Java Synchronized
在并发编程中Synchronized一直都是元老级的角色,Jdk 1.6以前大家都称呼它为重量级锁,相对于J U C包提供的Lock,它会显得笨重,不过随着Jdk 1.6对Synchronized进行各种优化后,Synchronized性能已经非常快了。
内容大纲
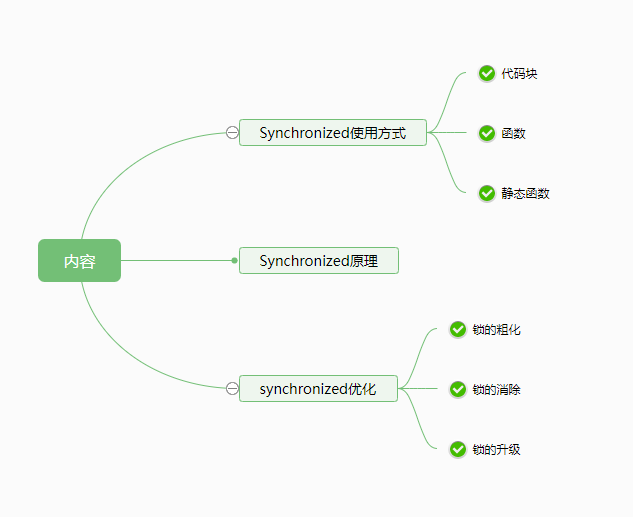
Synchronized使用方式
Synchronized是Java提供的同步关键字,在多线程场景下,对共享资源代码段进行读写操作(必须包含写操作,光读不会有线程安全问题,因为读操作天然具备线程安全特性),可能会出现线程安全问题,可以使用Synchronized锁定共享资源代码段,达到互斥(mutualexclusion)效果,保证线程安全。
共享资源代码段又称为临界区(critical section),保证临界区互斥,是指执行临界区(critical section)的只能有一个线程执行,其他线程阻塞等待,达到排队效果。
Synchronized的食用方式有三种
- 修饰普通函数,监视器锁(
monitor)便是对象实例(this) - 修饰静态静态函数,视器锁(
monitor)便是对象的Class实例(每个对象只有一个Class实例) -
普通函数
普通函数使用
Synchronized的方式很简单,在访问权限修饰符与函数返回类型间加上Synchronized。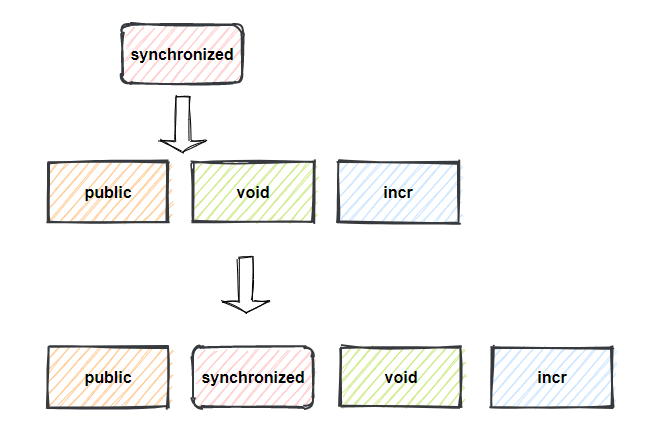
多线程场景下,thread与threadTwo两个线程执行incr函数,incr函数作为共享资源代码段被多线程读写操作,将它称为临界区,为了保证临界区互斥,使用Synchronized修饰incr函数即可。public class SyncTest {private int j = 0;/*** 自增方法*/public synchronized void incr(){//临界区代码--startfor (int i = 0; i < 10000; i++) {j++;}//临界区代码--end}public int getJ() {return j;}}public class SyncMain {public static void main(String[] agrs) throws InterruptedException {SyncTest syncTest = new SyncTest();Thread thread = new Thread(() -> syncTest.incr());Thread threadTwo = new Thread(() -> syncTest.incr());thread.start();threadTwo.start();thread.join();threadTwo.join();//最终打印结果是20000,如果不使用synchronized修饰,就会导致线程安全问题,输出不确定结果System.out.println(syncTest.getJ());}}
代码十分简单,
incr函数被synchronized修饰,函数逻辑是对j进行10000次累加,两个线程执行incr函数,最后输出j结果。
被synchronized修饰函数简称同步函数,线程执行称同步函数前,需要先获取监视器锁,简称锁,获取锁成功才能执行同步函数,同步函数执行完后,线程会释放锁并通知唤醒其他线程获取锁,获取锁失败「则阻塞并等待通知唤醒该线程重新获取锁」,同步函数会以this作为锁,即当前对象,以上面的代码段为例就是syncTest对象。
