CNN卷积神经网络
最近在学习使用Logistics Regression进行猫狗图像分类的问题时,了解到了使用卷积神经网络CNN来进行图像的分类。 在这里还是结合学习过程中解决的两个实际的问题,来对CNN网络进行归纳总结 参考文章如下:
CNN入门+猫狗大战(Dogs vs. Cats)+PyTorch入门_思考的大兵的博客-CSDN博客
卷积神经网络(CNN)详解
pytorch实现简单的ResNet并对MNIST进行分类_Sword丶的博客-CSDN博客
实际运用:猫狗大战
Dogs vs. Cats | Kaggle
猫狗大战是Kaggle竞赛上的一道比赛题目,题目给定一个数据集,设计一种算法来对测试集中的猫狗图片进行判别,即对于给定的一张图片,预测其是猫图还是狗图
训练集: 训练集由标记为cat和dog的猫狗图片组成,各12500张,总共25000张,图片为24位jpg格式,即RGB三通道图像,图片尺寸不一
测试集:测试集由12500张的cat或dog图片组成,未标记,图片也为24位jpg格式,RGB三通道图像,图像尺寸不一
卷积结构
对于此问题,设计的整个卷积神经如下所示:
- 输入层:即输入的图片数据,以矩阵形式的数据存在,如果输入的是一张尺寸为
(H,W)的彩色图像,那么输入层的数据是一个(H*W*3)的矩阵,其中3表示图片的通道数量(由于我们这里输入的是RGB的三通道彩色图像,因此通道数量为3,一般称此输入层为三通道输入层。如果输入的是单通道的图片,那么通道数量为1) - 卷积层:CNN基本运算,由卷积核对输入层的图像进行卷积操作,从而提取图片的图像特征。
- 一个卷积核生成一个
FeatureMap,也就是说,卷积层输出的图片的通道数目等于卷积核的数目。 - 卷积核尺寸为
S*S*C*N,其中C是卷积核的深度,卷积核的深度必须与输入图像的通道数目相等。
- 一个卷积核生成一个
- 池化层:主要用于图像下采样,降低图像的分辨率,减少区域内图像的特征
- 图像下采样:缩小图像,生成对应图像的缩略图
- 图像上采样:放大图片,使得图像可以显示在更高分辨率的显示设备上
- 常用的池化方法:
- MAX_POOLING:最大池化(提取一个区域内最显著的特征)
- AVERAGE_POOLING:平均池化(提取一个区域内的平均特征)
- 全连层:图像经过了多次的卷积和池化以后,通过全连接层完成分类操作。设卷积之后图片的尺寸为:
