JavaCollection集合可以通过parallelStream()的得到一个并行流。
Stream<Integer> stream = new ArrayList<Integer>().parallelStream();
串行流也可以通过parallel()方法转为并行流
Stream<Integer> stream = new ArrayList<Integer>().stream().parallel();
对并行流的疑问
- 串行流和并行流哪个效率更高?(这还有疑问吗?肯定是并行流呀?sure?)
- 并行流得到的结果是否一定准确?
- 它的实现机制是什么样的?
- 开发中可以使用并行流嘛?
并行流的效率是否更高
在Java8以前,遍历一个长度非常大的集合往往非常麻烦,如需要使用多个线程配合synchronized,Lock和Atomic原子引用等进行遍历,且不说多线程之间的调度,多线程同步API的上手成本也比较高。
现在有更为简单的遍历方式,且不局限于遍历集合。
先往一个List添加10万条记录,代码比较简单,单条记录的内容使用UUID随机生成的英文字符串填充
List<String> list = new ArrayList<String>();for (int i = 0; i < 100000; i++) {list.add(UUID.randomUUID().toString());}
普通for循环该List,然后将每条记录中的a替换成b
for (int i = 0; i < list.size(); i++) {String s = list.get(i);String replace = s.replace("a", "b");}
注意:这里使用String replace = s.replace("a", "b");这一行代码作为简单的业务处理,而不是System.out.println(s),因为打印的时候存在synchronized同步机制,会严重影响并行流的效率!
增强for循环
for (String s : list) {String replace = s.replace("a", "b");}
串行流
list.stream().forEach((s)->{String replace = s.replace("a", "b");});
并行流
list.parallelStream().forEach((s)->{String replace = s.replace("a", "b");});
在保证执行机器一样的情况下,上述遍历代码各执行十次,取执行时间的平均值,单位毫秒,结果如下:
从结果中可知,在数据量较大的情况下,普通for,增强for和串行流的差距并不是很大,而并行流则以肉眼可见的差距领先于另外三者!
数据量较大的情况下,并行流的遍历效率数倍于顺序遍历,在小数据量的情况下,并行流的效率还会那么高吗?
将上面10万的数据量改为1000,然后重复一百次取平均值,结果如下:
对结果进行分析,现在开发中比较少见的普通for遍历集合的方式,居然是顺序遍历中速度最快的!而它的改进版增强for速度小逊于普通for。
究其原因,是增强for内部使用迭代器进行遍历,需要维护ArrayList中的size变量,故而增加了时间开销。
而串行流的时间开销确实有点迷,可能的原因是开启流和关闭流的时间开销比较大
并行流花费的时间任然优秀于另外的三种遍历方式!
不过,有一点需要注意的是,并行流在执行时,CPU的占用会比另外三者高
现在可以得到一个结论,并行流在大数据量时,对比其它的遍历方式有几倍的提升,而在数据量比较小时,提升不明显。
并行流处理结果是否准确
这个准确,举个例子来说,希望遍历打印一个存有0 1 2 3 4 5 6 7 8 9的list,如0 1 2 3 4 5 6 7 8 9,代码可能会这么写
//数据List<Integer> list = new ArrayList<>();for (int i = 0; i < 10; i++) {list.add(i);}//遍历打印list.stream().forEach(i -> System.out.print(i + " "));
打印的结果如下:
0 1 2 3 4 5 6 7 8 9
结果没有任何问题,如果是并行流呢?遍历代码如下
list.parallelStream().forEach(i -> System.out.print(i + " "));
打印的结果如下:
6 5 1 0 9 3 7 8 2 4
第二次打印的结果如下:
6 5 0 1 7 9 8 3 4 2
可以看到打印出来的顺序是混乱无规律的
那是什么原因导致的呢?
