Java14新特性预览
switch表达式instanceof增强表达式,预览功能- 文本块,第二次预览
Records,预览功能

1、instanceof(预览)
Java 14 中对 instanceof 的改进,主要目的是为了让创建对象更简单、简洁和高效,并且可读性更强、提高安全性。
在以往实际使用中,instanceof 主要用来检查对象的类型,然后根据类型对目标对象进行类型转换,之后进行不同的处理、实现不同的逻辑。
按照新特性的顺序,先从 instanceof。旧式的 instanceof 的用法如下所示:
public class OldInstanceOf {public static void main(String[] args) {Object str = "Java 14,真香";if (str instanceof String) {String s = (String)str;System.out.println(s.length());}}}
需要先使用 instanceof 在 if 条件中判断 str 的类型是否为 String(第一步),再在 if 语句中将 str 强转为字符串类型(第二步),并且要重新声明一个变量用于强转后的赋值(第三步)。
上面这种写法,有下面两个问题:
- 每次在检查类型之后,都需要强制进行类型转换。
- 类型转换后,需要提前创建一个局部变量来接收转换后的结果,代码显得多余且繁琐。
Java 14 中,对 instanceof 进行模式匹配改进之后,上面示例代码可以改写成:
public class NewInstanceOf {public static void main(String[] args) {Object str = "Java 14,真香";if (str instanceof String s) {System.out.println(s.length());}}}
可以直接在 if 条件判断类型的时候添加一个变量,就不需要再强转和声明新的变量了。但模式匹配的 instanceof 在 Java 14 中是预览版的,默认是不启用的,所以这段代码会有一个奇怪的编译错误(Java 14 中不支持模式匹配的 instanceof)。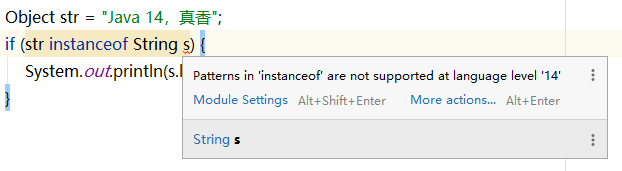
需要在项目配置中手动设置一下语言的版本。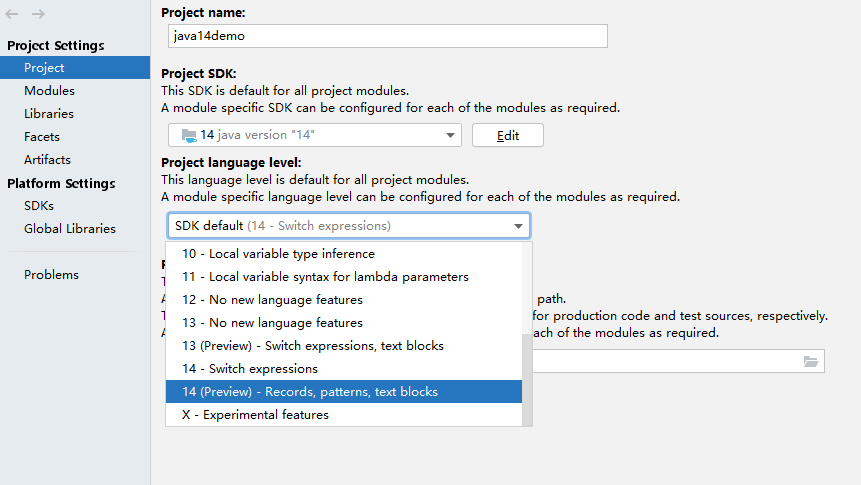
设置完成后,编译错误就不见了。程序输出的结果如下所示:
10
反编译后的字节码就知道Java14底层做了什么。
public class NewInstanceOf {public NewInstanceOf() {}public static void main(String[] args) {Object str = "Java 14,真香";String s;if (str instanceof String && (s = (String)str) == (String)str) {System.out.println(s.length());}}}
在 if 条件判断前,先声明了变量 s,然后在 if 条件中进行了强转 s = (String)str),并且判断了 s 和 str 是否相等。
意,如果 if 条件中有 && 运算符时,当 instanceof 类型匹配成功,模式局部变量的作用范围也可以相应延长,如下面代码:
if (obj instanceof String s && s.length() > 5) {.. s.contains(..) ..}
另外,需要注意,这种作用范围延长,并不适用于或 || 运算符,因为即便 || 运算符左边的 instanceof 类型匹配没有成功也不会造成短路,依旧会执行到||运算符右边的表达式,但是此时,因为 instanceof 类型匹配没有成功,局部变量并未定义赋值,此时使用会产生问题。
与传统写法对比,可以发现模式匹配不但提高了程序的安全性、健壮性,另一方面,不需要显式的去进行二次类型转换,减少了大量不必要的强制类型转换。模式匹配变量在模式匹配成功之后,可以直接使用,同时它还被限制了作用范围,大大提高了程序的简洁性、可读性和安全性。instanceof 的模式匹配,为 Java 带来的有一次便捷的提升,能够剔除一些冗余的代码,写出更加简洁安全的代码,提高码代码效率。
2、Records(预览)
在以往开发过程中,被当作数据载体的类对象,在正确声明定义过程中,通常需要编写大量的无实际业务、重复性质的代码,其中包括:构造函数、属性调用、访问以及 equals() 、hashCode()、toString() 等方法,因此在 Java 14 中引入了 Record 类型,其效果有些类似 Lombok 的 @Data 注解、Kotlin 中的 data class,但是又不尽完全相同,它们的共同点都是类的部分或者全部可以直接在类头中定义、描述,并且这个类只用于存储数据而已。
新增的 record 类型,干掉复杂的 POJO 类
一般创建一个 POJO 类,需要定义属性列表,构造函数,getter/setter,比较麻烦。JAVA 14 带来了一个便捷的创建类的方式 - record
Java 14 富有建设性地将 Record 类型作为预览特性而引入。Record 类型允许在代码中使用紧凑的语法形式来声明类,而这些类能够作为不可变数据类型的封装持有者。Record 这一特性主要用在特定领域的类上;与枚举类型一样,Record 类型是一种受限形式的类型,主要用于存储、保存数据,并且没有其它额外自定义行为的场景下。
