JVM 内存区域 堆
堆是JVM中相当核心的内容,因为堆是JVM中管理的最大一块内存区域,大部分的GC也发生在堆区,那接下来就让深入地探究一下JVM中的堆结构。
需要明确,一个JVM实例只存在一个堆内存,堆区在JVM启动的时候就被创建,其空间大小也被确定下来,但堆空间的大小是可以通过JVM参数调节的,所有的线程共享堆。
堆的内存结构
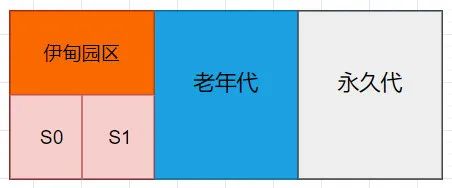
因为堆是垃圾回收的重点区域,现代垃圾回收器大部分都基于分代收集理论设计,所以将堆空间分为:
- Young Generation Space(新生代)
- Old Generation Space(老年代)
- Perm Space(永久代)- 永久代是方法区的一个实现(只有HotSpot JVM才有永久代),事实上方法区是逻辑独立的,即:从逻辑上来说,方法区是在堆的外面的
其中新生代又可细分为:
- Eden(伊甸园区)
- Survivor(幸存区)
从JDK1.8开始,JVM规范摒弃了方法区的概念,取而代之的是Meta Space(元空间),使用的是物理内
存。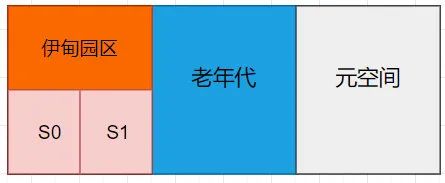
通过两个JVM参数可以设置堆的初始内存和最大内存:
- -Xms:设置堆的初始内存
- -Xmx:设置堆的最大内存
可以先来看看自己的JVM分配的堆内存情况:
public static void main(String[] args) {// 获取堆空间的内存总量long totalMemory = Runtime.getRuntime().totalMemory() / 1024 / 1024;// 获取堆空间试图使用的最大内存long maxMemory = Runtime.getRuntime().maxMemory() / 1024 / 1024;System.out.println(totalMemory + "M");System.out.println(maxMemory + "M");}
运行结果:
123M
1799M
默认情况下堆的初始内存大小是物理内存的64分之一,而最大内存大小是物理内存的四分之一,但是会发现,物理内存(8G)的四分之一应该是2G才对,而堆的最大内存空间并没有到达2G,这个问题留到后面解决,先来设置一下堆的内存大小: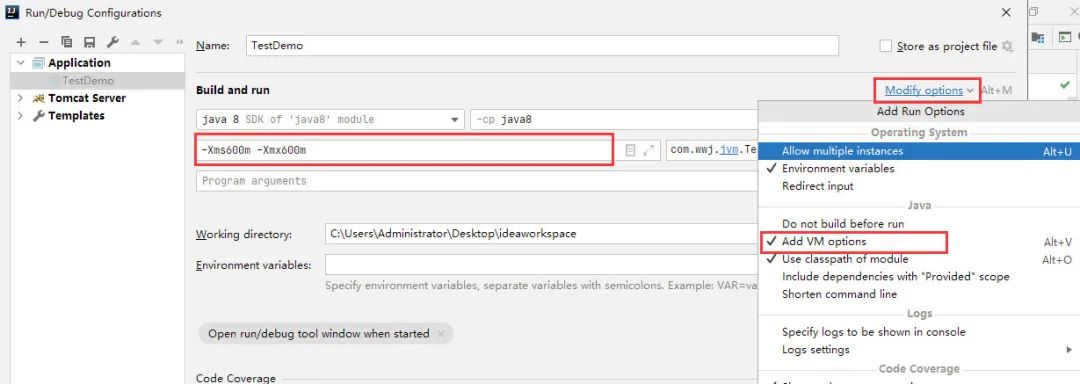
在VM options中填入-Xms600m -Xmx600m ,若是找不到VM options,则点击右上角的Modify options,并勾选Add VM options,此时重新运行程序,结果为:
575M
575M
接下来来详细地分析一下堆的内存分配情况,打开cmd窗口,输入jps 指令可以查看当前正在运行的Java程序,所以改造一下刚才的程序:
public static void main(String[] args) {while (true){}}
一直让它运行着,然后输入jps :
C:\Users\Administrator>jps1860 TestDemo10664 Jps2568 Launcher8200
这样便查询到了TestDemo程序的进程id,然后通过该id查询内存分配情况,输入jstat -gc 1860 :