h*w*c,需要分为n类,那么全连层的作用是将h*w*c的矩阵转换为n*1的矩阵传统的分类方法一般操作为图像预处理,ROI定位,目标定位,特征提取,SVM或BP分类,在基于CNN的分类方法中,可以把卷积和池化操作看作传统方法的图像预处理到特征提取过程,因此CNN的操作结果就是网络自主学习并提取了一个
[h×w×c]大小的特征值,然后在FC层中进行了n目标分类任务。
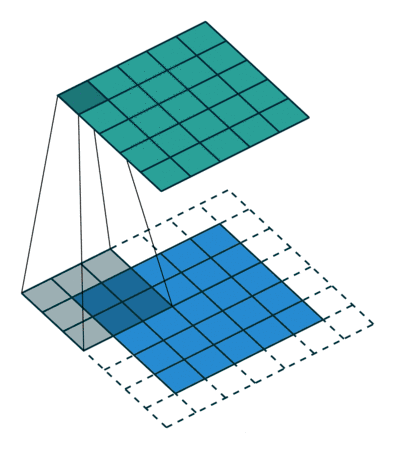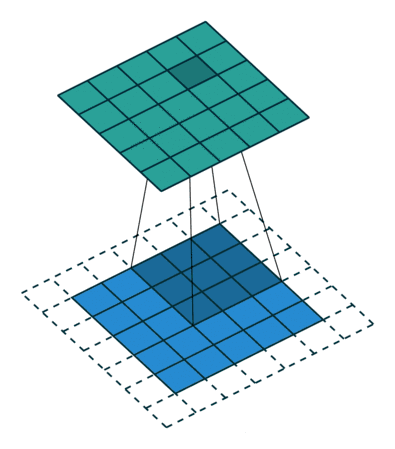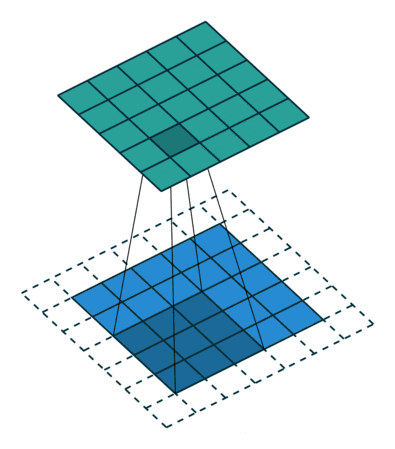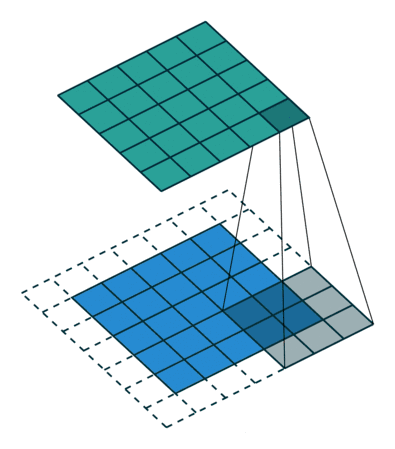
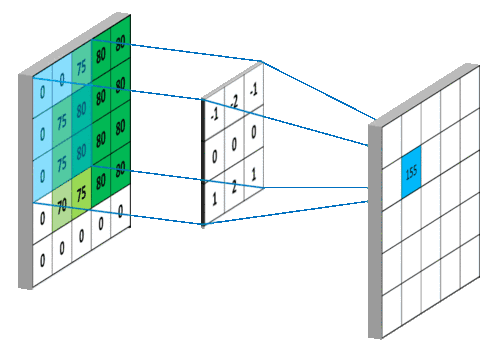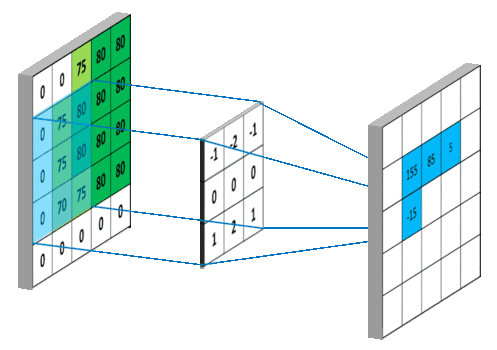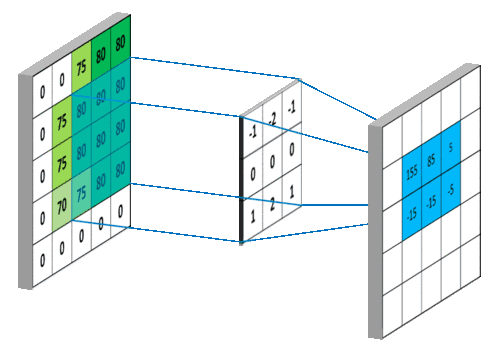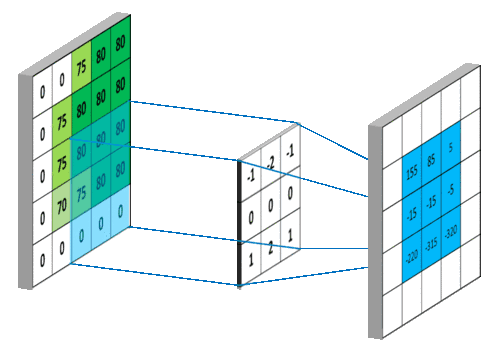
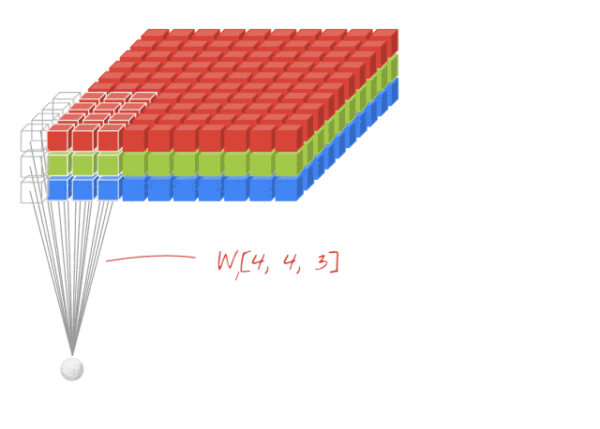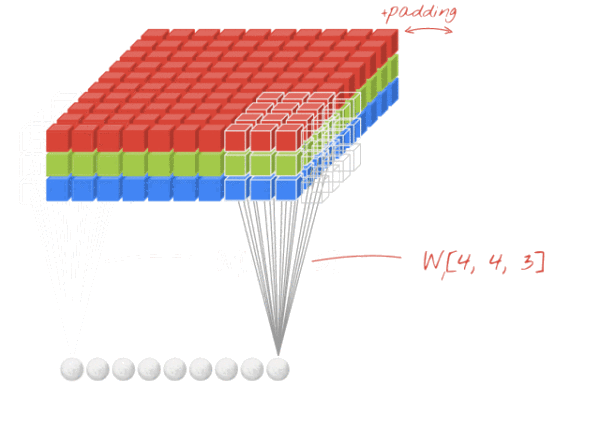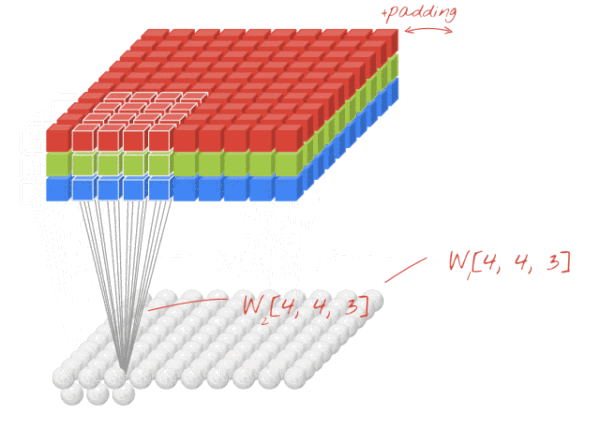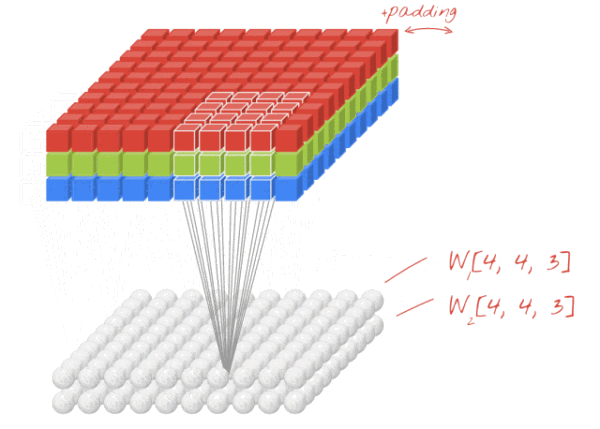
卷积
图像的卷积就是让卷积核在原图像上依次滑动,在两者重叠的区域,将对应位置的像素值与卷积模板值相乘,最后累加得到新图像中的一个像素值,卷积核每滑动一次,就会获得一个新的像素值,当完成了原图像的全部遍历以后,就完成了原图像的一次卷积。
 |
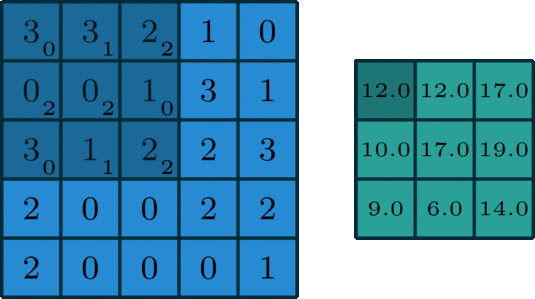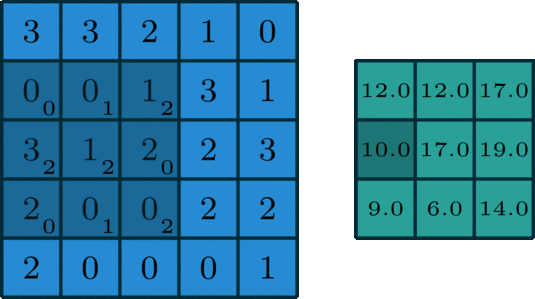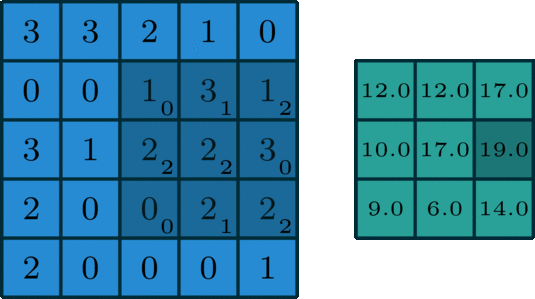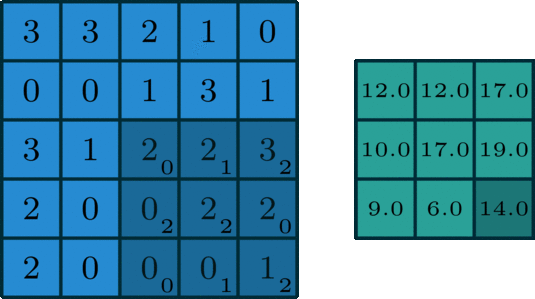 |
 |
|---|---|---|
如果输入的图像是单通道灰色图像,那么图像卷积操作过程中卷积核的深度为1,为