线程
thread执行syncTest.incr()前- 线程
thread获取锁成功 - 线程
threadTwo执行syncTest.incr()前 - 线程
threadTwo获取锁失败 - 线程
threadTwo阻塞并等待唤醒 - 线程
thread执行完syncTest.incr(),j累积到10000 - 线程
thread释放锁,通知唤醒threadTwo线程获取锁 - 线程
threadTwo获取锁成功 - 线程
threadTwo执行完syncTest.incr(),j累积到20000 -
静态函数
静态函数顾名思义,就是静态的函数,它使用
Synchronized的方式与普通函数一致,唯一的区别是锁的对象不再是this,而是Class对象。
多线程执行Synchronized修饰静态函数代码段如下。public class SyncTest {private static int j = 0;/*** 自增方法*/public static synchronized void incr(){//临界区代码--startfor (int i = 0; i < 10000; i++) {j++;}//临界区代码--end}public static int getJ() {return j;}}public class SyncMain {public static void main(String[] agrs) throws InterruptedException {Thread thread = new Thread(() -> SyncTest.incr());Thread threadTwo = new Thread(() -> SyncTest.incr());thread.start();threadTwo.start();thread.join();threadTwo.join();//最终打印结果是20000,如果不使用synchronized修饰,就会导致线程安全问题,输出不确定结果System.out.println(SyncTest.getJ());}}
Java的静态资源可以直接通过类名调用,静态资源不属于任何实例对象,它只属于Class对象,每个Class在J V M中只有唯一的一个Class对象,所以同步静态函数会以Class对象作为锁,后续获取锁、释放锁流程都一致。代码块
前面介绍的普通函数与静态函数粒度都比较大,以整个函数为范围锁定,现在想把范围缩小、灵活配置,就需要使用代码块了,使用
{}符号定义范围给Synchronized修饰。
下面代码中定义了syncDbData函数,syncDbData是一个伪同步数据的函数,耗时2秒,并且逻辑不涉及共享资源读写操作(非临界区),另外还有两个函数incr与incrTwo,都是在自增逻辑前执行了syncDbData函数,只是使用Synchronized的姿势不同,一个是修饰在函数上,另一个是修饰在代码块上。public class SyncTest {private static int j = 0;/*** 同步库数据,比较耗时,代码资源不涉及共享资源读写操作。