数据库中并不存在,因此针对 key 的请求从缓存中获取不到,这样就会导致查询请求的压力都会给到数据库,可能导致数据库的崩溃。条件:
- 应用服务器压力变大
- redis 命中率降低
- 一直查询数据库,使得数据库压力太大而崩溃
解决方案:
- 对空值进行缓存:如果某个 key 查询的数据为空,那么就将这个 key 和空结果 (null)进行缓存,但是缓存的过期时间很短,最长不超过5分钟。
- 设置可以访问的白名单:每次访问的时候,都将数据和白名单中的 id 进行对比,只有在范围内的 id 才能够进行访问,否则进行拦截,不允许访问。
- 采用布隆过滤器:使用布隆过滤器,部署在 redis 的入口处,只有通过了布隆过滤器的 key(换言之,就是存在数据库中的数据),才对其进行查询
- 查询的效率和查询时间都很高
- 但是存在一定的误判的几率(哈希函数所导致)
- 布隆过滤器的位数组也存在删除困难的问题。
- 实时监控:对服务进行事实监控,当出现异常的时候,及时设置黑名单,限制恶意IP的访问
布隆过滤器
大聪明教你学Java | 深入浅出聊布隆过滤器(Bloom Filter) - 掘金
缓存击穿
Redis 缓存雪崩、缓存穿透、缓存击穿、缓存预热 - 掘金
缓存击穿是指某一个热点缓存,在某一个时刻恰好失效了,然后这个时候刚好有大量的并发请求,此时这些请求会同时去查询数据库,给数据库造成巨大的压力,这种情况就被称为缓存击穿。
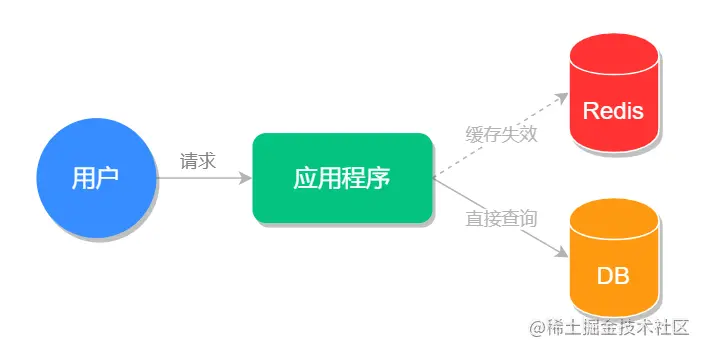
解决方案:
- 提前设置热门数据,并加大这些热门数据 key 的过期时长
- 实时调整:检测热门数据 key 的过期时长,进行实时调整
- 使用锁:
- 在大量用户访问的时候,如果 redis 中有数据,那么直接返回给用户。但如果 redis 中没有对应的数据,那么就去请求数据库。但在请求数据库的时候进行上锁,这样可以防止别的线程同时对数据库进行访问。只有一个线程能访问数据库的时候,数据库的 压力不会过大。当查询到这个数据的时候,就把缓存写到 redis中去,其他没有抢到锁的线程,就让其睡眠几秒,然后再去 redis 中查询数据,此时 redis 中已经有对应的数据,就不会出现同时查询数据库而导致数据库压力过大的问题
缓存雪崩
Redis 缓存雪崩、缓存穿透、缓存击穿、缓存预热 - 掘金定义:缓存雪崩是指在短时间内,redis 中有大量的 key 过期,导致大量的请求,同时对数据库进行查询,从而对数据库造成巨大的压力,严重的情况下可能导致数据库的宕机
- 在大量用户访问的时候,如果 redis 中有数据,那么直接返回给用户。但如果 redis 中没有对应的数据,那么就去请求数据库。但在请求数据库的时候进行上锁,这样可以防止别的线程同时对数据库进行访问。只有一个线程能访问数据库的时候,数据库的 压力不会过大。当查询到这个数据的时候,就把缓存写到 redis中去,其他没有抢到锁的线程,就让其睡眠几秒,然后再去 redis 中查询数据,此时 redis 中已经有对应的数据,就不会出现同时查询数据库而导致数据库压力过大的问题
正常情况下的访问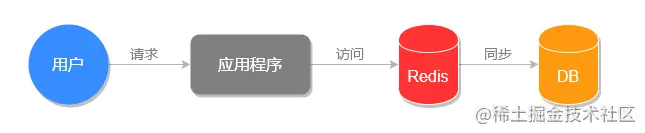
缓存雪崩下的执行过程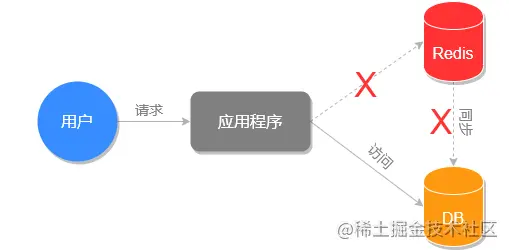
如上图所示,大量缓存失效的时候,会有大量的请求直接绕过 redis 去请求数据库,导致对数据库造成很大的压力
解决方案:
- 加锁排队(减轻数据库查询的压力):
解释:当缓存未查询到的时候,对要请求的 key 进行加锁,同一时间内只允许一个线程去查询数据库,降低数据库的查询压力缺点:由于使用到了锁,会导致效率的降低
- 随机化过期时间(避免同时有大量的 key 在同一时间过期):
解释:在缓存的时候设置随机的过期时间,这样就可以避免在同一时间内有大量的缓存过期。

若有收获,就点个赞吧
0 人点赞