S*S的二维矩阵
在CNN中,由于输入的图像是彩色RGB图像,因此有三个通道。每一个通道图像都需要一个卷积核,分别对各自的通道进行卷积。
设卷积输入层图像为[128×128×12],输出层图像为[128×128×24](假设padding,stride,dilation设置满足需求),卷积核size为5,则卷积核的规模为[5×5×12],卷积核的个数为24。
padding:为了满足原图像的边缘位置在卷积后的图像存在一个对应的位置,需要给原图像补上几条0边stride:卷积过程中卷积核每次移动的步长dilation:卷积核的间隔(相当于给卷积核增加了一个边框)。对于3*3的卷积核来说,如果dilation为1,那么实际卷积过程中卷积核覆盖的区域为5*5
激活函数
激活函数主要引入非线性特征。在卷积过程中,由于所有的运算都是线性运算和线性叠加,因此无论网络多么复杂,输入和输出的关系都是线性的,因此无法拟合非线性的输入输出情况。
常见的激活函数:
- Sigmoid
- Tanh
- ReLU
- 等
池化
选择性的提取区域内的图片特征,一般有最大池化和平均池化,最大池化如下图所示:
全连接
全连接就是将输入的所有节点数据和输出的所有节点数据相连,其结构类似BP神经网络
在CNN中将图像映射成一个N维的向量,通过设置多个全连接,实现从特征到分类的过程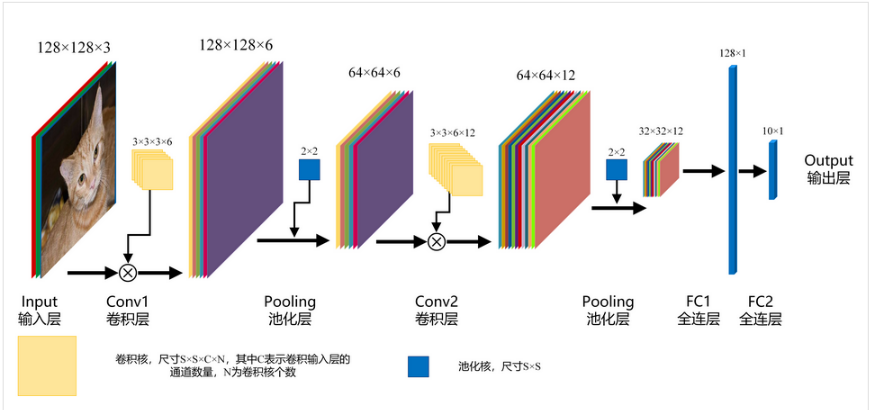
在上图FC1层中,输入为一个[32×32×12]矩阵,输出为一个[128×1]的矩阵,则输出矩阵中的每1个节点都与输入矩阵32×32××12=12288个节点建立了映射关系,总共为12288×128=1572864个映射关系,可见所需的参数非常大。流程介绍
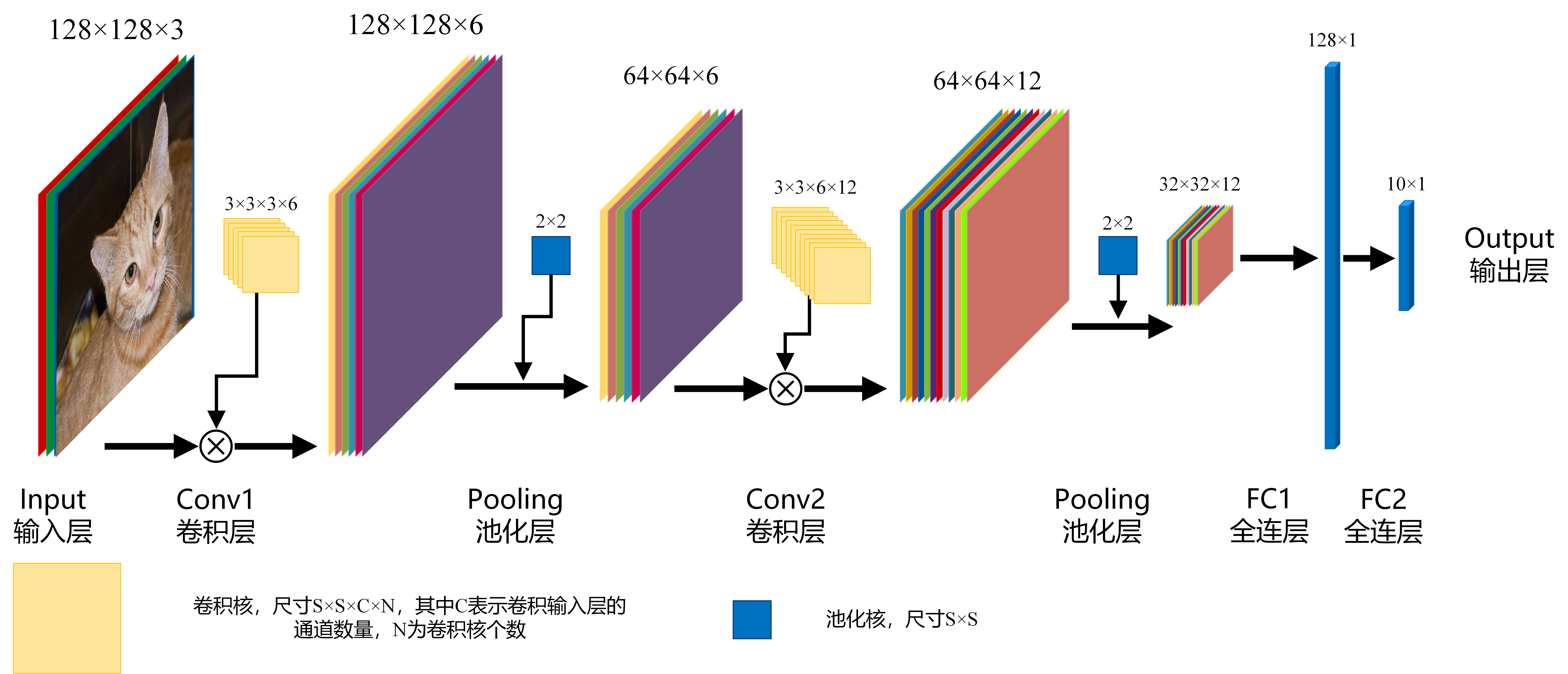

网络搭建
对于输入的图片,我们采用两个卷积层和三个全连接层依次进行处理。
Input:图像的尺寸为:200200(给定的数据集和测试集图像的尺寸不一,因此读取的时候需要统一转换为200200的尺寸大小)Conv1:卷积核的规模为:3*3*3*16,size的大小为3*3,深度为3,数目为16Pooling:第一次池化,size为2,使用MaxPooling,第一次池化后图片的大小变为:100*100Conv2:卷积核的规模为:3*3*16*16,size大小为3*3,深度为16,数目为16Pooling:第二次池化,size为2,使用MaxPooling,第二次池化后的图片大小变为:100*100FC1:第一次全连接,输入节点数目为:50*50*16,输出为节点数目为128的列向量FC2:第二次全连接,输入节点数目为128,输出节点数目为64FC3:第三次全连接,输入节点数目为64,输出节点数目为2(表示是猫或狗两种情况)
实际运用:手写数字识别
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
这里使用到的是MNIST手写数据集
- 训练样本60000个,其中5000个用于验证,55000个用于训练
- 测试样本10000个

数据处理
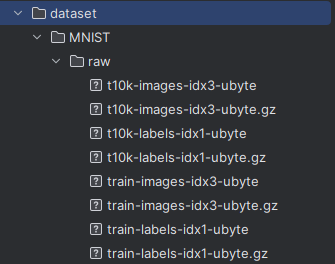
上图为给定的数据集,会发现这些图片并不是以常见的jpg这样的图片格式给定的,因此遇到的一个问题就是如何进行数据的处理。
而这正是TorchVision所发挥作用的地方,提供了对应的api来帮助更方便的对MNIST进行读取,并且可以很方便的对读入的图片进行转换,比如裁剪和标准化
import torchvision as tvimport torchvision.transformsimport torch.utils.databatch_size = 128train_loader = torch.utils.data.DataLoader(tv.datasets.MNIST(root='./dataset/',train=True,download=False,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size,shuffle=True)test_loader = torch.utils.data.DataLoader(tv.datasets.MNIST(root='./dataset/',train=False,download=False,transform=torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size,shuffle=True)
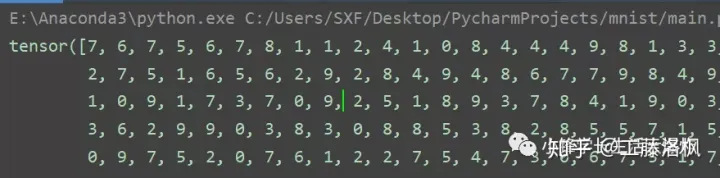
