前端和后端
有人觉得前端比较容易,后端比较难
也有人觉得前端比较难,后端比较容易
这就是仁者见仁,智者见智的一件事了,归根到底还是得看自己的兴趣是什么
前端:入门简单,学习的过程中能看到自己做出来的展示界面,容易收获成就感,但是深入学习起来其实也是比较困难的。 后端:入门门槛高,深入起来也更难,总体来讲其实比较枯燥乏味,没有太大的成就感
根本区别:两者负责的内容完全不同 (但就目前来讲,其实前端也得会一点后端内容,而后端也更需要懂一些前端知识)
展示方式
前端主要负责用户可见的界面,比如拿网站开发来说,用户可见的网页上的特效、布局、图片等内容都应该是由前端负责的。简单来说,就是将美工设计好的效果图,使用代码变成浏览器可以运行的网页,并配合后端做网页的数据显示和交互等可视化方面的工作。
后端主要做的就是用户看不见的东西,通常是与前端工程师进行数据交互以及网站数据的保存和读取,相对来说后端更注重业务逻辑,考虑具体业务逻辑的实现、平台的安全和稳定性等等。
所用技术


前端最原生的方式就是三件套:html、css以及javascript,而后衍生出了一系列为了提高开发效率或完善生态的一些工具,比如:jQuery,BootStrap,Node.js,以及现在比较流行的React、Vue。
后端方面,以Java为例,最开始是以SSH(即Spring、Structs、Hibernate)三件套进行开发,而后为了摆脱繁杂冗余的xml配置,进行了框架的一些迭代,出现了SpringMVC、SpringBoot等快速开发的框架。
详细说说后端
在网上有这么一句话:后端其实就是CRUD
这句话:对,但也不对
CRUD:增删改查的缩写
- 增加:Create
- 读取:Retrieve
- 更新:Update
- 删除:Delete
其实后端确实主要是跟数据打交道,而数据往往存储在一些数据库中,(无论是关系型数据库还是非关系型数据库),所以CRUD是必不可少的操作。但是不要瞧不起会CRUD的程序员,因为做好这些其实也没那么简单。在项目足够大的时候,如何保证在5、6张表甚至更多的数据表之间做好这些,其实也不容易。
但除了这些以外,还要考虑更多的东西,最经典就比如:用户访问量过多导致的高并发问题、自动化部署相关的问题等等。
不妨来看看下面的这个视频,从而更多的了解上面所说的含义
点击查看【bilibili】
前后端交互逻辑
为什么前后端分离
在很久之前,其实是比较多的是前后端不分离的模式,后端程序员一起负责网页和后端逻辑的实现
而目前前后端分离的架构更为常见,个人觉得最主要的原因就在于:解耦
解耦这个词,其实大家应该并不陌生,我们在优化代码的过程中,其实主要就是为了降低代码之间的耦合度,充分解耦,这样可以使我们的代码更加优雅,项目后续也更加容易维护