简化数据类的定义方式,使用 record 代替 class 定义的类,只需要声明属性,就可以在获得属性的访问方法,以及 toString(),hashCode(), equals()方法
类似于使用 class 定义类,同时使用了 lombok 插件,并打上了@Getter,@ToString,@EqualsAndHashCode注解
/*** 这个类具有两个特征* 1. 所有成员属性都是final* 2. 全部方法由构造方法,和两个成员属性访问器组成(共三个)* 那么这种类就很适合使用record来声明*/final class Rectangle implements Shape {final double length;final double width;public Rectangle(double length, double width) {this.length = length;this.width = width;}double length() { return length; }double width() { return width; }}/*** 1. 使用record声明的类会自动拥有上面类中的三个方法* 2. 在这基础上还附赠了equals(),hashCode()方法以及toString()方法* 3. toString方法中包括所有成员属性的字符串表示形式及其名称*/record Rectangle(float length, float width) { }
public record UserDTO(String id,String nickname,String homepage) { };public static void main( String[] args ){UserDTO user = new UserDTO("213", "Hello", "World");System.out.println(user.id);System.out.println(user.nickname);System.out.println(user.id);}
IDEA 也早已支持了这个功能,创建类的时候直接就可以选:
「不过这个只是一个语法糖,编译后还是一个 Class,和普通的 Class 区别不大」
类的不可变性
public final class Writer {private final String name;private final int age;public Writer(String name, int age) {this.name = name;this.age = age;}public int getAge() {return age;}public String getName() {return name;}}
那么,对于 Records 来说,一条 Record 就代表一个不变的状态。尽管它会提供诸如 equals()、hashCode()、toString()、构造方法,以及字段的 getter,但它无意替代可变对象的类(没有 setter),以及 Lombok 提供的功能。
用 Records 替代一下上面这个 Writer 类:
public record Writer(String name, int age) { }
一行代码就搞定。比之前的代码功能更丰富,看一下反编译后的字节码:
public final class Writer extends java.lang.Record {private final java.lang.String name;private final int age;public Writer(java.lang.String name, int age) { /* compiled code */ }public java.lang.String toString() { /* compiled code */ }public final int hashCode() { /* compiled code */ }public final boolean equals(java.lang.Object o) { /* compiled code */ }public java.lang.String name() { /* compiled code */ }public int age() { /* compiled code */ }}
根据反编译结果,可以得出,当用 Record 来声明一个类时,该类将自动拥有下面特征:
- 拥有一个构造方法
- 获取成员属性值的方法:
name()、age() hashCode()方法和euqals()方法toString()方法- 类对象和属性被 final 关键字修饰,不能被继承,类的示例属性也都被
final修饰,不能再被赋值使用。 - 还可以在 Record 声明的类中定义静态属性、方法和示例方法。注意,不能在 Record 声明的类中定义示例字段,类也不能声明为抽象类等。
可以看到,该预览特性提供了一种更为紧凑的语法来声明类,并且可以大幅减少定义类似数据类型时所需的重复性代码。
类是 final 的,字段是 private final 的,构造方法有两个参数,toString()、hashCode()、equals() 方法也有了,getter 方法也有了,只不过没有 get 前缀。但是没有 setter 方法,也就是说 Records 确实针对的是不可变对象。那怎么使用 Records 呢?