有了Dataloader之后就可以从其中读取数据,如下所示,从test_loader中读取一个批次的测试数据:
examples = enumerate(test_loader)batch_idx, (example_data, example_targets) = next(examples)print(example_targets)print(example_data.shape)

网络搭建
读入的图片是12828的单通道灰度图像
采用两次卷积+池化,并经过两次全连接,最终得到10*1的向量
使用ReLU作为激活函数,并使用两个Dropout层作为正则化的手段
import torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimclass Net(nn.Module):def __init__(self):super(Net, self).__init__()self.conv1 = nn.Conv2d(1, 10, kernel_size=5)self.conv2 = nn.Conv2d(10, 20, kernel_size=5)self.conv2_drop = nn.Dropout2d()self.fc1 = nn.Linear(320, 50)self.fc2 = nn.Linear(50, 10)def forward(self, x):x = F.relu(F.max_pool2d(self.conv1(x), 2))x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))x = x.view(-1, 320)x = F.relu(self.fc1(x))x = F.dropout(x, training=self.training)x = self.fc2(x)return F.log_softmax(x)
使用Adam作为优化器,交叉熵作为损失函数lossF
lr = 1e-4 # 学习速率optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 实例化一个优化器,即调整网络参数,优化方式为adam方法lossF = torch.nn.CrossEntropyLoss() # 交叉熵损失函数epoch_num = 3 # 训练次数