这里的S0C即为第一块幸存区的总内存,S1C为第二块幸存区的总内存,S0U为第一块幸存区使用的内存,那么S1U就是第二块幸存区使用的内存,后面的参数同理,将这些区域的总量相加25600 + 25600 + 153600 + 409600 = 614400 ,对它除以1024就得到600M,这与之前设置的虚拟机参数就对应上了,但还是无法解释通过Runtime实例获取的内存总量不足600M的问题。
原来,堆中的两块幸存区是不会被同时使用的,这涉及到垃圾收集中的复制算法,该算法总是使用其中一块幸存区空间,当伊甸园区和该幸存区空间满了以后,会触发一次GC,将还存活的对象复制到另一块幸存区上,然后将之前的空间直接清除。
当减去其中一个幸存区的内存:614400 - 25600 = 58800 ,对其除以1024,得到575M,这就是为什么程序的运行结果是575M的原因了。
也可以使用JVM参数-XX:+PrintGCDetails 来查看内存的详细信息: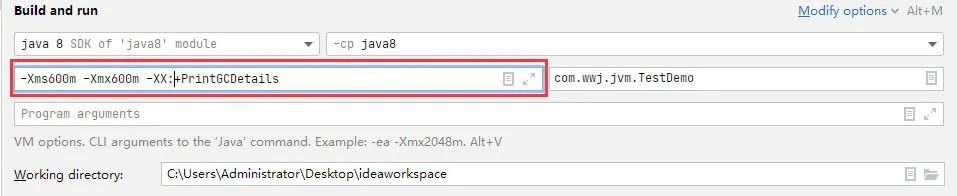
记得把死循环删掉再运行程序,否则就看不到输出结果了:
HeapPSYoungGen total 179200K, used 9216K [0x00000000f3800000, 0x0000000100000000, 0x0000000100000000)eden space 153600K, 6% used [0x00000000f3800000,0x00000000f41001a0,0x00000000fce00000)from space 25600K, 0% used [0x00000000fe700000,0x00000000fe700000,0x0000000100000000)to space 25600K, 0% used [0x00000000fce00000,0x00000000fce00000,0x00000000fe700000)ParOldGen total 409600K, used 0K [0x00000000da800000, 0x00000000f3800000, 0x00000000f3800000)object space 409600K, 0% used [0x00000000da800000,0x00000000da800000,0x00000000f3800000)Metaspace used 3442K, capacity 4496K, committed 4864K, reserved 1056768Kclass space used 376K, capacity 388K, committed 512K, reserved 1048576K
这里的from和to就是两块幸存区的空间。
堆空间最常见的错误就是OutOfMemoryError ,可以写一段程序来产生这个错误:
public class TestDemo {public static void main(String[] args) {List<User> list = new ArrayList<>();while (true) {User user = new User();list.add(user);}}}class User {private byte[] bytes;public User() {bytes = new byte[1024 * 1024];}}