并行流内部使用了默认的ForkJoinPool线程池,所以它默认的线程数量就是处理器的数量,通过Runtime.getRuntime().availableProcessors()可以得到这个值。
测试电脑的线程数是12,这意味着并行流最多可以将任务划分为12个小模块进行处理,然后再合并计算得到结果
如将0~9这是个数字进行划分:
0 1 2 3 4 5 6 7 8 9第一次划分得到两个小模块:0 1 2 3 45 6 7 8 9第二次划分得到四个小模块:0 1 23 45 6 78 9第三次划分得到八个小模块:0 12345 6789第三次划分时,2 3 4这些数据,明显已经不能再继续划分,故而2 3 4 这些数据可以先进行打印第四次划分得到10个小模块:0123456789这些小模块在无法继续细分后就会被打印,而打印处理的时候为了提高效率,不分先后顺序,故而造成打印的乱序
结合以上的测试数据,可以得到这样一个结论,当需要遍历的数据,存在强顺序性时,不能使用并行流,如顺序打印0~9;不要求顺序性时,可以使用并行流以提高效率,如将集合中的字符串中的”a”替换成”b”
并行流的实现机制
在Java7时,就已经提供了一个并发执行任务的API,Fork/Join,将一个大任务,拆分成若干个小任务, 再将各个小任务的运行结果汇总成最终的结果。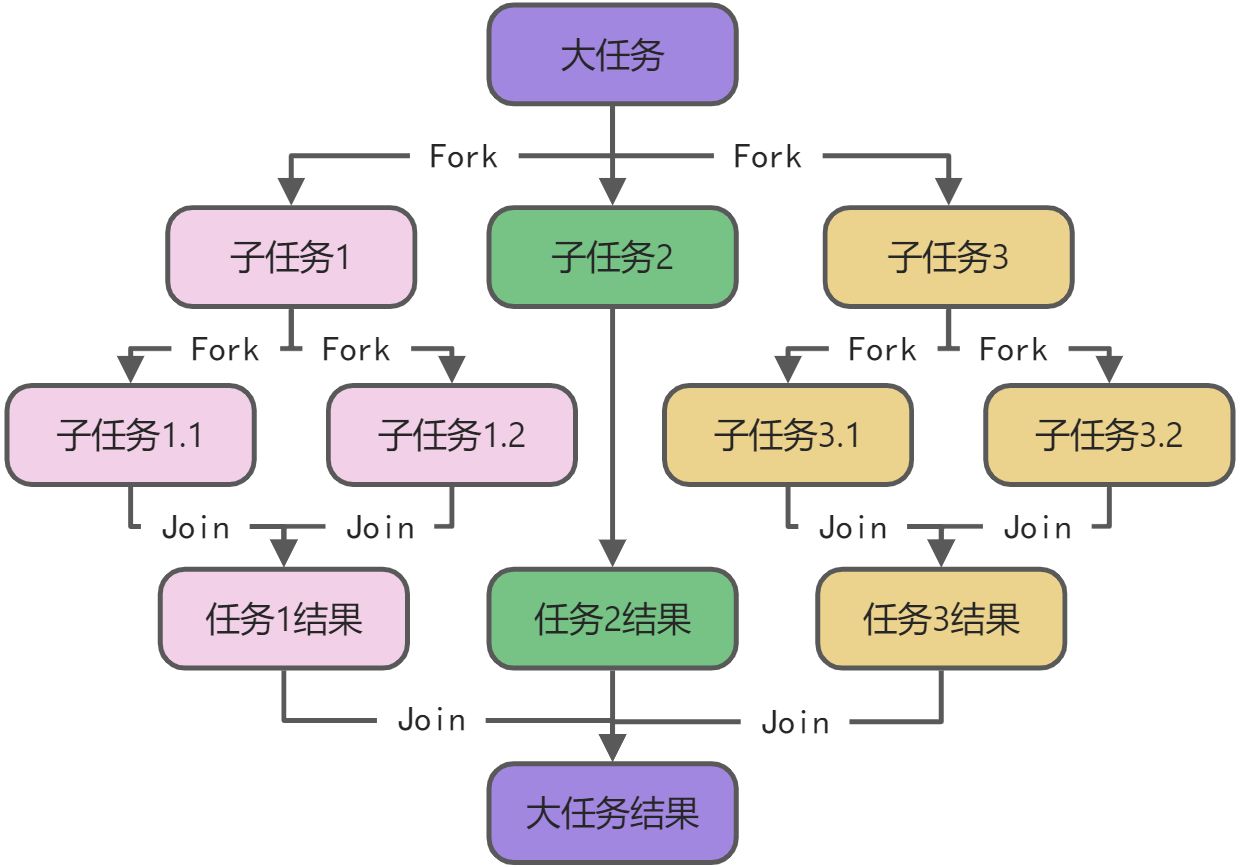
而在java8提供的并行流中,在实现Fork/Join的基础上,还用了工作窃取模式来获取各个小模块的运行结果,使之效率更高!
