一、单机指定时间执行定时任务实现方式
1.Timer运行机制
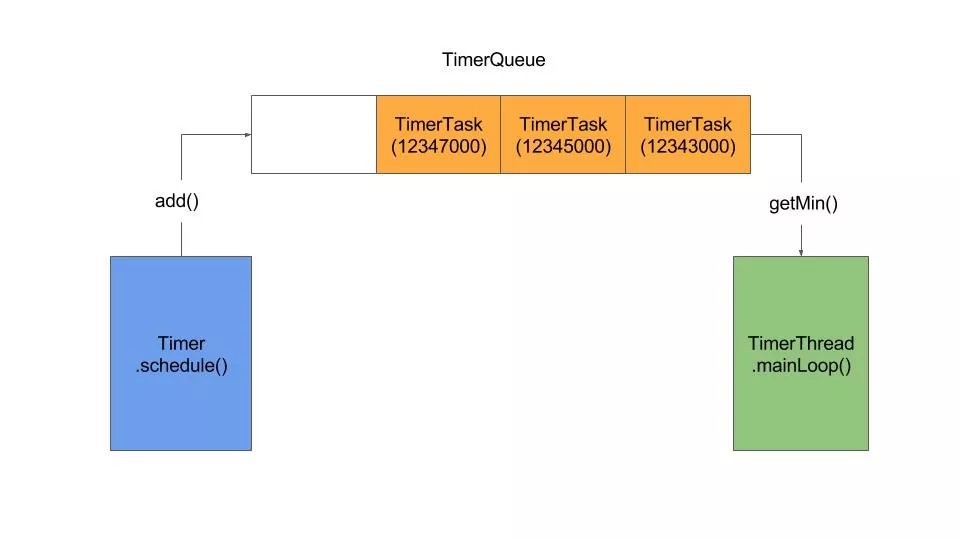
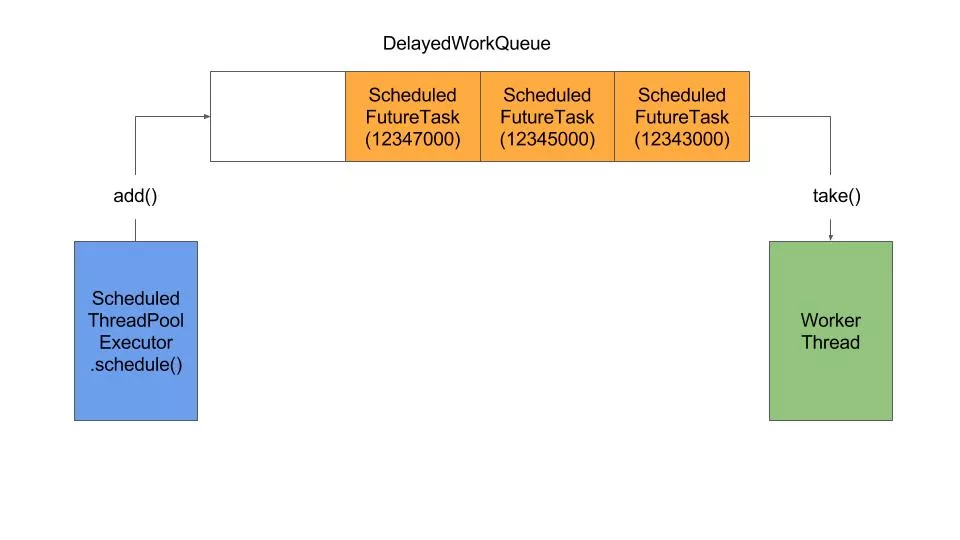
2.ScheduledThreadPoolExecutor的运行机制
1.原理图
2.Leader/Follower模式
3.Timer和ScheduledThreadPoolExucutor区别
Timer是基于绝对时间,ScheduledThreadPoolExucutor基于相对时间Timer是单线程,ScheduledThreadPoolExucutor是多线程Timer运行发生异常,整个TimerThread崩溃,而ScheduledThreadPoolExucutor对异常进行捕获4.自行实现指定时间执行的定时任务
建立数据库定时任务表,用户存入要执行的定时任务,业务ID
- 定义Producer类,用于生产指定定时任务,往延迟队列里写入数据,指定的毫秒时间戳
- 定义Consumer接口,自身业务可以通过实现Consumer接口消费队列中的数据
定义SpringBoot自启动方法,死循环从延迟队列中取最小时间戳数据,与当前时间进行对比如果小于则开始执行,休眠100ms继续下一次循环
5.Quartz实现
参考文档:https://www.w3cschool.cn/quartz_doc/quartz_doc-2put2clm.html
二、分布式指定时间执行的定时任务实现方式(自行Redis实现)
流程设计分析
因为是应用是分布式部署,所以需要考虑分布式锁处理分布式一致性
- 使用Redis的有序集合(Sorted Set)将要执行任务的ID和毫秒时间戳ZAdd到有序集合中
- 使用SpringBoot的定时任务,定时1秒去执行消费定任务任务方法
- 消费方法加分布式锁,避免重复消息,通过死循环获取有序集合最小的时间戳与当前时间戳做对比,如果小于则执行,如果大于等线程等待100ms后继续下一次循环。
```java
/**
- 获得分布式锁 *
- @param redisClientId Redis客户端ID
- @return bool
*/
public boolean redisDistributedLock(String key, String redisClientId, long timeout, TimeUnit unit) {
ValueOperations