#include<iostream>using namespace std;int main() {int a = 10,b = 20;int c = 10,d = 30;int x = 20,y = 20;cout << a + b << endl; //注意cout << c + d << endl; //注意cout << x + y << endl; //注意return 0;}// 优化后#include<iostream>using namespace std;int plus(int x, int y) {return x + y;}int main() {int a = 10,b = 20;int c = 10,d = 30;int x = 20,y = 20;cout << plus(a,b) << endl; //注意cout << plus(c,d) << endl; //注意cout << plus(x,y) << endl; //注意return 0;}
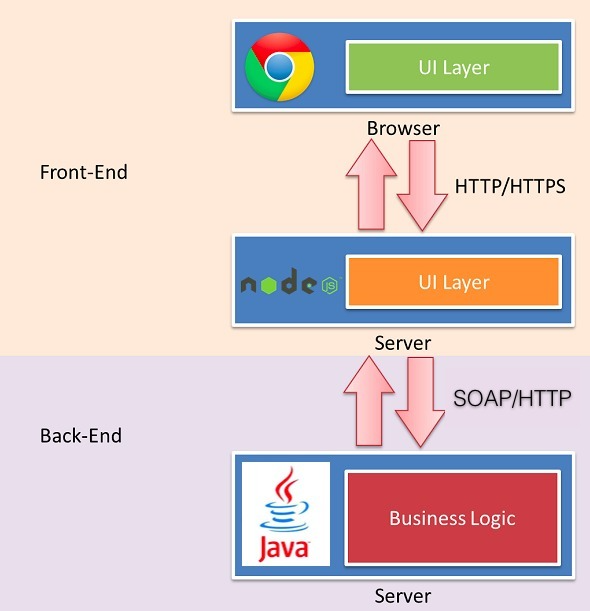
交互逻辑
主要分为以下几个步骤:
- 后端运行起程序,进行http监听,
- 前端处理用户操作,发起异步ajax,对后端程序进行http请求
- 后端收到请求后,进行相关逻辑操作,读取数据库中的数据
- 将读取到的数据封装成JSON对象,再以http数据包的形式返回给前端
- 前端将收到的数据进行处理,再渲染到前端页面上
计算机网络相关知识
http:相关概念是计算机网络相关的知识 ps:计算机网络很重要
常见的请求头
| Content-Type | 标识请求中数据的类型 | Content-Type: application/json |
|---|---|---|
| Authorization | HTTP授权的授权证书类型 | |
| Cache-Control | 指定请求和响应遵守的缓存机制 | |
| Accept-Charset | 浏览器可以接受的字符编码集 | Accept-Charset: utf-8 |
常见的请求方式
- get
- post
- delete
- put
- patch(允许客户端查看服务器的性能)
- options(对PUT方法的补充)
常见的http状态码
| 401 | Unauthorized | 请求需要用户的身份认证 |
|---|---|---|
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 无法在服务器上找到对应资源 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 502 | Bad Gateway | 充当网关或代理的服务器,从远端服务器接收到了一个无效的请求 |
Cookie,Session,Token
一文彻底搞懂Cookie、Session、Token到底是什么 - 掘金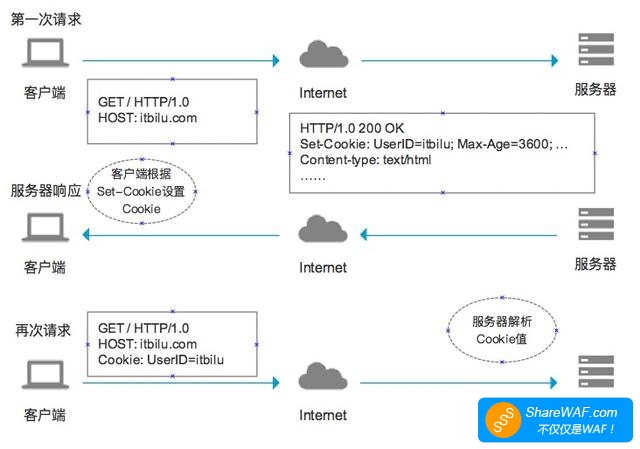
在上文中我们提到,前后端交互的过程中,其实是基于http协议的
而http协议其实是无状态的
也就是说,如果不做处理,那么对于每一次http请求,服务端是不知道这个请求是由谁所发起的
而实际上,我们在具体的业务操作中一定涉及到权限的控制,也就是需要知道请求是由哪位用户所发起的,因此,Cookie、Session、Token这三兄弟就顺势出场了。
Cookie
- 在浏览器客户端第一次向服务端发起请求之后,服务端在处理的过程中,可以将
key-value类型的**Cookie**数据保存在http响应报文的头部中的Set-Cookie字段中。 - 浏览器看到有
