主内存与工作内存
java内存模型规定了所有的变量都存储在主内存(Main Memory)中。每条线程还有自己的工作内存(Working Memory),线程的工作内存中保存了被该线程使用的变量的主内存副本,线程对变量的所有操作(读取、赋值等)都必须在工作内存中进行,而不能直接读写主内存中的数据。线程间变量值的传递均需要通过主内存来完成。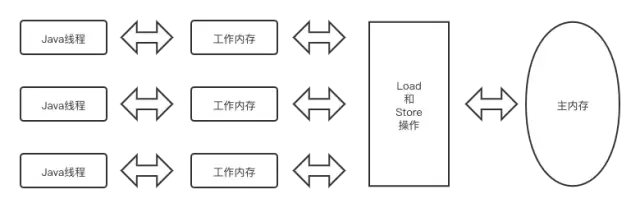
内存间交互操作
lock(锁定)
作用于主内存的变量,把一个变量标识为一条线程独占的状态unlock(解锁)
作用于主内存的变量,把一个处于锁定状态的变量释放出来,释放后的变量才可以被其他线程锁定read(读取)
作用于主内存的变量,把一个变量的值从主内存传输到线程的工作内存中,以便所有的load动作使用load(载入)
作用于工作内存的变量,把read操作从主内存中得到的变量值放入工作内存的变量副本中use(使用)
作用于工作内存的变量,把工作内存中一个变量的值传递给执行引擎,每当虚拟机遇到一个需要使用变量的值的字节码指令时将会执行这个操作assign(赋值)
作用于工作内存的变量,把一个从执行引擎接收的值赋给工作内存的变量,每当虚拟机遇到一个给变量赋值的字节码指令时执行这个操作store(存储)
作用于工作内存的变量,把工作内存中一个变量的值传送到主内存中,以便随后的write操作write(写入)
作用于主内存的变量,把store操作从工作内存中得到的变量的值放入主内存的变量中
把一个变量从主内存拷贝到工作内存,那就要按顺序执行read和load操作
把变量从工作内存同步回主内存,就要按顺序执行store和write操作
java内存模型只要求上述两个操作必须按顺序执行,但不要求是连续执行。
规则:
如果对一个变量执行lock操作,那将会清空工作内存中此变量的值。执行引擎使用这个变量前,需要重新执行load或assign操作以初始化变量的值
对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store、write操作)
volatile型变量的特殊规则
当一个变量被定义为volatile后,它将具备两项特性:
第一项是保证此变量对所有线程的可见性
java中的运算操作符并非原子操作,这导致volatile变量的运算在并发下一样是不安全的
在不符合以下两条规则的运算场景中,仍然要通过加锁(synchronized、java.util.concurrent中的锁或原子类)来保证原子性:
- 运算结果不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值
- 变量不需要与其他的状态变量共同参与不变约束
第二项是禁止指令重排序优化
有volatile修饰的变量,赋值后多执行了一个“lock addl
lock addl 0x0,(lockaddl0x0,(%esp)指令把修改同步到内存时,意味着所有之前的操作都已经执行完成,这样便形成了“指令重排序无法越过内存屏障”的效果
Java内存模型对volatile变量定义的规则:
V是volatile变量
- 在工作内存中,每次使用V前都必须先从主内存刷新最新的值,用于保证能看见其他线程对变量V所做的修改
- 每次修改V后都必须立即同步回主内存中,用于保证其他线程可以看到自己对变量V所做的修改
volatile修饰的变量不会被指令重排序优化,从而保证代码的执行顺序与程序的顺序相同原子性、可见性与有序性
原子性
java内存模型直接保证的原子性变量操作包括read、load、use、assign、store、write。大致可以认为,基本数据类型的访问、读写都具备原子性的。
如果需要一个更大范围的原子性保证,还提供了lock和unlock操作来满足需求,更高层次的字节码指令monitorenter和monitorexit可以隐式地使用这两个操作。反映到Java代码中就是同步块—synchronized关键字可见性
一个线程修改了共享变量的值时,其他线程能立即得知这个修改
除了volatile外,还有synchronized和final可实现可见性。
同步块的可见性是由“对一个变量执行unlock操作之前,必须先把此变量同步回主内存中(执行store、write操作)”获得。final的可见性:被final修饰的字段在构造器中一旦被初始化完成,并且构造器没有把”this”的引用传递出去,那么其他线程中就能看的final字段的值有序性
如果在本线程内观察,所有操作都是有序的【线程内试表现为串行的语义】;如果在一个线程中观察另一个线程,所有操作都是无序的【指令重排序、工作内存与主内存同步延迟】。
volatile关键字本身就包含了禁止指令重排序的语义synchronized则是由”一个变量在同一个时刻只允许一条线程对其进行lock操作”这条规则获得线程
状态转换
新建(New)
创建后尚未启动的线程- 运行(Running)
包括操作系统线程状态中的Running和Ready,有可能在执行,也有可能在等待着操作系统为它分配执行时间 - 无限期等待(Waiting)