} String cacheClientId = ops.get(key); if (cacheClientId.equals(redisClientId)) {return true;
} return false; }redisExpire(key, timeout, unit);return true;
/**
- 执行定时任务
*/
public void runBenchGameDelayTask(BenchDelayTaskType type) {
while (true) {
} } ```Set<ZSetOperations.TypedTuple<String>> typedTuples = benchGameCacheService.benchGameTaskZRange(type);if (typedTuples.size() > 0) {benchGameTaskProcess(type, typedTuples);}try {Thread.sleep(100);} catch (InterruptedException e) {e.printStackTrace();log.error("[runBenchGameDelayTask] type={}, error={}", type.getData(), e);}
三、分布式指定时间执行的定时任务实现方式(三方框架)
1.Quartz集群解决方案
在quartz的集群解决方案里有张表scheduler_locks,quartz采用了悲观锁的方式对triggers表进行行加锁,以保证任务同步的正确性。一旦某一个节点上面的线程获取了该锁,那么这个Job就会在这台机器上被执行,同时这个锁就会被这台机器占用。同时另外一台机器也会想要触发这个任务,但是锁已经被占用了,就只能等待,直到这个锁被释放
quartz的分布式调度策略是以数据库为边界资源的一种异步策略。各个调度器都遵守一个基于数据库锁的操作规则从而保证了操作的唯一性
原理图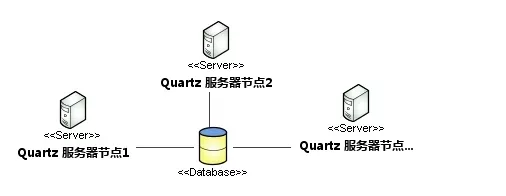
缺点:quartz的分布式只是解决了高可用的问题,并没有解决任务分片的问题,还是会有单机处理的极限2.TBSchedule
TBSchedule是一款非常优秀的高性能分布式调度框架,广泛应用于阿里巴巴、淘宝、支付宝、京东、聚美、汽车之家、国美等很多互联网企业的流程调度系统。tbschedule在时间调度方面虽然没有quartz强大,但是它支持分片功能。和quartz不同的是,tbschedule使用ZooKeeper来实现任务调度的高可用和分片