在训练前,我们需要使用自定义好的网络来定义一个变量,为了使用GPU来进行运算,将变量迁移到GPU存储上(model = model.cuda()),并开启训练模式(model.train())
在训练的时候,为了统计过程中的平均损失,需要定义一个变量来统计次数,完整的训练代码如下所示:
from getdata import train_loader, batch_sizefrom torch.autograd import Variablefrom network import Netfrom progress.bar import IncrementalBarimport torchfrom torch.utils.tensorboard import SummaryWritermodel = Net()model = model.cuda()try:model.load_state_dict(torch.load('./model/model.pth'))print('load model success')except:print('load model failed')model.train()lr = 1e-4optimizer = torch.optim.Adam(model.parameters(), lr=lr) # 实例化一个优化器,即调整网络参数,优化方式为adam方法lossF = torch.nn.CrossEntropyLoss()epoch_num = 3model_cp = './model/' # 网络参数保存位置class MyBar(IncrementalBar):def next(self, n=1, epoch=0, idx=0, total=0, loss=0):self.suffix = '(第{}次训练 当前图片索引:{}/{} loss: {})'.format(epoch, idx, total, loss)super().next(n)for e in range(epoch_num):print('\n第{0}次训练:'.format(int(e + 1)))cnt = 0bar = MyBar('训练中', max=len(train_loader))lossT = 