也可以使用Fock/Join机制,模仿一下并行流的实现过程。
如:进行数据的累加
public class ForkJionCalculate extends RecursiveTask<Long> {private long start;private long end;/*** 临界值*/private static final long THRESHOLD = 10000L;public ForkJionCalculate(long start, long end) {this.start = start;this.end = end;}/*** 计算方法* @return*/@Overrideprotected Long compute() {long length = end - start;if (length <= THRESHOLD) {long sum = 0;for (long i = start; i <= end; i++) {sum += i;}return sum;} else {long middle = (start + end) / 2;ForkJionCalculate left = new ForkJionCalculate(start, middle);left.fork();//拆分,并将该子任务压入线程队列ForkJionCalculate right = new ForkJionCalculate(middle + 1, end);right.fork();return left.join() + right.join();}}}
处理类需要实现RecursiveTask<T>接口,还需指定一个临界值,临界值的作用就是指定将任务拆分到什么程度就不拆了
测试代码:
public static void main(String[] args) {Instant start = Instant.now();ForkJoinPool pool = new ForkJoinPool();ForkJionCalculate task = new ForkJionCalculate(0, 10000000000L);Long sum = pool.invoke(task);System.out.println(sum);Instant end = Instant.now();System.out.println("耗费时间:" + Duration.between(start, end).toMillis());}
并行流的适用场景
其实Java这门编程语言其实有很多种用途,通过swing类库可以构建图形用户界面,配合ParallelGC进行一些科学计算任务,不过最广泛的用途,还是作为一门服务器语言,开发服务器应用,以这种方式进行测试。
使用SpringBoot构建一个工程,然后写一个控制器类,在控制器类中,如上进行1000和10万的数据量测试
另外使用PostMan发送1000并发调用该接口,取平均时间,单位为毫秒值
控制器类测试代码:
@RequestMapping("/parallel")@ResponseBodypublic String parallel() {//生成测试数据List<String> list = new ArrayList<>();for (int i = 0; i < 1000; i++) {list.add(UUID.randomUUID().toString());}//普通for遍历for (int i = 0; i < 1000; i++) {String s = list.get(i);String replace = s.replace("a", "b");}return "SUCCESS";}
数据量1000时,每次请求消耗的时间
数据量10W时,每次请求消耗的时间
在之前的测试中,并行流对比其他的遍历方式都有两倍以上的差距,而在并发量较大的情况下,服务器线程本身就处于繁忙的状态,即使使用并行流,优化的空间也不是很大,而且CPU的占用率也会比较高。故而可以看到,并行流在数据量1000或者10万时,提升不是特别明显。
但是并不是说并行流不能用于平常的开发中,如CPU本身的负载不高的情况下,还是可以使用的;在一些定时任务的项目中,为了缩短定时任务的执行时间,也可以斟酌使用。
最后总结一下:在数据量比较大的情况下,CPU负载本身不是很高,不要求顺序执行的时候,可以使用并行流。

若有收获,就点个赞吧
0 人点赞