Set-Cookie字段以后就知道这是服务端发送过来的身份标识,于是就保存起来,并且在以后的每次请求中就会自动将此key=value的数据放到Cookie字段中发送给服务端。 此后,服务端在接收到客户端发送的请求的时候,就可以根据
Cookie字段中有值,来识别出用户的身份并提供对应的服务。Session
那Cookie其实已经能帮助我们的服务端来识别出请求的用户是谁

但是Cookie是存放在浏览器中,也就是我们的客户端中,并且由于需要标识请求的用户,因此存放的数据中一般都会有一些敏感数据,所以Cookie其实是存在安全隐患的,因此这就需要我们的二哥Session出场了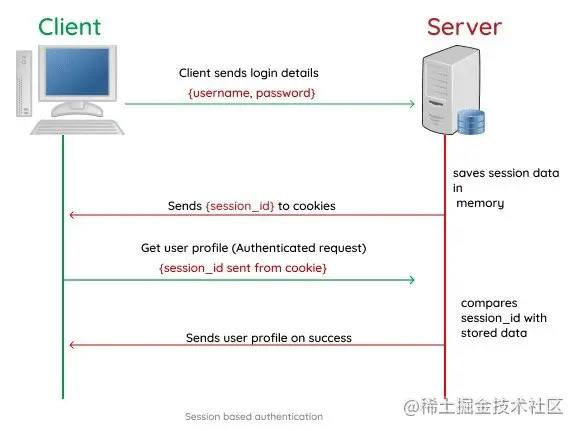
在客户端和服务端一次会话的过程中,重要的信息都存放在Session中,浏览器中只存放SessionId,而一个SessionId对应一次会话请求。
由于之后每次请求都需要带上SessionId,因此客户端保存Session的方式则是通过Cookie的方式来进行存储
Token
使用Session之后,我们的客户端中保存的就只有对应会话的
sessionId,而不会保存对应用户的一些敏感信息,这样保证了一定的安全性。
但由于Session的具体内容其实是保存在服务端中,因此会存在以下两个问题在不对session持久化的情况下,如果服务端出现了宕机的情况,那么所有的session都会失效。
- 如果服务端是分布式的,多台机器之间是无法共享Session的,那么就涉及到分布式session共享的问题。
因此,在以上问题的前提下,我们的大哥token就出场了。
- 客户端发起请求,服务端拿到用户的信息之后,使用一定的方法进行加密(比如base64Url)
- 将加密后的数据传递给客户端进行保存。
- 之后,客户端在每次用户请求的时候都会带上这一段信息
- 服务端拿到这一段信息后,进行相应的解密就能知道对应的用户是谁了,最典型的就是JWT(Json Web Token)
由于服务端实际上是不保存Token具体值的,因此当后端系统有多台的时候,不会涉及到共享数据的问题。
以JWT举例来看,构成分为
- 头部(Header):主要指定token的类型以及加密使用的算法
- 载荷(Payload):存放token中的有效信息,比如签发人,签发时间,过期时间等等
签证(Signature):对两部分数据进行签名,防止token被恶意篡改
浏览器跨域
浏览器跨域问题是前后端分离架构中很容易遇到的一个问题
比如,当我们在本地的8080端口启动了一个后端服务,在前端的3000端口启动了一个前端vue项目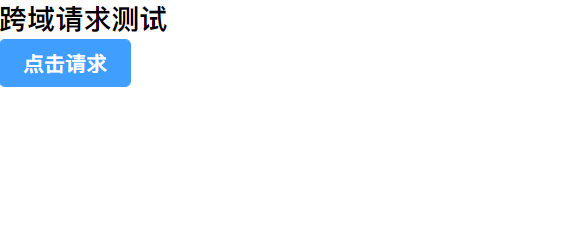
当我们点击按钮,对后端接口发起请求的时候,会发现没有任何反应,并且浏览器控制台会报以下错误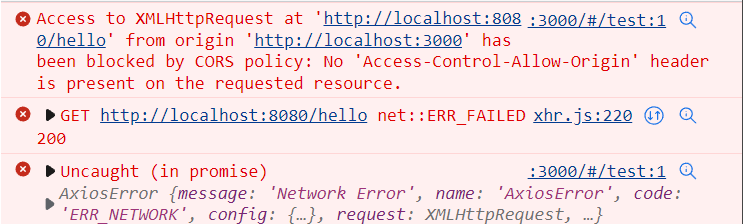
这其实就是遇到了跨域问题。
跨域问题,实际是由浏览器的同源策略导致的,是浏览器为了保证安全,而对JavaScript脚本施加的一种限制
同源是指:同协议,同域名,同端口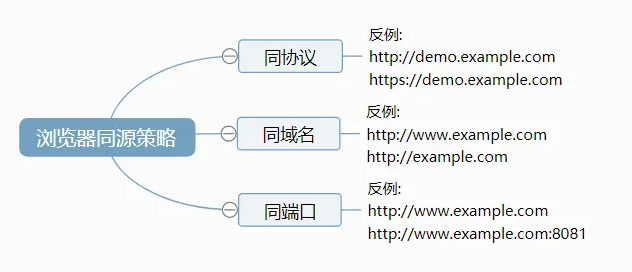