*/public void syncDbData() {System.out.println("db数据开始同步------------");try {//同步时间需要2秒Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("db数据开始同步完成------------");}//自增方法public synchronized void incr() {//start--临界区代码//同步库数据syncDbData();for (int i = 0; i < 10000; i++) {j++;}//end--临界区代码}//自增方法public void incrTwo() {//同步库数据syncDbData();synchronized (this) {//start--临界区代码for (int i = 0; i < 10000; i++) {j++;}//end--临界区代码}}public int getJ() {return j;}}public class SyncMain {public static void main(String[] agrs) throws InterruptedException {//incr同步方法执行SyncTest syncTest = new SyncTest();Thread thread = new Thread(() -> syncTest.incr());Thread threadTwo = new Thread(() -> syncTest.incr());thread.start();threadTwo.start();thread.join();threadTwo.join();//最终打印结果是20000System.out.println(syncTest.getJ());//incrTwo同步块执行thread = new Thread(() -> syncTest.incrTwo());threadTwo = new Thread(() -> syncTest.incrTwo());thread.start();threadTwo.start();thread.join();threadTwo.join();//最终打印结果是40000System.out.println(syncTest.getJ());}}
先看看
incr同步方法执行,流程和前面没区别,只是Synchronized锁定的范围太大,把syncDbData()也纳入临界区中,多线程场景执行,会有性能上的浪费,因为syncDbData()完全可以让多线程并行或并发执行。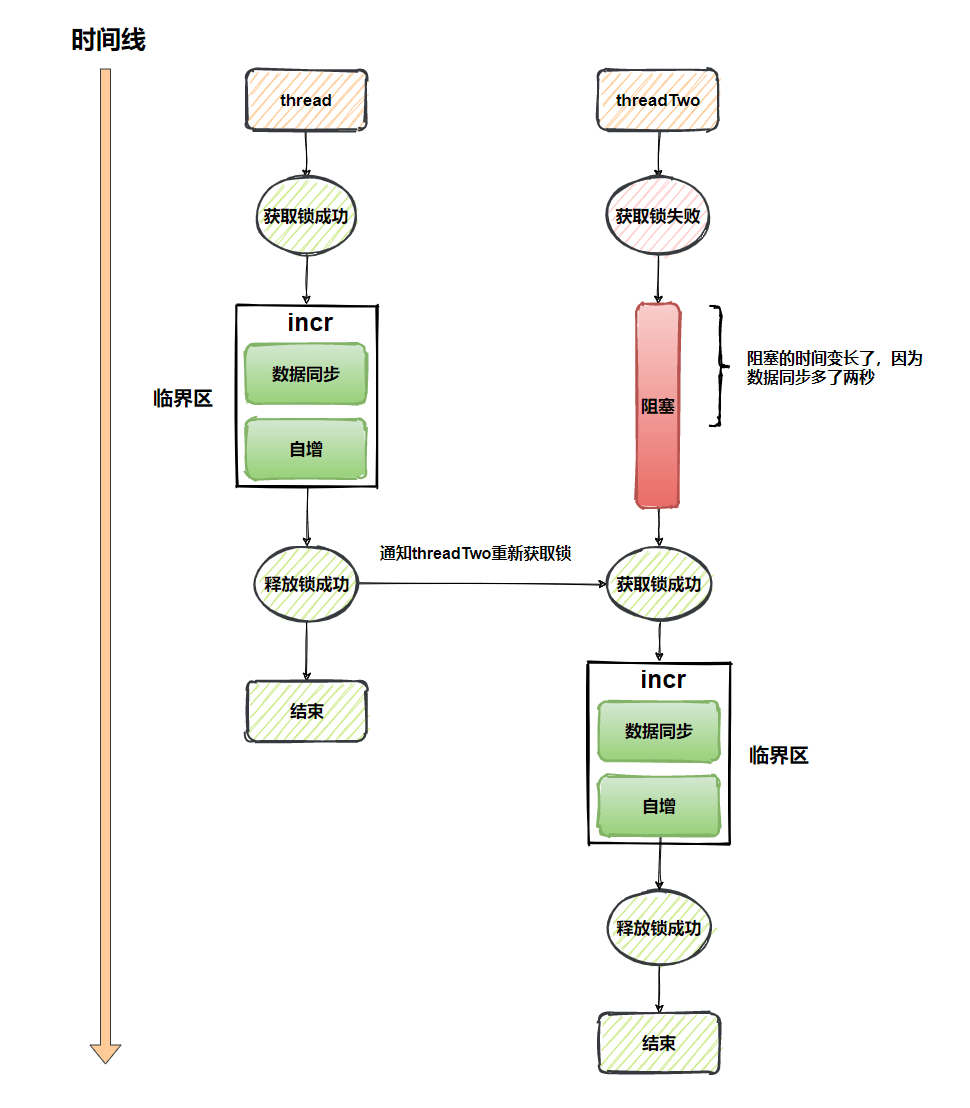
通过代码块的方式,来缩小范围,定义正确的临界区,提升性能,目光转到incrTwo同步块执行,incrTwo函数使用修饰代码块的方式同步,只对自增代码段进行锁定。
代码块同步方式除了灵活控制范围外,还能做线程间的协同工作,因为Synchronized ()括号中能接收任何对象作为锁,所以可以通过Object的wait、notify、notifyAll等函数,做多线程间的通信协同(这里不对线程通信协同做展开,主角是Synchronized,而且也不推荐去用这些方法,因为LockSupport工具类会是更好的选择)。 wait:当前线程暂停,释放锁
- notify:释放锁,唤醒调用了wait的线程(如果有多个随机唤醒一个)
-
Synchronized原理
