高并发
高并发:系统运行过程中的一种“短时间内遇到大量操作请求”的情况,比如web系统被集中大量访问收到大量的请求,比如淘宝双十一、京东618等类似的活动。在此情况之下,会导致系统在这段时间内执行大量的操作(对资源的请求,对数据库的访问)
高并发常用的一些指标:响应时间、吞吐量、每秒查询料QPS、并发用户数
响应时间:系统对请求做出响应的时间。比如处理一个HTTP的请求需要600ms的时间,600ms就是系统的响应时间吞吐量:单位时间内处理的请求数量QPS:每秒响应的请求数并发用户数:同时承载正常使用系统功能的用户数量。
高并发并没有明确的规定,单位时间最多能同时处理的请求数是多少。这取决你所设计的系统实际最多能同时处理多少的并发量。
使用缓存
MySQL和Redis是很常见一对儿组合,可以使用Redis作为MySQL的前置缓存,从而为MySQL挡住大部分的查询请求,可以很大程度上缓解MySQL并发请求的压力。
Redis是一种使用内存保存数据的高性能K-V数据库,其高性能主要来自于简单的数据结构和使用内存存储数据,但由于其使用内存存储数据,这也造成了其本身是一种不可靠的存储(内存是易失性存储)
由于Redis本身具有”数据不可靠性”,所以在设计Redis缓存的时候,也必须要考虑Redis的这种数据不可靠性,简单来说:需要兼容Redis丢数据的情况,及时Redis丢失了数据,也不能影响系统的数据准确性。
目前流行的缓存更新策略,使用的多的是:[Read/Write Through模式] 和 [Cache Aside模式]
[Read/Write Through模式]:
- 在查询数据的时候,先去缓存中查询
- 如果命中缓存那么就直接返回Redis中的数据
- 如果没有命中缓存,那么就去数据库中查询数据,并将数据写入到缓存中,然后返回
- 在更新数据的时候,首先去更新数据库,然后再去更新缓存中的数据
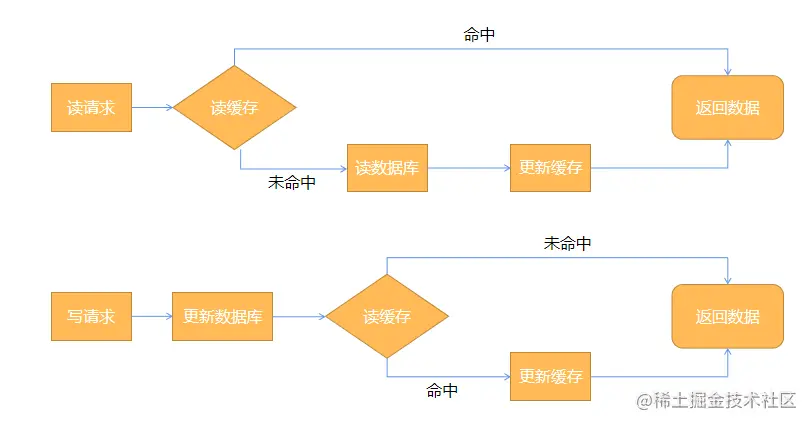
这种处理缓存的方式,也会存在一定脏数据的问题
https://juejin.cn/post/6993488885469118494
比如,对同一条记录,同时产生了一个读请求和一个写请求,这两个请求被分配到两个不同的线程并行执行,读线程尝试读缓存没命中,去数据库读到了订单数据,这时候可能另外一个写线程在处理写请求的过程中,先后更新了数据和缓存,这个时候就有问题了,拿着旧数据的第一个读线程又把缓存更新成了旧数据,脏数据也就产生了。
[Cache Aside模式]:
Cache Aside模式和上面的模式在读方面是完全一致的,唯一的差别就是在更新数据的时候,后者并不是尝试去更新缓存,而是直接将缓存删除。
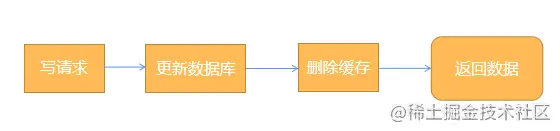
使用这种模式来更新缓存,可以很大程度上降低脏数据产生的概率,但是在高并发的情况下,更容易造成缓存穿透。

若有收获,就点个赞吧
0 人点赞