public class WriterDemo {public static void main(String[] args) {Writer writer = new Writer("Fcant",18);System.out.println("toString:" + writer);System.out.println("hashCode:" + writer.hashCode());System.out.println("name:" + writer.name());System.out.println("age:" + writer.age());Writer writer1 = new Writer("Fcant", 18);System.out.println("equals:" + (writer.equals(writer1)));}}
程序输出的结果如下所示:
toString:Writer[name=Fcant, age=18]hashCode:1130697218name:Fcantage:18equals:true
定义不可变类时就简单了。
另外 Java 14 中为了引入 Record 这种新的类型,在 java.lang.Class 中引入了下面两个新方法:
RecordComponent[] getRecordComponents()boolean isRecord()
其中 getRecordComponents() 方法返回一组 java.lang.reflect.RecordComponent 对象组成的数组,java.lang.reflect.RecordComponent也是一个新引入类,该数组的元素与 Record 类中的组件相对应,其顺序与在记录声明中出现的顺序相同,可以从该数组中的每个 RecordComponent 中提取到组件信息,包括其名称、类型、泛型类型、注释及其访问方法。
而 isRecord() 方法,则返回所在类是否是 Record 类型,如果是,则返回 true。
3、switch 表达式(稳定版)
Java12 引入的 switch(预览特性)在 Java14 变为正式版本,不需要增加参数来启用,直接在 JDK14 中就能使用。
Java12 为 switch 表达式引入了类似 lambda 语法条件匹配成功后的执行块,不需要多写 break ,Java13 提供了 yield 来在 block 中返回值。switch新的表达式有两个显著的特点:
- 支持箭头表达式返回
- 支持
yield和return返回值。
switch 表达式带来的不仅仅是编码上的简洁、流畅,也精简了 switch 语句的使用方式,同时也兼容之前的 switch 语句的使用;之前使用 switch 语句时,在每个分支结束之前,往往都需要加上 break 关键字进行分支跳出,以防 switch 语句一直往后执行到整个 switch 语句结束,由此造成一些意想不到的问题。switch 语句一般使用冒号 :来作为语句分支代码的开始,而 switch 表达式则提供了新的分支切换方式,即 -> 符号右则表达式方法体在执行完分支方法之后,自动结束 switch 分支,同时 -> 右则方法块中可以是表达式、代码块或者是手动抛出的异常。以往的 switch 语句写法如下:
int dayOfWeek;switch (day) {case MONDAY:case FRIDAY:case SUNDAY:dayOfWeek = 6;break;case TUESDAY:dayOfWeek = 7;break;case THURSDAY:case SATURDAY:dayOfWeek = 8;break;case WEDNESDAY:dayOfWeek = 9;break;default:dayOfWeek = 0;break;}
而现在 Java 14 可以使用 switch 表达式正式版之后,上面语句可以转换为下列写法:
int dayOfWeek = switch (day) {case MONDAY, FRIDAY, SUNDAY -> 6;case TUESDAY -> 7;case THURSDAY, SATURDAY -> 8;case WEDNESDAY -> 9;default -> 0;};
很明显,switch 表达式将之前 switch 语句从编码方式上简化了不少,但是还是需要注意下面几点:
- 需要保持与之前 switch 语句同样的 case 分支情况。
- 之前需要用变量来接收返回值,而现在直接使用 yield 关键字来返回 case 分支需要返回的结果。
- 现在的 switch 表达式中不再需要显式地使用 return、break 或者 continue 来跳出当前分支。
- 现在不需要像之前一样,在每个分支结束之前加上 break 关键字来结束当前分支,如果不加,则会默认往后执行,直到遇到 break 关键字或者整个 switch 语句结束,在 Java 14 表达式中,表达式默认执行完之后自动跳出,不会继续往后执行。
- 对于多个相同的 case 方法块,可以将 case 条件并列,而不需要像之前一样,通过每个 case 后面故意不加 break 关键字来使用相同方法块。
