神经网络工具箱nn
手动实现一些深度学习的模型,需要编写的代码量很大。在这种情况下,torch.nn便应运而生。
这是专门为深度学习设计的模块,核心的数据结构是Module
- 既可以表示神经网络中的某一层
- 也可以表示一个包含很多层的神经网络
在实际编写神经网络的时候,一般都是继承nn.Module,然后再编写自己的网络
- 自定义神经网络
Net必须要继承nn.Module,并在构造函数中调用nn.Module的构造函数 - 在构造函数
__init__中必须定义自己可学习的参数 forward函数实现前向传播过程,其输入可以看作是一个或者多个Variable- 不用编写反向传播函数,
nn.Module能够利用autograd自动实现反向传播 - 可以将
layer视为数学概念中的函数,通过调用layer(input)就可以得到对应的输出结果(虽然在调用函数的时候,主要的调用的是layer.forward(x),但是另外还对钩子做了处理。所以在实际使用中应要尽量使用layer(x),而不是layer.forward(x)) 输入的时候对输入的形状都有假设:输入的并不是单个数据,而是
batch_size个数据。因此如果要想输入单个数据(比如测试的时候),必须先对数据升高一个维度,也就是调用unsqueeze(0)函数将数据伪装成batch_size=1的batch常用的神经网络层
图像相关
图像相关的神经网络层主要包括:
卷积层(Conv)
- 池化层(Pool)
这些层在实际使用中又可以分为一维、二维和三维,池化方式又可以分为平均池化(AvgPool)、最大值池化(MaxPool)和自适应池化(AdaptiveAvgPool)
示例如下:
假设我们现在想要将一张三通道的RGB图像转换为单通道灰度图像,然后对图像进行锐化操作
from PIL import Imagefrom torchvision.transforms import ToTensor, ToPILImage,Grayscaleimport torch as tfrom torch.autograd import Variable as Vfrom torch import nnimg = Image.open('imgs/icon.jpg') # 打开图片to_tensor = ToTensor() # 将图片转换为tensor的函数to_pil = ToPILImage() # 将tensor转换为实际的图片gray_scale = Grayscale(num_output_channels=1) # RGB三通道图像转单通道灰度图像pool = nn.AvgPool2d(2,2) # 平均池化层img


(左边是灰度处理后的图片,右边是原始图片)
img = gray_scale(img) # 将图像转换为单通道input_data = to_tensor(img).unsqueeze(0) # 转换为tensorkernel = t.ones(3,3) / -9 # 定义锐化卷积核kernel[1][1] = 1conv = nn.Conv2d(1,1,(3,3),1,bias=False) # 卷积层conv.weight.data = kernel.view(1,1,3,3)out = pool(conv(V(input_data))) # 进行卷积to_pil(out.data.squeeze(0)) # 将卷积锐化后的图像展示
 (输出显示的是锐化后的图像)
(输出显示的是锐化后的图像)
池化层:用于图像的下采样,减少图片的特征
除了卷积层和池化层以外,图像相关的问题中还有用到以下几个层:
Linear:全连接层BatchNorm:批规范化层,同样按照数据的类型分为1D、2D和3DDropout:用来防止过拟合,同样分为1D、2D和3D激活函数
激活函数通常用来给模型中的参数添加非线性的关系
Pytorch提供了一些已经实现好的激活函数,这些激活函数可以作为独立的layer来使用。
其中最常见的激活函数就是ReLU,数学表达式如下:
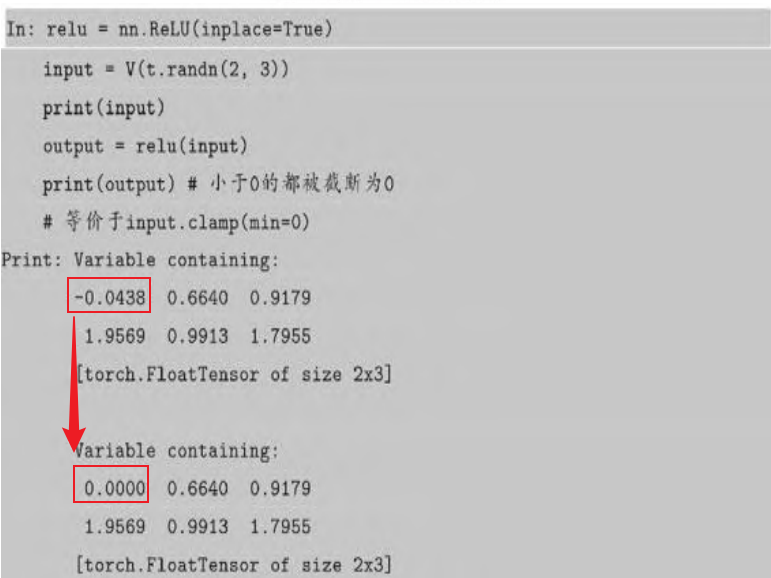
在上述神经网络中的各个层之间,都是将上一层的输出作为下一层的输入,这种网络被称为前馈神经网络
对于这种网络,如果不断重复的写复杂的forward函数显得有些冗余复杂,一般可以采用ModuleList或者Sequential来进行简化。
Sequential是一个特殊的Module,它包含几个子module,前向传播时会 将 输 入 一 层 接 一 层 地 传 递 下 去 。 ModuleList 也 是 一 个 特 殊 的 Module,可以包含几个子module,可以像用list一样使用它,但不能 直接把输入传给ModuleList。

循环神经网络
损失函数
在深度学习中要用到各种各样的损失函数(Loss Function),这些损失函数可以看做是一种特殊的layer,Pytorch将这些损失函数作为nn.Module的子类,在分类问题中使用较多的就是交叉熵损失CrossEntropyloss
优化器
Pytorch将深度学习中常用的优化方法全部封装到了torch.optim中,并且支持自定义参数,扩展成自定义的优化方法。
所有的优化方法都是继承于optim.Optimizer,并实现了自己的优化步骤,比较常见的优化方法是:
- 随机梯度下降法(SGD)
-
nn.functional
在
pytorch中,大多数的layer在functional中都有一个与之对应的函数。nn.Modules中layer都是通过class这种类的方式进行定义,能够提取可以学习的参数。而functional中的函数更像是纯函数,使用def function(input)来定义my_input = V(t.randn(2,3))model = nn.Linear(3,4)output1 = model(my_input)output2 = nn.functional.linear(my_input, model.weight, model.bias)output1 == output2
如上代码所示,输出结果如下:

如果模型中有可以学习的参数,那么就使用
nn.Module反之,则两者都可以使用,取决于个人的爱好 由于激活函数、池化等层没有可以学习的参数,可以使用对应的
functional函数来代替使用- 而卷积、全连接等具有可学习参数的网络建议使用
Model - dropout操作也没有可学习参数,但建议还是用
nn.Dropout,因此在训练和测试的时候Dropout存在一定的差别,使用nn.Module对象可以通过model.eval来加以区分。
Pytorch中常用的工具
数据处理
torchvision
可视化

若有收获,就点个赞吧
0 人点赞