浏览器同源策略中,出现跨域请求时,请求会发到跨域的服务器,并且会服务器会返回数据,只不过浏览器”拒收”返回的数据,因此造成无法获取正常响应数据的结果如何解决浏览器跨域问题
加一层:代理
跨域的根本问题是浏览器的同源策略,因此我们可以在浏览器和服务端之间增加一层:A层
将网络请求的操作放在这个A层中,从而避开浏览器同源策略的限制
在前端Vue项目中,最常见的A层就是**Node.js**
proxy: {'/api/back/v1': {target: 'http://localhost:8080',changeOrigin: true,rewrite: (path) => path.replace(/^\/api\/back\/v1/, ''),},},
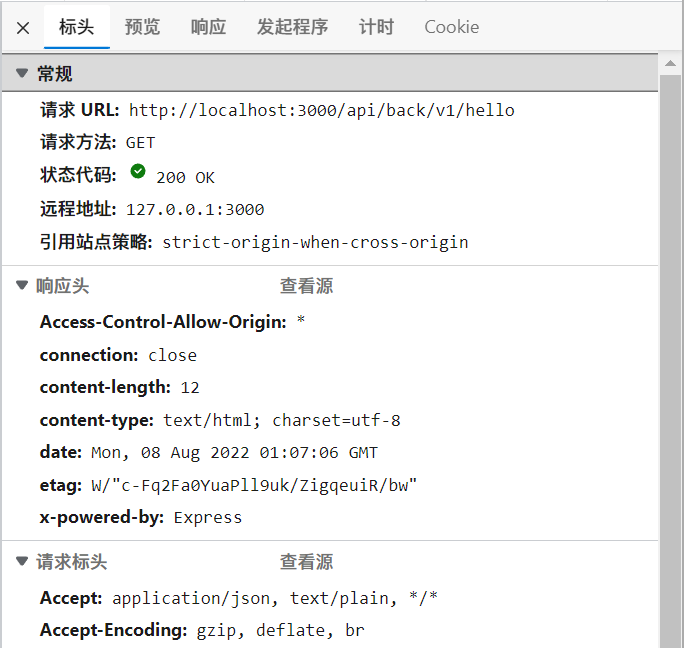
可以看到我们请求的是这个地址,但是实际node.js会帮我们请求后端上的接口
从而避开了同源策略,获取到我们需要的数据
- 后端允许浏览器跨域
HTTP学习——跨域资源共享(CORS)_Hoorus的博客-CSDN博客
后端允许浏览器跨域,主要用到的就是跨域资源共享(CORS)
通过设置一些HTTP头的方式,允许浏览器请求跨域的资源
app.all("*", (req, res, next) => {res.header("Access-Control-Allow-Origin", "*");res.header("Access-Control-Allow-Headers", "Content-Type");res.header("Access-Control-Allow-Methods", "*");res.header("Content-Type", "application/json;charset=utf-8");next();});
再次请求,发现已经可以成功获取到数据
为什么选择Java
其实目前,有很多语言都可以用来做后端开发,而不单单是Java语言
比如Golang,或者基于Node.js的Express方案、Nest.js方案,或者C#的.NET方案,Python的Flask方案,甚至于Ruby的Rails方案。
各个语言都有一些成熟的框架、方案来进行后端的开始,这也从一方面说明,各个语言之间虽然语法有差异,但是思想上是不变化的。
所以不必花太多精力在抉择语言之上,选择一门适合自己的语言即可
那,为什么我们现在要学Java?
很大的一部分原因就是,我们学校的课程使用的Java
除此之外,Java是一门很规范的语言,并且流行时间极其长,目前已经有很大的开源社区和框架,因此现在网上有很多成熟、稳定Java的框架可以供你使用,并且在你使用的过程中如果遇到了问题,很容易就在网上找到别人的解决方案。并且上手了Java后台开发后,上手其他语言会变得更加容易。
但Java出现时间最长,也意味着他自身也存在一些问题:
- 发展时间很长,需要学习的东西很多
- 由于Java语言的特性:基于JVM虚拟机,所以很消耗内存,并且启动时间过长
Java服务端分层模型(简化)

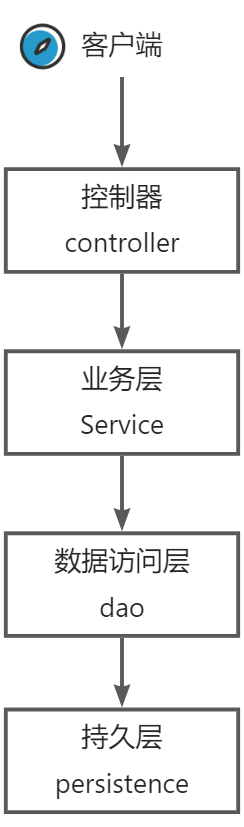
结束
🎉恭喜你看到了这个地方!