使用 switch 表达式来替换之前的 switch 语句,确实精简了不少代码,提高了编码效率,同时也可以规避一些可能由于不太经意而出现的意想不到的情况,可见 Java 在提高使用者编码效率、编码体验和简化使用方面一直在不停的努力中,同时也期待未来有更多的类似 lambda、switch 表达式这样的新特性出来。
1、箭头表达式(Lambda表达式)返回
JDK14之前写法:
private static void printLetterCount(DayOfWeek dayOfWeek){switch (dayOfWeek) {case MONDAY:case FRIDAY:case SUNDAY:System.out.println(6);break;case TUESDAY:System.out.println(7);break;case THURSDAY:case SATURDAY:System.out.println(8);break;case WEDNESDAY:System.out.println(9);break;}}
:::danger 要点:break可千万别忘记写,否则就是个大bug,并且还比较 「隐蔽」,定位起来稍显困难。 ::: JDK14等效的新写法:
private static void printLetterCount(DayOfWeek dayOfWeek){switch (dayOfWeek) {case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);case TUESDAY -> System.out.println(7);case THURSDAY, SATURDAY -> System.out.println(8);case WEDNESDAY -> System.out.println(9);}}
可明显看到新写法不需要一个个break了,从 「语法层面」 规避了犯错的可能性。
2、yield返回
JDK14之前写法:
private static int getLetterCount(DayOfWeek dayOfWeek){int letterCount;switch (dayOfWeek) {case MONDAY:case FRIDAY:case SUNDAY:letterCount = 6;break;case TUESDAY:letterCount = 7;break;case THURSDAY:case SATURDAY:letterCount = 8;break;case WEDNESDAY:letterCount = 9;break;default:throw new IllegalStateException("非法: " + dayOfWeek);}return letterCount;}
JDK14等效的新写法:
private static int getLetterCount(DayOfWeek dayOfWeek){return switch (dayOfWeek) {case MONDAY, FRIDAY, SUNDAY -> 6;case TUESDAY -> 7;case THURSDAY, SATURDAY -> 8;case WEDNESDAY -> 9;};}
使用箭头操作符操作效果立竿见影。当然,还可以使用yield关键字返回:
private static int getLetterCount(DayOfWeek dayOfWeek){return switch (dayOfWeek) {case MONDAY -> 6;default -> {int letterCount = dayOfWeek.toString().length();yield letterCount;}};}
4、Text Blocks(二次预览)
Java 13 引入了文本块来解决多行文本的问题,文本块主要以三重双引号开头,并以同样的以三重双引号结尾终止,它们之间的任何内容都被解释为文本块字符串的一部分,包括换行符,避免了对大多数转义序列的需要,并且它仍然是普通的 java.lang.String 对象,文本块可以在 Java 中能够使用字符串的任何地方进行使用,而与编译后的代码没有区别,还增强了 Java 程序中的字符串可读性。并且通过这种方式,可以更直观地表示字符串,可以支持跨越多行,而且不会出现转义的视觉混乱,将可以广泛提高 Java 类程序的可读性和可写性。
在文本块(Text Blocks)出现之前,如果需要拼接多行的字符串,就需要很多英文双引号和加号,看起来非常不雅。如果恰好要拼接一些 HTML 格式的文本(原生 SQL 也是如此)的话,还要通过空格进行排版,通过换行转义符 \n 进行换行,这些繁琐的工作对于一名开发人员来说,简直就是灾难。
public class OldTextBlock {public static void main(String[] args) {String html = "<html>\n" +" <body>\n" +" <p>Hello, world</p>\n" +" </body>\n" +"</html>\n";System.out.println(html);}}