运行片刻程序就报错了:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap spaceat com.wwj.jvm.User.(TestDemo.java:21)at com.wwj.jvm.TestDemo.main(TestDemo.java:11)
这里介绍一款JDK提供的工具,通过它可以更直观地看到堆中的内存分配及变化:
在其bin目录下有一个jvisualvm.exe的可执行文件,直接双击打开它,为了不使程序那么快地结束,在程序中加一个延迟方法:
public static void main(String[] args) {List<User> list = new ArrayList<>();while (true) {try {Thread.sleep(1000);} catch (InterruptedException e) {e.printStackTrace();}User user = new User();list.add(user);}}
将程序重新运行起来,然后查看jvisualvm工具: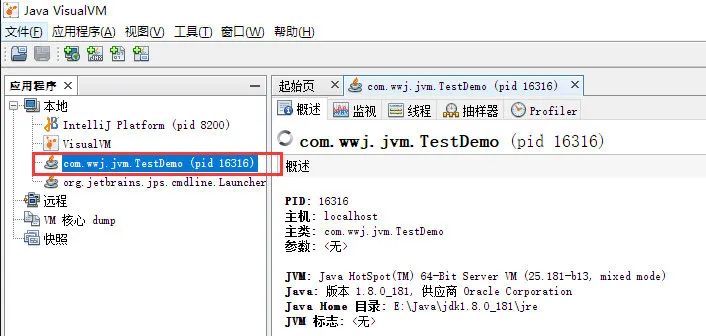
在下面的视图中,能够清楚地观察到堆中各部分内存的动态变化情况: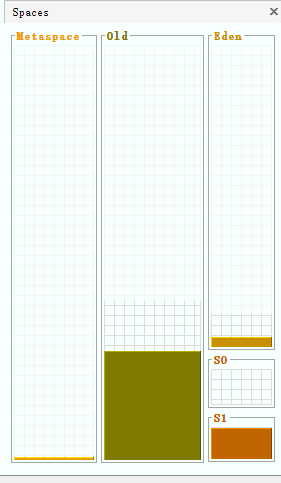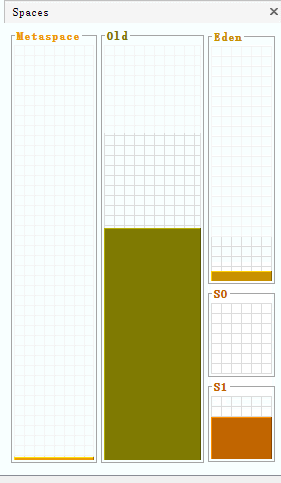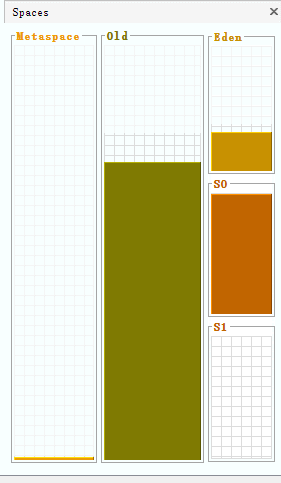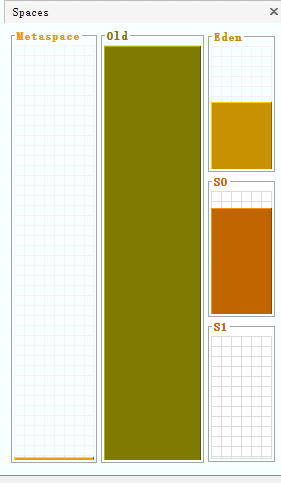
新生代与老年代
存储在JVM中的Java对象大体可分为两类:
- 生命周期较短的瞬时对象,这类对象的创建和死亡都非常迅速
- 生命周期很长的对象,某些对象甚至能够存活到JVM的生命结束
为此,堆空间才被分为新生代和老年代,并将生命周期很短的对象放在新生代,将生命周期很长的对象放在老年代,因为在每次GC时,垃圾回收器都会去判断当前对象是否可以被回收,而这些生命周期很长的对象每次都被垃圾回收器扫描,但每次都不回收,故而可以将这些对象放在老年代,并减少对老年代的GC次数,从而将GC的重心放在新生代上。
通过这两个区域对象的生命周期不同,也可以设置不同的垃圾回收算法,比如对新生代中的对象采用复制算法,因为该区域的对象生命周期短,消亡快,所以当发生GC时并不会存在太多存活的对象,而对老年代则采用标记-清除算法,关于垃圾回收的具体内容在后面还会重点介绍。
下面通过一个程序来分析一下新生代与老年代的内存占比:
public class TestDemo {public static void main(String[] args) {while (true){}}}
将堆的内存空间设置一下-Xms600m -Xmx600m ,查看可视化界面:
新生代的内存空间为150 + 25 +25 = 200 ,所以新生代与老年代内存空间的默认比例为1:2,可以通过虚拟机参数来修改比例:-XX:NewRatio=3
此时表示新生代占1,老年代占3,新生代是老年代内存空间的三分之一。而Eden区和两个Survivor区的内存空间占比默认为:8:1:1 ,也可以通过虚拟机参数修改:-XX:SurvivorRatio=6
此时比例会被修改为6:1:1 。