0loss_arr = []for img, label in train_loader:optimizer.zero_grad() # 梯度清零img, label = Variable(img).cuda(), Variable(label).cuda()# print(img.shape)out = model(img) # 计算输出结果loss = lossF(out, label.squeeze())lossT += loss.item()# exit(0)loss.backward()optimizer.step() # 执行优化cnt += 1bar.next(epoch=e + 1, idx=cnt * batch_size, total=len(train_loader.dataset), loss=loss.item() / 64)# print('Frame: {0}, loss: {1}'.format(cnt * 64, loss / 64))# print('Frame: {0}, loss: {1}'.format(cnt, loss / 64))# exit(0)average_loss = lossT / len(train_loader.dataset)print('\naverage_loss', average_loss)loss_arr.append(average_loss)torch.save(model.state_dict(), '{0}model.pth'.format(model_cp))
测试训练一次的结果: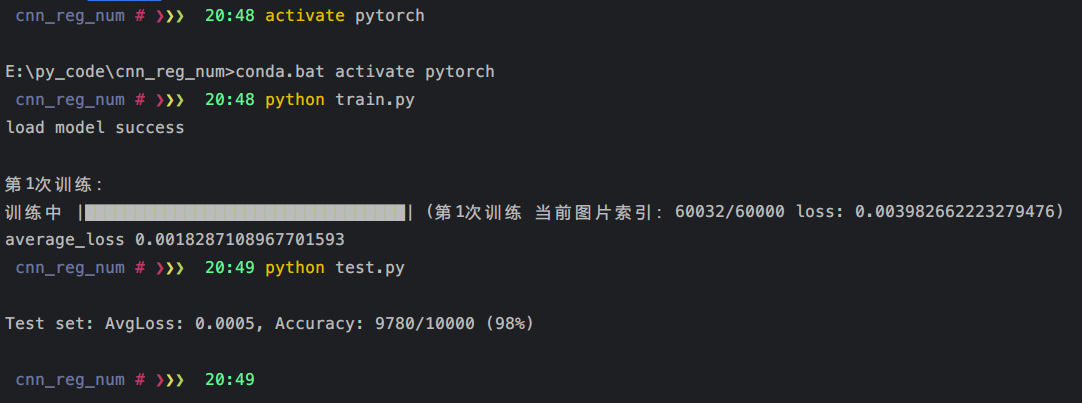
很容易想到我们所训练出来的结果应该是可以保存到磁盘中的,不然每一次的测试都要重新进行训练,这显然是不合理的。
神经网络模块以及优化器可以使用state_dict()保存和加载其内部的状态,从而,如果需要的话,我们可以继续从之前保存的状态中继续训练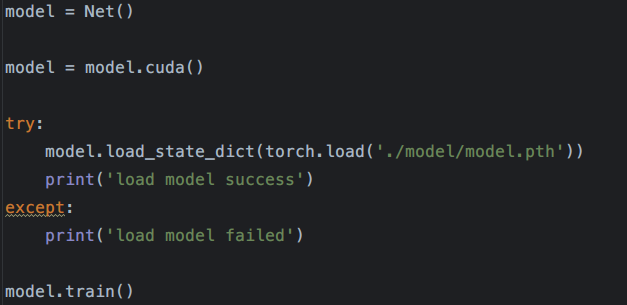
测试代码
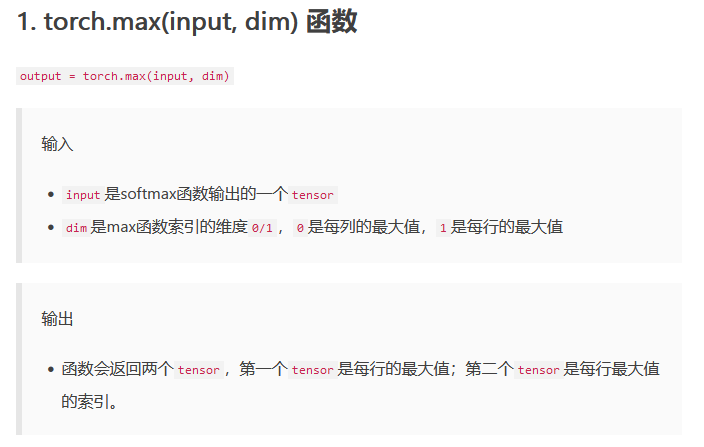