public class SyncTest {private static int j = 0;/*** 同步库数据,比较耗时,代码资源不涉及共享资源读写操作。*/public void syncDbData() {System.out.println("db数据开始同步------------");try {//同步时间需要2秒Thread.sleep(2000);} catch (InterruptedException e) {e.printStackTrace();}System.out.println("db数据开始同步完成------------");}//自增方法public synchronized void incr() {//start--临界区代码//同步库数据syncDbData();for (int i = 0; i < 10000; i++) {j++;}//end--临界区代码}//自增方法public void incrTwo() {//同步库数据syncDbData();synchronized (this) {//start--临界区代码for (int i = 0; i < 10000; i++) {j++;}//end--临界区代码}}public int getJ() {return j;}}
为了探究
Synchronized原理,对上面的代码进行反编译,输出反编译后结果,看看底层是如何实现的(环境Java 11、win 10系统)。只截取了incr与incrTwo函数内容public synchronized void incr();Code:0: aload_01: invokevirtual #11 // Method syncDbData:()V4: iconst_05: istore_16: iload_17: sipush 1000010: if_icmpge 2713: getstatic #12 // Field j:I16: iconst_117: iadd18: putstatic #12 // Field j:I21: iinc 1, 124: goto 627: returnpublic void incrTwo();Code:0: aload_01: invokevirtual #11 // Method syncDbData:()V4: aload_05: dup6: astore_17: monitorenter //获取锁8: iconst_09: istore_210: iload_211: sipush 1000014: if_icmpge 3117: getstatic #12 // Field j:I20: iconst_121: iadd22: putstatic #12 // Field j:I25: iinc 2, 128: goto 1031: aload_132: monitorexit //正常退出释放锁33: goto 4136: astore_337: aload_138: monitorexit //异步退出释放锁39: aload_340: athrow41: return
ps:对上面指令感兴趣的读者,可以百度或google一下“JVM 虚拟机字节码指令表”
先看incrTwo函数,incrTwo是代码块方式同步,在反编译后的结果中,发现存在monitorenter与monitorexit指令(获取锁、释放锁)。monitorenter指令插入到同步代码块的开始位置,monitorexit指令插入到同步代码块的结束位置,J V M需要保证每一个monitorenter都有monitorexit与之对应。