Java 14 就完全不同了:
public class NewTextBlock {public static void main(String[] args) {String html = """<html><body><p>Hello, world</p></body></html>""";System.out.println(html);}}
多余的英文双引号、加号、换行转义符,统统不见了。仅仅是通过前后三个英文双引号就实现了。
Java14 中,文本块依然是预览特性,不过,其引入了两个新的转义字符:
\:表示行尾,不引入换行符,主要用于阻止插入换行符;\s:表示单个空格,可以用来避免末尾的白字符被去掉。 ```java String str = “凡心所向,素履所往,生如逆旅,一苇以航。”;
String str2 = “”” 凡心所向,素履所往, \ 生如逆旅,一苇以航。”””; System.out.println(str2);// 凡心所向,素履所往, 生如逆旅,一苇以航。 String text = “”” java c++\sphp “””; System.out.println(text); //输出: java c++ php
:::info这个特性可是非常好用,它属于二次预览:已在JDK 13预览过一次。:::```javapublic static void main(String[] args) {String html = """<html><body><p>hello world</p></body></html>""";String query = """SELECT * from USERWHERE `id` = 1ORDER BY `id`, `name`;""";}
:::tips 在JDK13中,这种是「有」换行的。在JDK14中,可以加上一个符号让其不让换行: :::
public static void main(String[] args) {String query = """SELECT * from USER \WHERE `id` = 1 \ORDER BY `id`, `name`;\""";System.out.println(query);}
Java 14 带来的这两个转义符,能够简化跨多行字符串编码问题,通过转义符,能够避免对换行等特殊字符串进行转移,从而简化代码编写,同时也增强了使用 String 来表达 HTML、XML、SQL 或 JSON 等格式字符串的编码可读性,且易于维护。
同时 Java 14 还对 String 进行了方法扩展:
stripIndent():用于从文本块中去除空白字符translateEscapes():用于翻译转义字符formatted(Object... args):用于格式化5、删除CMS垃圾收集器(删除)
这款著名的垃圾回收器从这个版本就彻底被删除了。JDK9开始使用G1作为 「默认」 的垃圾回收器(JDK11中ZGC开始崭露头角),就已经把CMS标记为过期了,在此版本正式删除。
CMS 是老年代垃圾回收算法,通过标记-清除的方式进行内存回收,在内存回收过程中能够与用户线程并行执行。CMS 回收器可以与 Serial 回收器和 Parallel New 回收器搭配使用,CMS 主要通过并发的方式,适当减少系统的吞吐量以达到追求响应速度的目的,比较适合在追求 GC 速度的服务器上使用。
因为 CMS 回收算法在进行 GC 回收内存过程中是使用并行方式进行的,如果服务器 CPU 核数不多的情况下,进行 CMS 垃圾回收有可能造成比较高的负载。同时在 CMS 并行标记和并行清理时,应用线程还在继续运行,程序在运行过程中自然会创建新对象、释放不用对象,所以在这个过程中,会有新的不可达内存地址产生,而这部分的不可达内存是出现在标记过程结束之后,本轮 CMS 回收无法在周期内将它们回收掉,只能留在下次垃圾回收周期再清理掉。这样的垃圾就叫做浮动垃圾。由于垃圾收集和用户线程是并发执行的,因此 CMS 回收器不能像其他回收器那样进行内存回收,需要预留一些空间用来保存用户新创建的对象。由于 CMS 回收器在老年代中使用标记-清除的内存回收策略,势必会产生内存碎片,内存当碎片过多时,将会给大对象分配带来麻烦,往往会出现老年代还有空间但不能再保存对象的情况。
所以,早在几年前的 Java 9 中,就已经决定放弃使用 CMS 回收器了,而这次在 Java 14 中,是继之前 Java 9 中放弃使用 CMS 之后,彻底将其禁用,并删除与 CMS 有关的选项,同时清除与 CMS 有关的文档内容,至此曾经辉煌一度的 CMS 回收器,也将成为历史。
当在 Java 14 版本中,通过使用参数:-XX:+UseConcMarkSweepGC,尝试使用 CMS 时,将会收到下面信息:Java HotSpot(TM) 64-Bit Server VM warning: Ignoring option UseConcMarkSweepGC; \support was removed in <version>
