JavaWeb Tomcat
Tomcat历史悠久,从正式发布到现在已经20多年了,但是就算在现在仍然占有一席之地。
Spring Boot目前很火,而Tomcat则是它默认的Web服务器实现,那么Tomcat为什么这么重要,接下来分析一下Tomcat是如何接收,并处理一个请求的?
Tomcat启动时需要绑定一个端口,默认为8080,一旦Tomcat启动成功就占用了机器的8080端口,也就是表示,机器中8080端口接收到的数据会交给Tomcat来处理,机器接收到的数据肯定是字节流。
Tomcat是如何解析这些字节流的?解析为什么对象?
Tomcat是一个Servlet容器,虽然在使用Tomcat时,会把整个项目打成一个war包部署到Tomcat里去,整个项目中包括了很多类,但是对于Tomcat而言,它只关心项目中的那些实现了Servlet接口的类,或者说只关心在web.xml中或通过@WebServlet注解所定义的Servlet类。
比如,把一个项目部署到Tomcat的wabapps文件夹里后,Tomcat启动时会去找该项目文件夹中的/WEB-INF/web.xml文件,并解析它,解析完了之后,就知道当前项目中定义了哪些Servlet,并且这些Servlet对应接收什么格式的请求(servlet-mapping)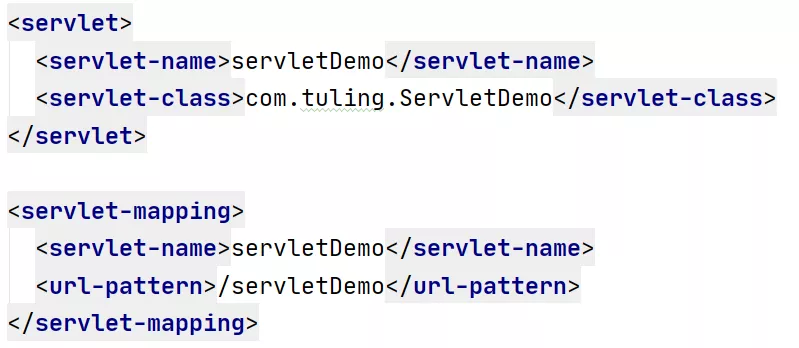
Tomcat启动后,在接收到某个请求后,就可以根据请求路径和url-pattern进行匹配,如果匹配成功,则会把这个请求交给对应的servlet进行处理。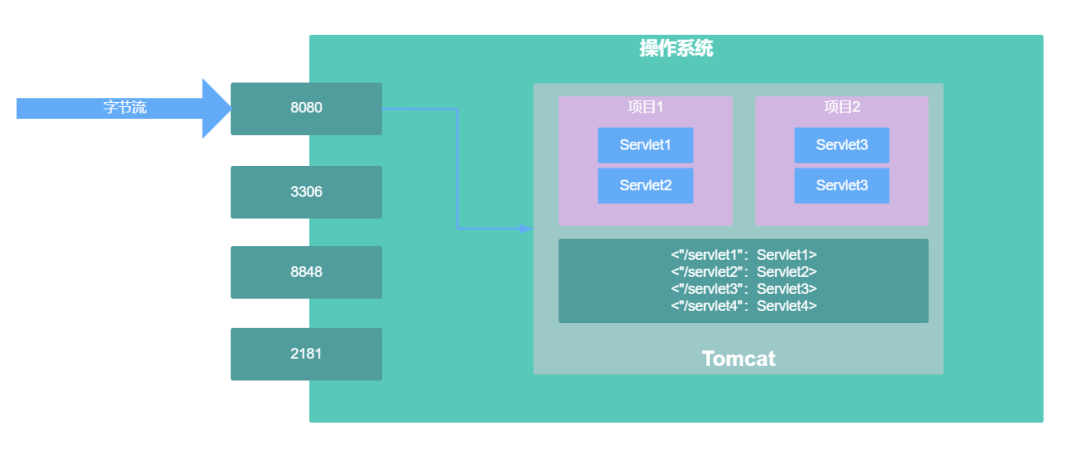
上面只是请求处理的一个大概流程梳理,这其中还有很多细节需要挖掘,比如:
- Tomcat是如何解析字节流的?解析为什么对象?