任何对象都有一个监视器锁(monitor)关联,线程执行monitorenter指令时尝试获取monitor的所有权。 如果
monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程为monitor的所有者- 如果线程已经占有该
monitor,重新进入,则monitor的进入数加1 - 线程执行
monitorexit,monitor的进入数-1,执行过多少次monitorenter,最终要执行对应次数的monitorexit - 如果其他线程已经占用
monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权
回过头看incr函数,incr是普通函数方式同步,虽然在反编译后的结果中没有看到monitorenter与monitorexit指令,但是实际执行的流程与incrTwo函数一样,通过monitor来执行,只不过它是一种隐式的方式来实现,最后放一张流程图。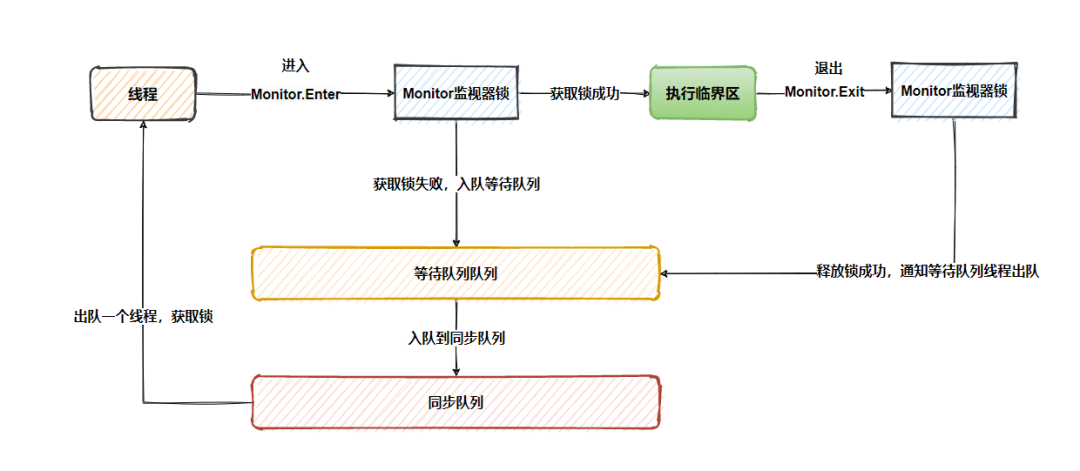
Synchronized优化
Jdk 1.5以后对Synchronized关键字做了各种的优化,经过优化后Synchronized已经变得原来越快了,这也是为什么官方建议使用Synchronized的原因,具体的优化点如下。
- 锁粗化
- 锁消除
- 锁升级
锁粗化
互斥的临界区范围应该尽可能小,这样做的目的是为了使同步的操作数量尽可能缩小,缩短阻塞时间,如果存在锁竞争,那么等待锁的线程也能尽快拿到锁。
但是加锁解锁也需要消耗资源,如果存在一系列的连续加锁解锁操作,可能会导致不必要的性能损耗,锁粗化就是将「多个连续的加锁、解锁操作连接在一起」,扩展成一个范围更大的锁,避免频繁的加锁解锁操作。
JVM会检测到一连串的操作都对同一个对象加锁(for循环10000次执行j++,没有锁粗化就要进行10000次加锁/解锁),此时J V M就会将加锁的范围粗化到这一连串操作的外部(比如for循环体外),使得这一连串操作只需要加一次锁即可。锁消除
Java虚拟机在JIT编译时(可以简单理解为当某段代码即将第一次被执行时进行编译,又称即时编译),通过对运行上下文的扫描,经过逃逸分析(对象在函数中被使用,也可能被外部函数所引用,称为函数逃逸),去除不可能存在共享资源竞争的锁,通过这种方式消除没有必要的锁,可以节省毫无意义的时间消耗。
代码中使用Object作为锁,但是Object对象的生命周期只在incrFour()函数中,并不会被其他线程所访问到,所以在J I T编译阶段就会被优化掉(此处的Object属于没有逃逸的对象)。锁升级
Java中每个对象都拥有对象头,对象头由Mark World、指向类的指针、以及数组长度三部分组成,只需要关心Mark World即可,Mark World记录了对象的HashCode、分代年龄和锁标志位信息。
Mark World简化结构
| 锁状态 | 存储内容 | 锁标记 |
|---|---|---|
| 无锁 | 对象的hashCode、对象分代年龄、是否是偏向锁(0) | 01 |
| 偏向锁 | 偏向线程ID、偏向时间戳、对象分代年龄、是否是偏向锁(1) | 01 |
| 轻量级锁 | 指向栈中锁记录的指针 | 00 |