6、ZGC垃圾回收器支持 MacOS 和 Windows 系统(实验)
革命性的ZGC:任意堆大小(TB级别)都能保证延迟在10ms以内,是以低延迟为首要目标的一款垃圾回收器。在JDK14之前,ZGC只能用于Linux上,现在也可使用在windows上了
ZGC 是最初在 Java 11 中引入,同时在后续几个版本中,不断进行改进的一款基于内存 Region,同时使用了内存读屏障、染色指针和内存多重映射等技,并且以可伸缩、低延迟为目标的内存垃圾回收器器,不过在 Java 14 之前版本中,仅仅只支持在 Linux/x64 位平台。
此次 Java 14,同时支持 MacOS 和 Windows 系统,解决了开发人员需要在桌面操作系统中使用 ZGC 的问题。
在 MacOS 和 Windows 下面开启 ZGC 的方式,需要添加如下 JVM 参数:
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC
7、G1 的 NUMA 可识别内存分配:改进 NullPointerExceptions提示信息
Java 14 改进非一致性内存访问(NUMA)系统上的 G1 垃圾收集器的整体性能,主要是对年轻代的内存分配进行优化,从而提高 CPU 计算过程中内存访问速度。
NUMA 是 non-unified memory access 的缩写,主要是指在当前的多插槽物理计算机体系中,比较普遍是多核的处理器,并且越来越多的具有 NUMA 内存访问体系结构,即内存与每个插槽或内核之间的距离并不相等。同时套接字之间的内存访问具有不同的性能特征,对更远的套接字的访问通常具有更多的时间消耗。这样每个核对于每一块或者某一区域的内存访问速度会随着核和物理内存所在的位置的远近而有不同的时延差异。
Java 中,堆内存分配一般发生在线程运行的时候,当创建了一个新对象时,该线程会触发 G1 去分配一块内存出来,用来存放新创建的对象,在 G1 内存体系中,其实就是一块 region(大对象除外,大对象需要多个 region),在这个分配新内存的过程中,如果支持了 NUMA 感知内存分配,将会优先在与当前线程所绑定的 NUMA 节点空闲内存区域来执行 allocate 操作,同一线程创建的对象,尽可能的保留在年轻代的同一 NUMA 内存节点上,因为是基于同一个线程创建的对象大部分是短存活并且高概率互相调用的。
具体启用方式可以在 JVM 参数后面加上如下参数:
-XX:+UseNUMA
通过这种方式来启用可识别的内存分配方式,能够提高一些大型计算机的 G1 内存分配回收性能。改进 NullPointerExceptions 提示信息
Java 14 改进 NullPointerException 的可查性、可读性,能更准确地定位 null 变量的信息。该特性能够帮助开发者和技术支持人员提高生产力,以及改进各种开发工具和调试工具的质量,能够更加准确、清楚地根据动态异常与程序代码相结合来理解程序。
相信每位开发者在实际编码过程中都遇到过 NullPointerException,每当遇到这种异常的时候,都需要根据打印出来的详细信息来分析、定位出现问题的原因,以在程序代码中规避或解决。例如,假设下面代码出现了一个 NullPointerException:
Java 14 之前:
String name = song.getSinger().getSingerName()//堆栈信息Exception in thread "main" java.lang.NullPointerExceptionat NullPointerExample.main(NullPointerTest.java:6)
像上面这种异常,因为代码比较简单,并且异常信息中也打印出来了行号信息,可以很快速定位到出现异常位置,而对于一些复杂或者嵌套的情况下出现 NullPointerException 时,仅根据打印出来的信息,很难判断实际出现问题的位置,对于这种比较复杂的情况下,仅仅单根据异常信息中打印的行号,则比较难判断出现 NullPointerException 的原因。
而 Java 14 中,则做了对 NullPointerException 打印异常信息的改进增强,通过分析程序的字节码信息,能够做到准确的定位到出现 NullPointerException 的变量,并且根据实际源代码打印出详细异常信息。
Java 14,通过引入JVM 参数-XX:+ShowCodeDetailsInExceptionMessages,可以在空指针异常中获取更为详细的调用信息。
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "Singer.getSingerName()"because the return value of "rainRow.getSinger()" is nullat NullPointerExample.main(NullPointerTest.java:6)
比如下面这个例子中,到底是 innerMap 为空呢,还是 effected 为空呢?
