Java
在使用POI进行excel操作时,当数据量较大时经常会产生内存溢出异常。下面通过分析如何解决该问题
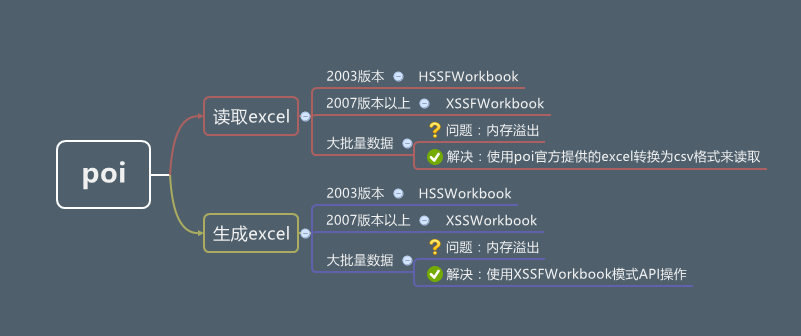
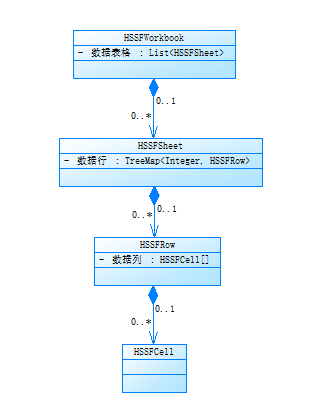
一、POI结构图
二、内存溢出问题
在项目中遇到二十万行数据要写入到excel中时会内存溢出,一般方法是调大tomcat的内存,但是调到2048M还是会内存溢出报错。因此分析其原因。
通过分析其源码,得出其实现步骤为通过InputStream一行行读取到TreeMap类型的HSSFRow结构体中,因此当数据量大时就会造成内存溢出。
public HSSFWorkbook(DirectoryNode directory, boolean preserveNodes)throws IOException{super(directory);String workbookName = getWorkbookDirEntryName(directory);this.preserveNodes = preserveNodes;// If we're not preserving nodes, don't track the// POIFS any moreif(! preserveNodes) {clearDirectory();}_sheets = new ArrayList<HSSFSheet>(INITIAL_CAPACITY);names = new ArrayList<HSSFName>(INITIAL_CAPACITY);// Grab the data from the workbook stream, however// it happens to be spelled.InputStream stream = directory.createDocumentInputStream(workbookName);List<Record> records = RecordFactory.createRecords(stream);workbook = InternalWorkbook.createWorkbook(records);setPropertiesFromWorkbook(workbook);int recOffset = workbook.getNumRecords();// convert all LabelRecord records to LabelSSTRecordconvertLabelRecords(records, recOffset);RecordStream rs = new RecordStream(records, recOffset);while (rs.hasNext()) {try {InternalSheet sheet = InternalSheet.createSheet(rs);_sheets.add(new HSSFSheet(this, sheet));} catch (UnsupportedBOFType eb) {// Hopefully there's a supported one after this!log.log(POILogger.WARN, "Unsupported BOF found of type " + eb.getType());}}for (int i = 0 ; i < workbook.getNumNames() ; ++i){NameRecord nameRecord = workbook.getNameRecord(i);HSSFName name = new HSSFName(this, nameRecord, workbook.getNameCommentRecord(nameRecord));names.add(name);}}/*** add a row to the sheet** @param addLow whether to add the row to the low level model - false if its already there*/private void addRow(HSSFRow row, boolean addLow) {_rows.put(Integer.valueOf(row.getRowNum()), row);if (addLow) {_sheet.addRow(row.getRowRecord());}boolean firstRow = _rows.size() == 1;if (row.getRowNum() > getLastRowNum() || firstRow) {_lastrow = row.getRowNum();}if (row.getRowNum() < getFirstRowNum() || firstRow) {_firstrow = row.getRowNum();}}
三、解决方案
poi官网给了一种大批量数据写入的方法,使用SXXFWorkbook类进行大批量写入操作解决了这个问题,可以监控该样例,会发现整体内存呈现锯齿状,能够及时回收,内存相对比较平稳。
package org.bird.poi;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.net.URL;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.Row;import org.apache.poi.ss.usermodel.Sheet;import org.apache.poi.ss.util.CellReference;import org.apache.poi.xssf.streaming.SXSSFWorkbook;import org.junit.Assert;public class XSSFWriter {private static SXSSFWorkbook wb;public static void main(String[] args) throws IOException {wb = new SXSSFWorkbook(10000);Sheet sh = wb.createSheet();for(int rownum = 0; rownum < 100000; rownum++){Row row = sh.createRow(rownum);for(int cellnum = 0; cellnum < 10; cellnum++){Cell cell = row.createCell(cellnum);String address = new CellReference(cell).formatAsString();cell.setCellValue(address);}}// Rows with rownum < 900 are flushed and not accessiblefor(int rownum = 0; rownum < 90000; rownum++){Assert.assertNull(sh.getRow(rownum));}// ther last 100 rows are still in memoryfor(int rownum = 90000; rownum < 100000; rownum++){Assert.assertNotNull(sh.getRow(rownum));}URL url = XSSFWriter.class.getClassLoader().getResource("");FileOutputStream out = new FileOutputStream(url.getPath() + File.separator + "wirter.xlsx");wb.write(out);out.close();// dispose of temporary files backing this workbook on diskwb.dispose();}}


若有收获,就点个赞吧
0 人点赞