这种状态的线程不会被分配处理器执行时间,要等待被其他线程显式唤醒
— 没有设置Timeout参数的Object::wait()方法
— 没有设置Timeout参数的Thread::join()方法
—LockSupport::park()方法 - 限期等待(Timed Waiting)
这种状态的线程也不会被分配处理器执行时间,无须等待被其他线程显式唤醒,在一定时间之后他们会由系统自动唤醒
—Thread::sleep()
— 设置了Timeout参数的Object::wait()
— 设置了Timeout参数的Thread::join()
—LockSupport::parkNanos()
—LockSupport::parkUnit() - 阻塞(Blocked)
线程被阻塞了。
“阻塞状态”:在等待着获取到一个排它锁,这个事件将在另一个线程放弃这个锁的时候发生;
“等待状态”:等待一段时间,或者唤醒动作的发生。在程序等待进入同步区域的时候,线程将进入这种状态 - 结束(Terminated)
已终止线程的线程状态,线程已结束执行

使用线程池的原因
服务器在创建和销毁线程上花费的时间和消耗的系统资源都很大,甚至可能要比在处理实际的用户请求的时间和资源要多的多。除了创建和销毁线程的开销之外,活动的线程也需要消耗系统资源。如果在一个jvm里创建太多的线程,可能会使系统由于过度消耗内存或“切换过度”而导致系统资源不足。
线程池主要用来解决线程生命周期开销问题和资源不足问题。通过对多个任务重复使用线程,线程创建的开销就被分摊到了多个任务上。而且由于请求到达时线程已经存在,所以消除了线程创建所带来的延迟。
参数
corePoolSize: 核心线程数
- 当线程数>=corePoolSize,且任务队列已满时,线程池会创建新线程来处理任务
当线程数=maxPoolSize,且任务队列已满时,线程池会拒绝处理任务而抛出异常
keepAliveTime: 线程空闲时间当线程空闲时间达到
keepAliveTime时,线程会退出,直到线程数量=corePoolSize- 如果
allowCoreThreadTimeout=true,则会直到线程数量=0
rejectedExecutionHandler: 任务拒绝处理器
拒绝的情况:
- 线程数已达到
maxPoolSize,且队列已满,会拒绝新任务 - 线程池被调用
shutdown()后,会等待线程池里的任务执行完毕,再shutdown。如果在调用shutdown()和线程池真正shutdown之间提交任务,会拒绝新任务。
拒绝策略:
- AbortPolicy 丢弃任务,抛运行时异常(默认)
- CallerRunsPolicy 调用者执行任务
- DiscardPolicy 直接丢弃
DiscardOldestPolicy 丢弃最先入队列(队列头部)的任务
ThreadPoolExecutor执行顺序当线程数 < 核心线程数时,创建线程
- 线程数 >= 核心线程数,且队列未满时,将任务放入任务队列
- 当线程数 >= 核心线程数,且队列已满
3.1 若线程数 < 最大线程数,创建线程
3.2 若线程数 = 最大线程数,抛出异常,拒绝任务线程参数的合理设置
参数说明
- tasks,程序每秒需要处理的最大任务数量(假设系统每秒任务数100~1000)
- tasktime,单线程处理一个任务所需的时间(每个任务耗时0.1秒)
- responsetime,系统允许任务最大的响应时间(每个任务的响应时间不得超过2秒)
corePoolSize 核心线程数
每个任务需要tasktime秒处理,则每个线程每秒可以处理1/tasktime个任务。系统每秒有tasks个任务需要处理,则需要的线程数:tasks/(1/tasktime)。即tasks tasktime个线程数。
假设系统每秒任务数为100 ~ 1000,则需要1000.1 ~ 10000.1,即10~100个线程。那么corePoolSize应设置大于10.
* 具体设置最好根据8020原则。即80%情况下系统每秒任务数。若系统80%情况下任务数小于200,最多时为1000,则corePoolSize可设置为20queueCapacity 任务队列的长度
任务队列的长度要根据核心线程数,以及系统对任务响应时间的要求有关。
每个线程在响应时间内可以处理responsetime / tasktime个。则队列长度可设置为corePoolSize (responsetime / tasktime),20 (2/0.1) =400,则队列长度可设置为400maxPoolSize 最大线程数
系统负载达到最大值时,核心线程数已无法按时处理完所有任务,这时就需要增加线程。每秒200个需要20个线程,tasktime=0.1,那么每秒达到1000个任务时,则需要 (1000-queueCapacity)*tasktime = 60
若结合CPU的情况,比如当线程数量达到50时,CPU达到100%,则将maxPoolSize设置为60也不合适,此时若系统负载长时间维持在每秒1000个任务,则超出了线程池处理能力,应设法降低每个任务的处理时间

若有收获,就点个赞吧
0 人点赞