需要了解:几乎所有的Java对象都是在Eden区被创建出来的,那么有例外情况吗?当然有,如果创建的对象所需内存非常大,以至于Eden区根本放不下,那么该对象就会直接在老年代创建。
对象创建过程
对象的创建是一个非常复杂的过程,它的具体流程如下:
- 创建的对象首先存放在Eden区
- 当Eden区的空间满了以后,此时创建对象便会触发GC(Minor GC),将Eden区中存活的对象放入幸存区,然后清除Eden区
- 当触发Eden区的GC时,会将Eden区中还存活的对象放入幸存区S0
- 当Eden区满了再次触发GC时,会将Eden区中存活的对象和幸存者S0中仍然存活的对象放入幸存区S1
- 若再一次触发Eden区的GC,则将存活的对象又重新放回幸存区S0,依次循环
- 存活的对象被放入幸存区一次,年龄就会加1,当对象的年龄到达15岁时,该对象就会被晋升到老年代
注意在这个过程中,只有Eden区满时才会触发GC,此时垃圾回收器会对Eden区和Survivor区进行清理,Survivor区满并不会触发GC,而且GC完成后,Eden区是一个空的状态。当要创建的对象内存超过Eden区空间时,该对象会被直接晋升到老年代,若是老年代仍然放不下,则触发一次在老年代的GC(Full GC),如果GC完成后还是放不下,则出现OutOfMemoryError: Java heap space 错误。
接下来就来介绍一下垃圾回收类型,大体可分为两类:
- 部分收集(Partial GC)
- 整堆收集(Full GC)——针对整个堆结构和方法区的垃圾回收
其中部分收集又分为:
- 新生代收集(Minor GC / Young GC)——针对新生代的垃圾回收
- 老年代收集(Major GC / Old GC)——针对老年代的垃圾回收
- 混合收集(Mixed GC)——针对整个新生代以及部分老年代的垃圾回收
前面也提到了,对于Minor GC,只有当新生代中的Eden区满时才会触发,Survivor区满是不会触发GC的,Minor GC会将Eden区进行清空同时也会回收Survivor区中的垃圾;注意Minor GC会引发STW(Stop The World),即:Minor GC在进行垃圾回收时会暂停其它用户线程,等垃圾回收结束,用户线程才恢复运行。
而对于Major GC,只有当老年代内存不足时才会触发该GC,而通常情况下,Major GC触发之前会伴随着至少一次的Minor GC,这是因为在老年代空间满了之后,会先尝试触发Minor GC,当Minor GC结束后空间仍然不足,则会触发Major GC(但这也并不是绝对的,比如在Parallel Scavenge收集器的收集策略中就有直接进行Major GC的策略选择)。Major GC的速度一般会比Minor GC慢10倍甚至更多,STW的时间也会更长,当Major GC后空间仍然不足时,就会产生OutOfMemoryError 。
最后是Full GC,它触发的情况有以下五种:
- 调用System类的gc()方法,但这只是告诉JVM应该进行GC,并不代表JVM会立马执行Full GC
- 老年代内存不足
- 方法区内存不足
- Minor GC过后进行老年代的平均大小 大于 老年代的可用内存
- 由Eden区、From区向To区复制时,对象大小大于To区可用内存,则把该对象晋升到老年代,而老年代也没有足够的内存存放该对象
细心的同学应该发现了,对于两块幸存区,有时候叫它S0和S1,而有时候又叫他们From和To,这是什么情况呢?
