一、为什么需要数据库设计
- 用户需要什么数据?需要保存什么数据?
- 如何保证表中数据的
**正确性**,对表中数据操作的时候怎么样进行**约束检查** - 如何降低数据的冗余度?
- 如何让负责数据库维护的人员更方便的使用数据库
糟糕的数据库设计可能会有如下问题:
- 数据冗余、信息重复、存储空间浪费
- 数据更新、插入、删除的异常
- 无法正确的表示信息
- 丢失有效信息
二、范式
在关系型数据库中,关于数据库表设计的基本原则、规则就称为是范式
一张数据表的设计结构需要满足的某种设计标准的级别,要想设计一个合理的数据库,就必须要满足一定的范式。范式是在设计数据库的过程中,必须要遵循的规则和指导方法
分类
按照范式的级别,从低到高依次是:
- 第一范式
- 第二范式
- 第三范式
- 巴斯-科德范式(BCNF范式)
- 第四范式
- 第五范式(完美范式)
数据库的范式设计越高阶,数据冗余度就越低。 一般来说,在关系型数据库设计中,最高遵循到BCNF范式,普遍还是第三范式
键、相关属性的概念
超键:唯一标识元祖(某一行数据)的属性(或属性集)叫做超键候选键:如果超键不包括多余的属性,那么就称为是候选键(最小的超键)主键:用户可以从候选键中任意选择一个作为主键外键:数据库表R1中的某属性集不是R1的主键,而是数据表R2的主键,那么这个属性集就是数据表R1的外键主属性:包含在任意候选键中的属性,被称为是主属性非主属性:与主属性相对,指的是不包含在任何一个候选键中的属性
第一范式
主要是确保数据表中的每个字段的值必须具有原子性,也就是说数据表中每个字段不可再次进行拆分
数据表中某个属性不能是复合属性
第二范式
在满足第一范式的基础上,还要满足数据表里的每一条记录,都是可唯一标识的,而且所有的非主键字段,都必须完全依赖于主键,不能只依赖于主键的一部分。
简单来说,就是非主键的字段必须由主键字段一起确定,不能由其中的部分超键所决定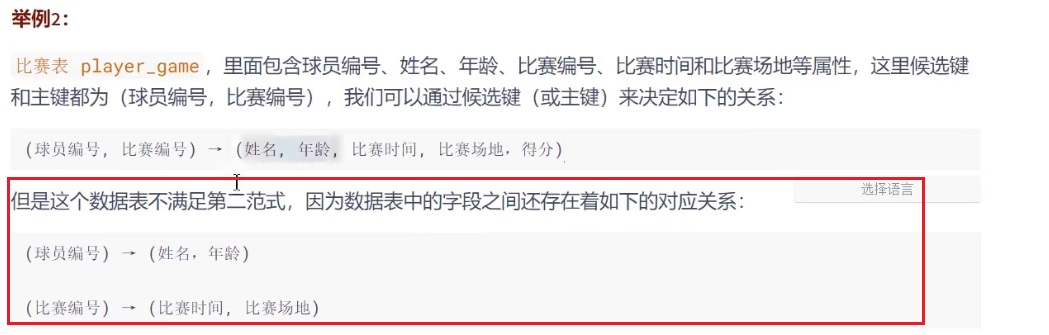
不满足第二范式可能存在的问题:
数据冗余:如果一个球员可以参加M场比赛,那么球员的信息就会重复存储m-1次插入异常:在新添加一场比赛的时候,由于球员编号和比赛编号是主键,那么如果此时还没有确定球员都有谁,那么比赛信息是无法插入到表中的(一般情况下,不允许主键是为空的,即使是联合主键也一样)删除异常:如果某个比赛只有一个球员,那么删除此球员信息的同时,也会把对应比赛的信息给删除。更新异常:如果调整了某个比赛的信息,那么数据表中有关这场比赛的所有记录都需要进行修改,否则就会出现数据矛盾的问题。
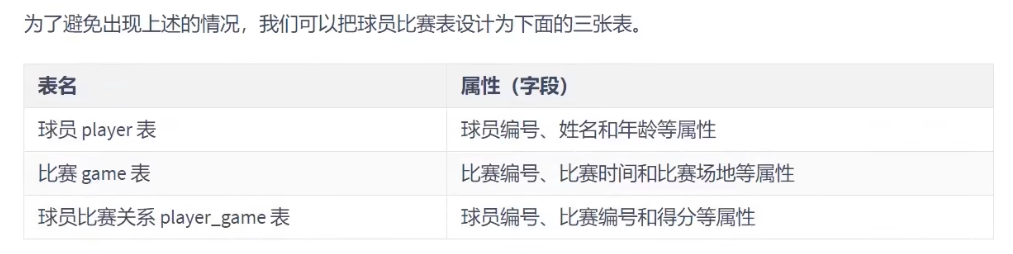
如果存在不完全依赖,应该将这一部分抽离出来,单独作为一张表进行存储
第三范式
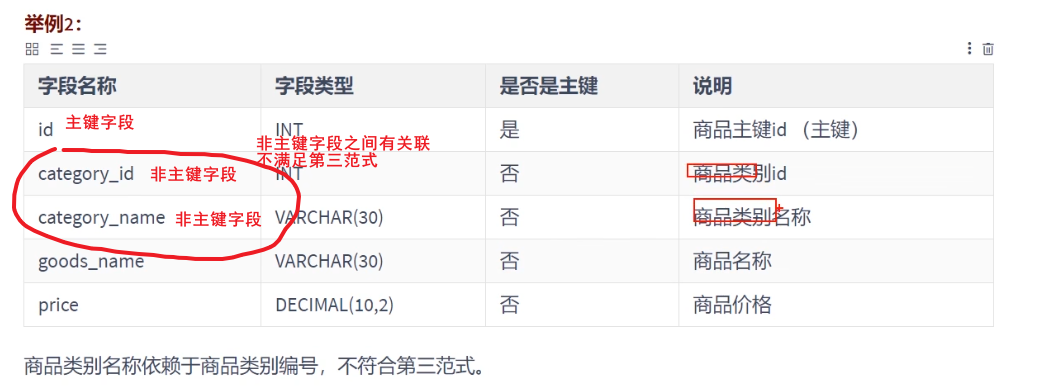
第三范式是在第二范式的基础上,确保数据表中的每一个非主键字段都必须和主键字段直接相关。 也就是说,非主键字段不能依赖于其他非主键字段,非主键字段之间必须相互独立
小结
(1)第一范式:每一列必须保证原子性,不能继续拆分
(2)第二范式:确保每列和主键都是完全依赖
(3)第三范式:确保非主属性列之间不存在关联,只和主键相关联
优点:可以减少数据冗余
缺点:会降低查询的效率,需要关联多张数据表
巴斯范式(BCNF)
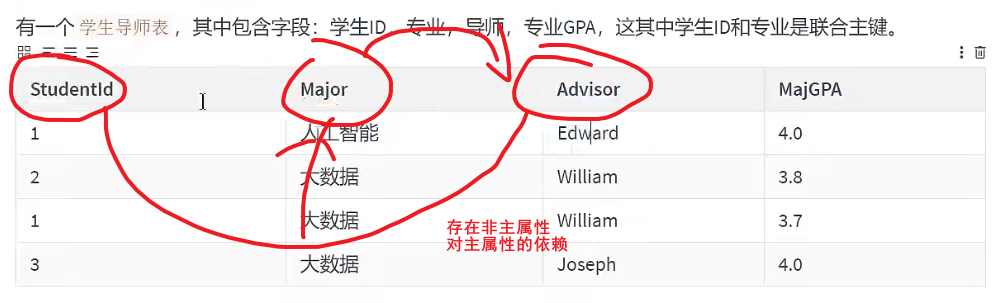
若一个关系达到了第三范式,并且他只有一个候选键,或者他的每个候选键都是单属性,那么该关系自然达到BC范式
第四范式
多值依赖的相关概念:
多值函数:属性之间的一对多关系,记作:K->->A函数依赖:单值依赖,所以不能表达属性值之间的一对多关系平凡的多值依赖:全集U=K+A,一个K可以对应于多个A。此时,整张表就是一组一对多关系非平凡的多值依赖:全集U=K+A+B,一个K可以对应于多个A,也可以对应于多个B,并且A和B之间是相互独立的,即K->A->A,K->B->B。整个表有多组一对多关系
第四范式是在BCNF范式的基础上,消除非平凡且非函数依赖的多值依赖(消除一张表内的多对多关系)

三、实战案例

若有收获,就点个赞吧
0 人点赞