| 重量级锁 | 指向互斥量(重量级锁)的指针 | 10 |
锁的升级变化,体现在锁对象的对象头Mark World部分,也就是说Mark World的内容会随着锁升级而改变。Java1.5以后为了减少获取锁和释放锁带来的性能消耗,引入了偏向锁和轻量级锁,Synchronized的升级顺序是 「无锁—>偏向锁—>轻量级锁—>重量级锁,只会升级不会降级」
偏向锁
在大多数情况下,锁总是由同一线程多次获得,不存在多线程竞争,所以出现了偏向锁,其目标就是在只有一个线程执行同步代码块时,降低获取锁带来的消耗,提高性能(可以通过J V M参数关闭偏向锁:-XX:-UseBiasedLocking=false,关闭之后程序默认会进入轻量级锁状态)。
线程执行同步代码或方法前,线程只需要判断对象头的Mark Word中线程ID与当前线程ID是否一致,如果一致直接执行同步代码或方法,具体流程如下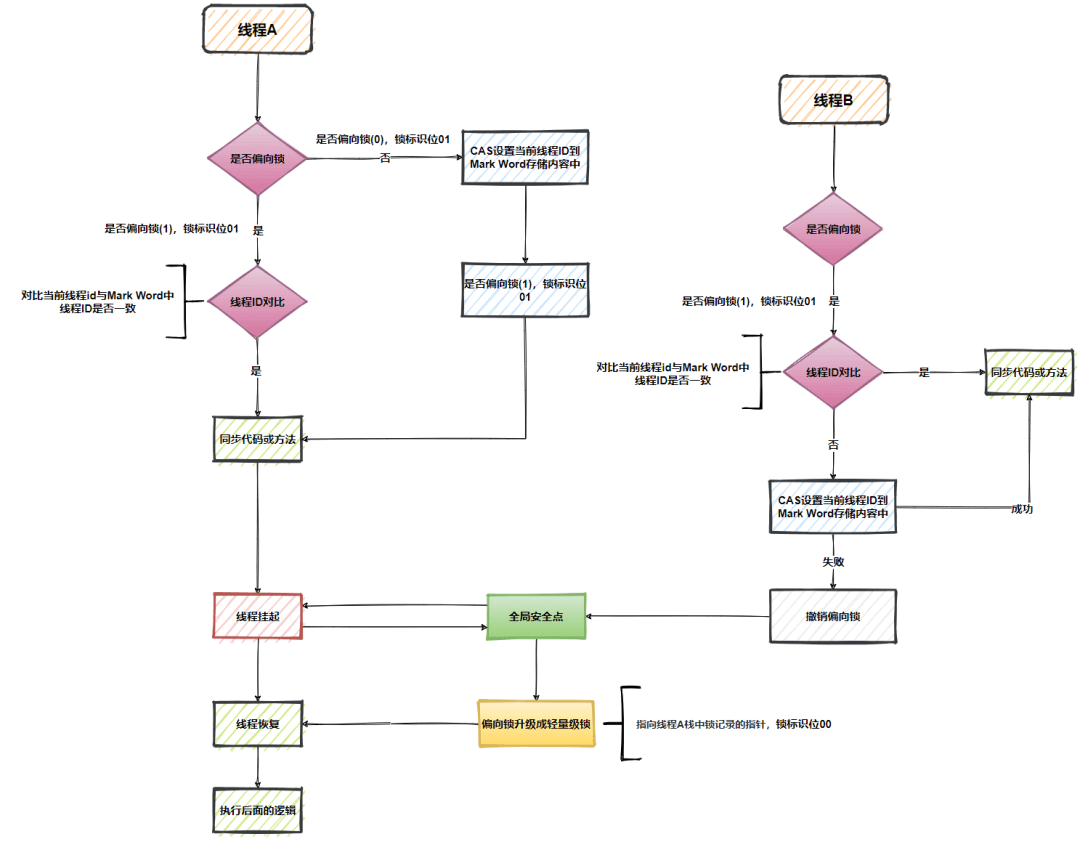
- 无锁状态,存储内容「是否为偏向锁(
0)」,锁标识位01CAS设置当前线程ID到Mark Word存储内容中- 是否为偏向锁
0=> 是否为偏向锁1 - 执行同步代码或方法
偏向锁状态,存储内容「是否为偏向锁(
1)、线程ID」,锁标识位01- 对比线程
ID是否一致,如果一致执行同步代码或方法,否则进入下面的流程 - 如果不一致,
CAS将Mark Word的线程ID设置为当前线程ID,设置成功,执行同步代码或方法,否则进入下面的流程 CAS设置失败,证明存在多线程竞争情况,触发撤销偏向锁,当到达全局安全点,偏向锁的线程被挂起,偏向锁升级为轻量级锁,然后在安全点的位置恢复继续往下执行。轻量级锁
轻量级锁考虑的是竞争锁对象的线程不多,持有锁时间也不长的场景。因为阻塞线程需要C P U从用户态转到内核态,代价较大,如果刚刚阻塞不久这个锁就被释放了,那这个代价就有点得不偿失,所以干脆不阻塞这个线程,让它自旋一段时间等待锁释放。
当前线程持有的锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。轻量级锁的获取主要有两种情况:① 当关闭偏向锁功能时;② 多个线程竞争偏向锁导致偏向锁升级为轻量级锁。
- 对比线程
无锁状态,存储内容「是否为偏向锁(
0)」,锁标识位01- 关闭偏向锁功能时
CAS设置当前线程栈中锁记录的指针到Mark Word存储内容- 锁标识位设置为
00 - 执行同步代码或方法
- 释放锁时,还原来
Mark Word内容
- 轻量级锁状态,存储内容「线程栈中锁记录的指针」,锁标识位
00(存储内容的线程是指”持有轻量级锁的线程”)CAS设置当前线程栈中锁记录的指针到Mark Word存储内容,设置成功获取轻量级锁,执行同步块代码或方法,否则执行下面的逻辑- 设置失败,证明多线程存在一定竞争,线程自旋上一步的操作,自旋一定次数后还是失败,轻量级锁升级为重量级锁
Mark Word存储内容替换成重量级锁指针,锁标记位10重量级锁
轻量级锁膨胀之后,就升级为重量级锁,重量级锁是依赖操作系统的MutexLock(互斥锁)来实现的,需要从用户态转到内核态,这个成本非常高,这就是为什么Java1.6之前Synchronized效率低的原因。
升级为重量级锁时,锁标志位的状态值变为10,此时Mark Word中存储内容的是重量级锁的指针,等待锁的线程都会进入阻塞状态,下面是简化版的锁升级过程。

若有收获,就点个赞吧
0 人点赞