事实上,S0就是From区,S1就是To区,但由于复制-清除算法的过程,它会将第一次Minor GC后存活的对象放入From区,此时To区是空的;当第二次Minor GC时,垃圾回收器会扫描Eden区和From区,并将还存活的对象放入To区,然后清空Eden和From区,此时From区会和To区做一个交换,这样空的From区就会作为下一次GC的To区继续放置存活的对象,即:复制之后有交换,谁空谁就做To区 。
因为Full GC覆盖的范围比较广,损耗的时间也是比较长的,所以在开发中应该尽量避免Full GC的发生。
下面例举一些堆中常用的设置参数:
-XX:+PrintFlagsInitial:查看所有的参数默认值-XX:+PrintFlagsFinal:查看所有的参数最终值-Xms:设置初始堆内存-Xmx:设置最大堆内存-Xmn:设置新生代的内存-XX:NewRatio:配置新生代与老年代在堆结构的占比-XX:SurvivorRatio:配置新生代中Eden区与Survivor区的占比-XX:MaxTenuringThreshold:设置新生代垃圾的最大年龄-XX:+PrintGCDetails:输出GC的详细日志堆是分配对象存储的唯一选择吗?
说到对象的内存分配,理所当然地会认为对象是在堆中分配内存的,那么它是对象存储的唯一选择吗?答案是否定的,它有一种特殊情况,即:如果经过逃逸分析 后发现,一个对象并没有逃逸出方法的话,那么就可能被优化成栈上分配,这样就无需在堆上分配内存,那么什么又是逃逸分析呢?逃逸分析的基本行为是分析对象的动态作用域:
- 当一个对象在方法中被定义后,对象只在方法内部使用,则认为没有发生逃逸
当一个对象在方法中被定义后,它被外部方法所引用,则认为发生逃逸,例如:作为调用参数传递到其它方法中
public void test(){User user = new User();}
在这样的一个方法中,User对象在方法内部创建,外部方法没有使用到该对象,而且该对象也没有提供给外部访问,因此该对象是没有逃逸出方法的,可以将该对象放在栈上分配内存, 此时它与栈帧共存亡,当创建栈帧后,User对象随着被分配内存,栈帧被压入虚拟机栈,方法调用结束后,栈帧被弹出虚拟机栈,User对象也随之消亡了。
public StringBuffer test(){StringBuffer sb = new StringBuffer();sb.append("hello");sb.append("world");return sb;}
在这段程序中,因为该方法将内部的StringBuffer对象作为返回值提供给外部使用了,所以该对象是发生了逃逸的,那么它就不能放在栈上分配内存,可以改进一下这个程序,使其内部对象不发生逃逸:
public String test(){StringBuffer sb = new StringBuffer();sb.append("hello");sb.append("world");return sb.toString();}
但事实上,HotSpot虚拟机并未实现这一点,它是通过标量替换的方式来提升性能,意思是:
某些对象可能不需要作为一个连续的内存结构存在也可以被访问,那么对象的部分或全部就可以不存储在堆中,而是存储在栈中
这里需要理解两个概念:标量:指的是一个无法再被分解的数据,Java中的原始数据就是标量
- 聚合量:可以被细分成更小数据的数据称为聚合量,比如Java中的对象
比如:
public static void main(String[] args){User user = new User("zhangsan",20);}class User{private String name;private Integer id;public User(String name,Integer age){this.name = name;this.age = age;}}
首先对User对象进行逃逸分析,发现该对象并不会发生逃逸,所以可以考虑对其进行标量替换,即:将聚合量肢解成标量:
public static void main(String[] args){String name = "zhangsan";Integer age = 20;}
此时这些数据就会被放置在栈帧中的局部变量表中,无需考虑GC问题,也就提升了性能。
既然标量替换只是将聚合量替换成了标量,那么对于最开始的问题:堆是不是分配对象存储的唯一选择,答案就是肯定的了,聚合量被替换后已经不是对象了,它是以一种特殊的方式将”对象”存储在栈上,注意这个对象打了引号,其实栈上存储的并不是对象,而是对象肢解后的标量,所以对象还是只能存储在堆上,只能期待这方面的技术成熟,能够真正实现对象在栈上的存储。

若有收获,就点个赞吧
0 人点赞