Map<String,Map<String,Boolean>> wrapMap = new HashMap<>();wrapMap.put("innerMap",new HashMap<>());boolean effected = wrapMap.get("innerMap").get("effected");// StackTrace:Exception in thread "main" java.lang.NullPointerExceptionat org.example.App.main(App.java:50)
JAVA 14 优化了 NullPointerException 的提示,一眼就能定位到底“空”在哪!
Exception in thread "main" java.lang.NullPointerException: Cannot invoke "java.lang.Boolean.booleanValue()" because the return value of "java.util.Map.get(Object)" is nullat org.example.App.main(App.java:50)
现在的 StackTrace 就很直观了,直接告诉 effected 变量为空,再也不用困惑!该增强改进特性,不仅适用于属性访问,还适用于方法调用、数组访问和赋值等有可能会导致 NullPointerException 的地方。
8、安全的堆外内存读写接口,别再玩 Unsafe 的操作了
在之前的版本中,JAVA 如果想操作堆外内存(DirectBuffer),还得 Unsafe 各种 copy/get/offset。现在直接增加了一套安全的堆外内存访问接口,可以轻松的访问堆外内存,再也不用搞 Unsafe 的操作了。
// 分配 200B 堆外内存MemorySegment memorySegment = MemorySegment.allocateNative(200);// 用 ByteBuffer 分配,然后包装为 MemorySegmentMemorySegment memorySegment = MemorySegment.ofByteBuffer(ByteBuffer.allocateDirect(200));// MMAP 当然也可以MemorySegment memorySegment = MemorySegment.mapFromPath(Path.of("/tmp/memory.txt"), 200, FileChannel.MapMode.READ_WRITE);// 获取堆外内存地址MemoryAddress address = MemorySegment.allocateNative(100).baseAddress();// 组合拳,堆外分配,堆外赋值long value = 10;MemoryAddress memoryAddress = MemorySegment.allocateNative(8).baseAddress();// 获取句柄VarHandle varHandle = MemoryHandles.varHandle(long.class, ByteOrder.nativeOrder());varHandle.set(memoryAddress, value);// 释放就这么简单,想想 DirectByteBuffer 的释放……多奇怪memorySegment.close();
9、新增的 jpackage 打包工具,直接打包二进制程序,再也不用装 JRE 了
之前如果想构建一个可执行的程序,还需要借助三方工具,将 JRE 一起打包,或者让客户电脑也装一个 JRE 才可以运行 JAVA 程序。
现在 JAVA 直接内置了 jpackage 打包工具,帮助一键打包二进制程序包。
10、弃用 ParallelScavenge 和 SerialOld GC 的组合使用
由于 Parallel Scavenge 和 Serial Old 垃圾收集算法组合起来使用的情况比较少,并且在年轻代中使用并行算法,而在老年代中使用串行算法,这种并行、串行混搭使用的情况,本身已属罕见同时也很冒险。由于这两 GC 算法组合很少使用,却要花费巨大工作量来进行维护,所以在 Java 14 版本中,考虑将这两 GC 的组合弃用。
具体弃用情况如下,通过弃用组合参数:-XX:+UseParallelGC -XX:-UseParallelOldGC,来弃用年轻代、老年期中并行、串行混搭使用的情况;同时,对于单独使用参数:-XX:-UseParallelOldGC 的地方,也将显示该参数已被弃用的警告信息。
11、其他特性
- G1 的 NUMA 可识别内存分配
- 删除 CMS 垃圾回收器
- GC 支持 MacOS 和 Windows 系统
- 从 Java11 引入的 ZGC 作为继 G1 过后的下一代 GC 算法,从支持 Linux 平台到 Java14 开始支持 MacOS 和 Window(终于可以在日常开发工具中先体验下 ZGC 的效果了,虽然其实 G1 也够用)
- 新增了 jpackage 工具,标配将应用打成 jar 包外,还支持不同平台的特性包,比如 linux 下的
deb和rpm,window 平台下的msi和exe

若有收获,就点个赞吧
0 人点赞