from getdata import test_loaderimport torchfrom network import Netfrom torch.autograd import VariablelossF = torch.nn.CrossEntropyLoss()model = Net()model.load_state_dict(torch.load('./model/model.pth'))model = model.cuda()model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = Variable(data).cuda(), Variable(target).cuda()# print(type(data))# print(target.shape)# print(target)t_out = model(data)# print(t_out.shape)# print(t_out)test_loss += lossF(t_out, target.squeeze())_, pred = torch.max(t_out.data, 1) # pred接收的是最大值的索引# print(pred)correct += pred.eq(target.data.view_as(pred)).sum() # 计算预测正确的个数# returntest_loss /= len(test_loader.dataset)print('\nTest set: AvgLoss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct,len(test_loader.dataset),100. * correct / len(test_loader.dataset)))
优化:使用ResNet进行优化
CNN概念
卷积层
基本的概念在猫狗大战中有讲解
卷积层主要用于提取图像的特征,将图像都通过卷积核提取成一个对应大小和深度的FeatureMap,也就是特征图
池化
主要对图像进行下采样,降低图片的分辨率,提取图片区域内的平均特征或者最显著的特征,进行降维压缩,减少运算量
全连接
在CNN中,全连接层主要起到的就是分类器的作用,将经过多次卷积、池化的图片特征映射到一个n维向量中,最后经过数次全连接,得到最后分类的结果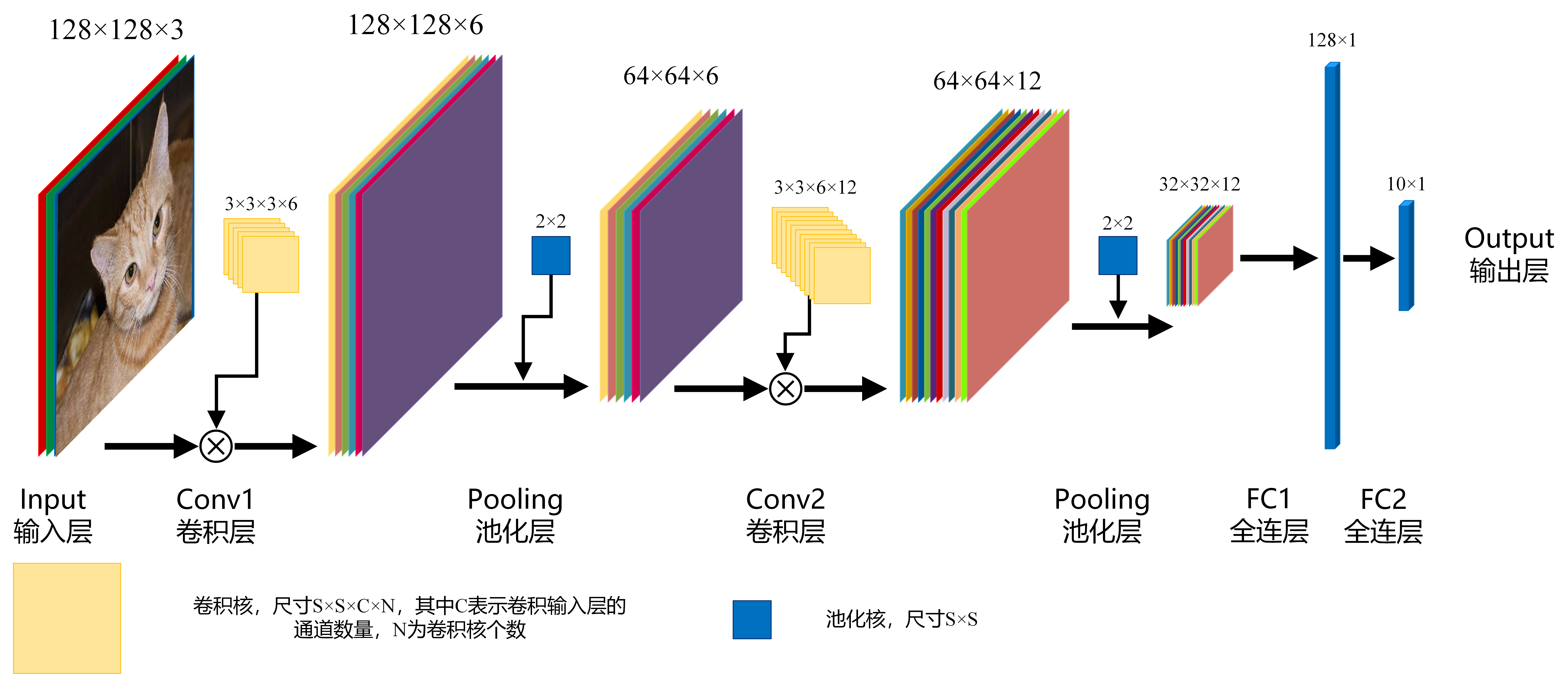

若有收获,就点个赞吧
0 人点赞