原理图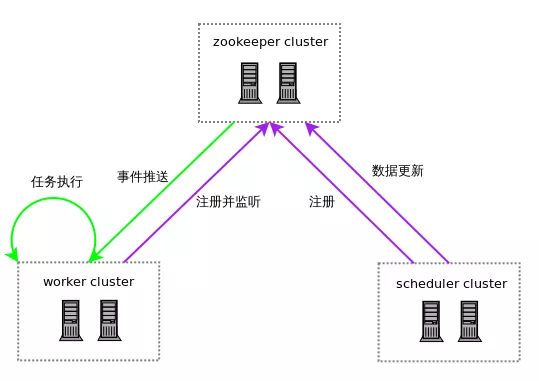
TBSchedule的分布式机制是通过灵活的Sharding方式实现的,分片的规则由客户端决定,比如可以按所有数据的ID按10取模分片、按月份分片等等
BSchedule会定时扫描当前服务器的数量,重新进行任务分配。TBSchedule不仅提供了服务端的高性能调度服务,还提供了一个scheduleConsole的war包,随着宿主应用的部署直接部署到服务器,可以通过web的方式对调度的任务、策略进行监控管理,以及实时更新调整3.elastic-job
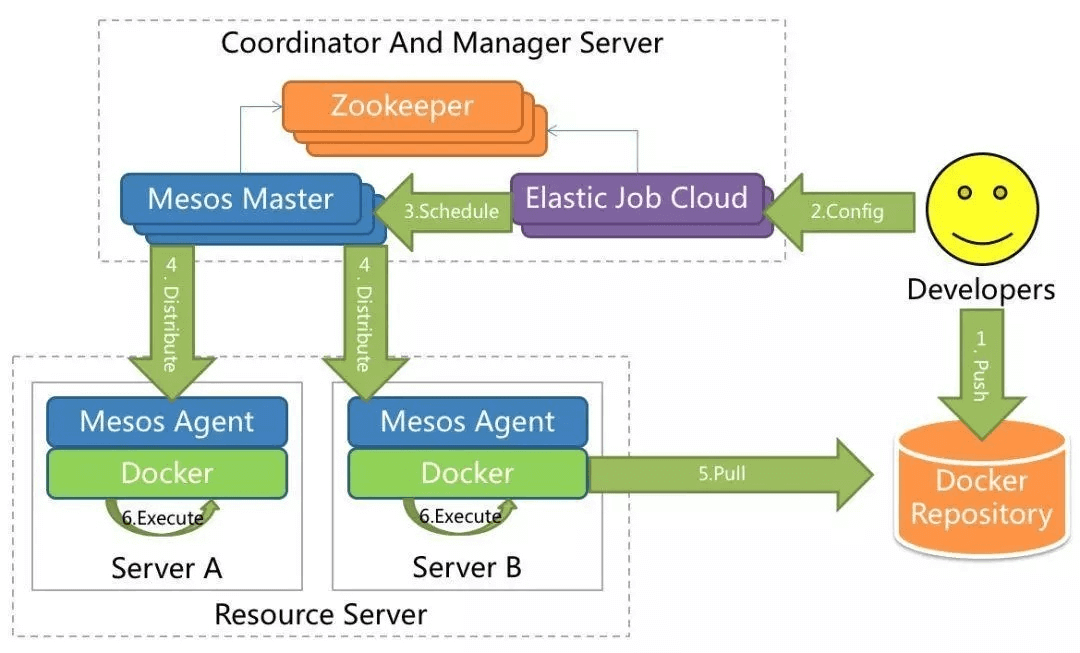
Elastic-Job当当开源的分布式调度解决方案,由两个相互独立的子项目Elastic-Job-Lite和Elastic-Job-Cloud组成。Elastic-Job-Lite定位为轻量级无中心化解决方案,使用jar包的形式提供分布式任务的协调服务
原理图: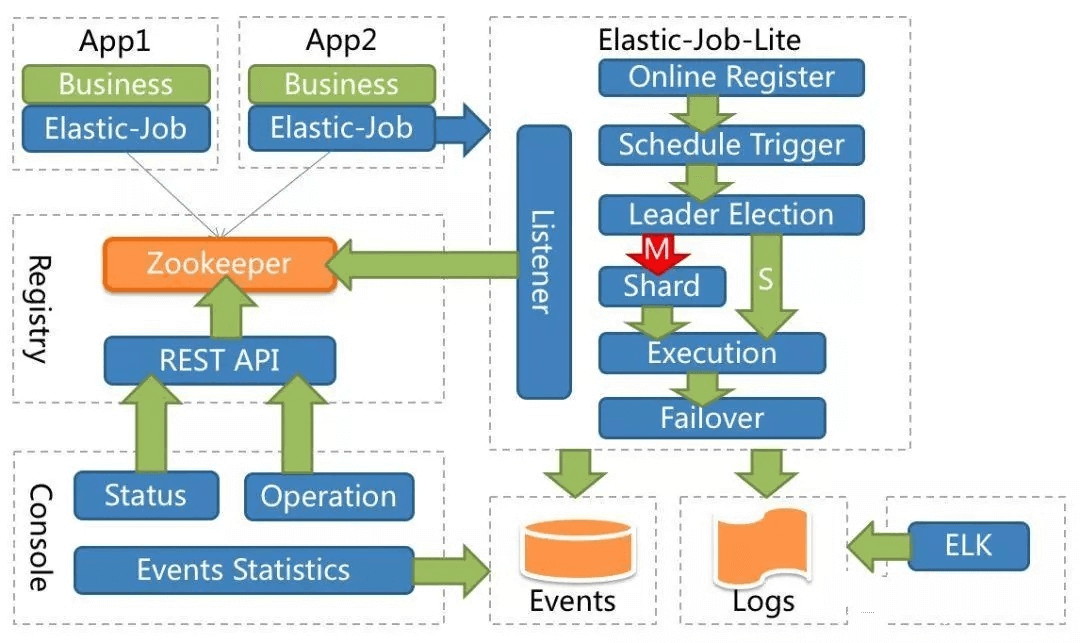
特点:
- 分布式调度协调
- 弹性扩容缩容
- 失效转移
- 错过执行作业重触发
- 作业分片一致性,保证同一分片在分布式环境中仅一个执行实例
- 自诊断并修复分布式不稳定造成的问题
- 支持并行调度
- 支持作业生命周期操作
- 丰富的作业类型
- Spring整合以及命名空间提供
-
4.唯品会开源框架Sature
特性如下:
Time based and language unrestricted job
- Easy job implmentation and web based management
- Parallel subtask(shard) scheduling
- 1-second-level scheduling supported
- Intelligent load based job allocation
- Fail detection & failover support
- Statistical data visualization
- All-around monitoring and easy troubleshooting
- Multi-active cluster deployment support
- Container friendly
- Stand the test of billion times scheduling per day

若有收获,就点个赞吧
0 人点赞