👍基础前置知识大概就这么多了,如果你是初学者,在开始后面的学习之前,请确保下面的要求你已经准备好~
- 电脑上已经配置好Java的环境,并且已安装IDEA软件
- 电脑上有MySQL数据库环境
- 一颗乐观的心和良好的心情
检测电脑是否已经配置好Java环境
在cmd或其他命令行中输入:java -version
如果出现下图所示信息,则证明已经配置好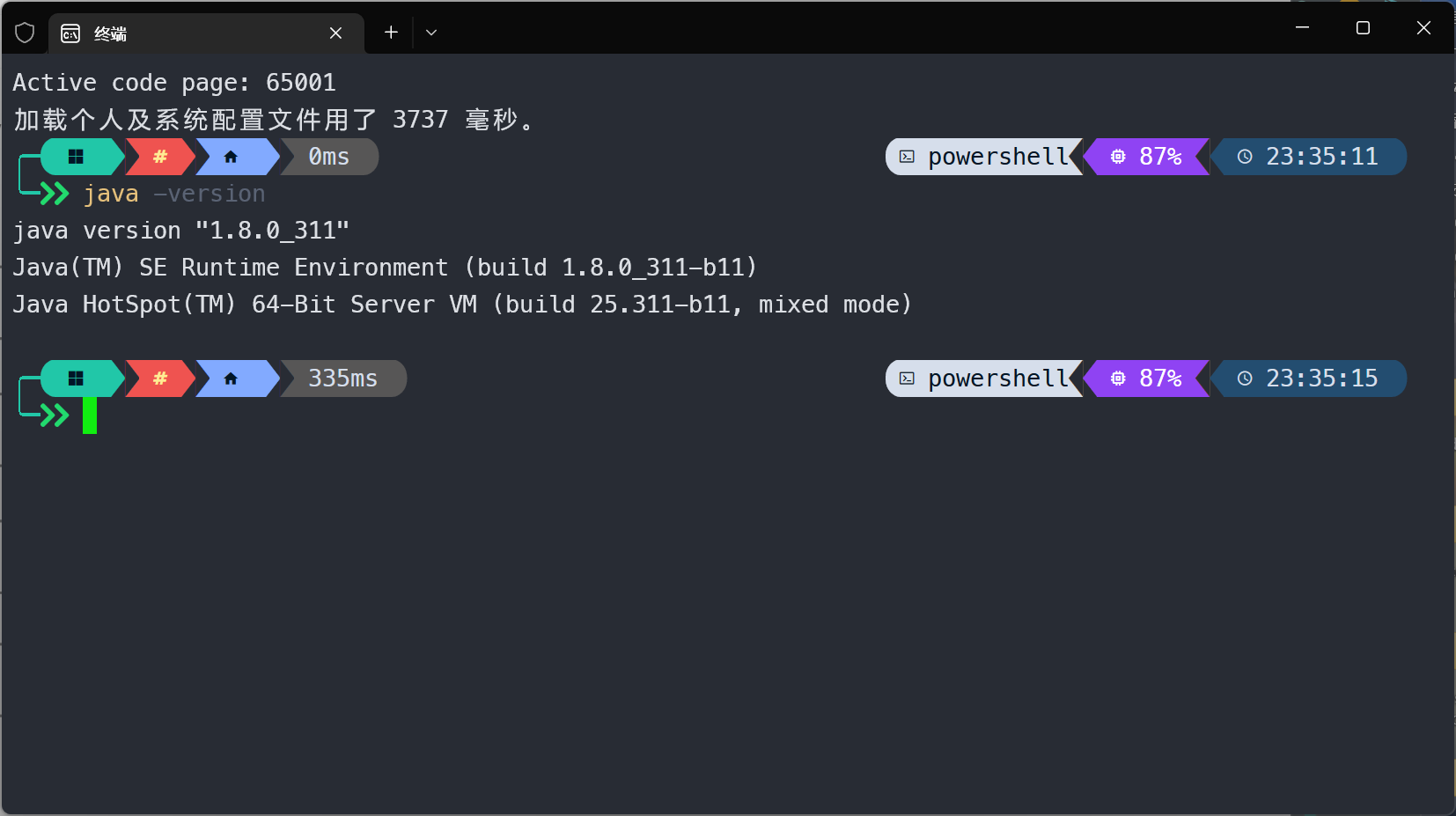
IDEA软件的安装

MySQL数据库环境
推荐使用小皮面板,开箱即用,无需复杂的操作

若有收获,就点个赞吧
0 人点赞