- 定义Servlet时会去定义doGet、doPost等方法,那么Tomcat是如何判断该调哪个方法,并且是如何调用的?
- 其他问题
来看一下定义的Servlet:
public class ServletDemo extends HttpServlet {@Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException {resp.getWriter().println("hello servlet");}}
上面代码中,定义了一个doGet(HttpServletRequest req, HttpServletResponse resp)方法,并且有两个参数,一个代表请求,一个代表响应,doGet方法就是在接收到get请求时会被调用。
事实上,Tomcat接收到一个请求(字节流)后,就会将字节流解析为一个HttpServletRequest对象,然后根据请求找到对应的Servlet,然后调用Servlet中的service()方法。service()方法在定义的Servlet的父类HttpServlet中,而在service方法中,会去判断当前请求方法,如果是get请求,就会调用doGet,如果是post,就会调用doPost,service方法实现如下:
protected void service(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {String method = req.getMethod();long lastModified;if (method.equals("GET")) {lastModified = this.getLastModified(req);if (lastModified == -1L) {this.doGet(req, resp);} else {long ifModifiedSince = req.getDateHeader("If-Modified-Since");if (ifModifiedSince < lastModified) {this.maybeSetLastModified(resp, lastModified);this.doGet(req, resp);} else {resp.setStatus(304);}}} else if (method.equals("HEAD")) {lastModified = this.getLastModified(req);this.maybeSetLastModified(resp, lastModified);this.doHead(req, resp);} else if (method.equals("POST")) {this.doPost(req, resp);} else if (method.equals("PUT")) {this.doPut(req, resp);} else if (method.equals("DELETE")) {this.doDelete(req, resp);} else if (method.equals("OPTIONS")) {this.doOptions(req, resp);} else if (method.equals("TRACE")) {this.doTrace(req, resp);} else {String errMsg = lStrings.getString("http.method_not_implemented");Object[] errArgs = new Object[]{method};errMsg = MessageFormat.format(errMsg, errArgs);resp.sendError(501, errMsg);}}
那么,Tomcat接收到数据并解析为HttpServletRequest对象后,就直接把请求交给Servlet了吗?
并不是,Tomcat还有其他考虑,比如:
- 假如,现在有一段逻辑,想让多个Servlet公用,就像切面一下,希望在请求被这些Servlet处理之前,能先执行公共逻辑。
- 假如,现在有一段逻辑,想让多个应用内的Servlet公用,就像切面一下,希望在请求被这些应用处理之前,能先执行公共逻辑。
- 不同的域名可以对应同一个IP地址,对应同一个机器,那么希望Tomcat能根据不同的域名做不同的处理
- 如果Tomcat支持多域名,那么希望能使得这多个域名能共享某段逻辑
可能上面这四种假设,会有点懵,没关系,直接往下面看,在Tomcat中存在四大Servlet容器:
Engine:直接理解为一个Tomcat即可,一个Tomcat一个EngineHost:一个Host表示一个虚拟服务器,可以给每个Host配置一个域名Context:一个Context就是一个应用,一个项目Wrapper:一个Wrapper表示一个Servlet的包装,Wrapper在后文详解
并且这四个Servlet容器是具有层次关系的:一个Engine下可以有多个Host,一个Host下可以有多个Context,一个Context下可以有多个Wrapper,一个Wrapper下可以有多个Servlet实例对象。
Tomcat接收到某个请求后,首先会判断该请求的域名,根据域名找到对应的Host对象,Host对象再根据请求信息找到请求所要访问的应用,也就是找到一个Context对象,Context对象拿到请求后,会根据请求信息找到对应的Servlet。
Wrapper是什么?
在定义一个Servlet时,如果额外实现了SingleThreadModel接口,那么就表示该Servlet是单线程模式:
- 定义Servlet时如果没有实现
SingleThreadModel接口,那么在Tomcat中只会产生该Servlet的一个实例对象,如果多个请求同时访问该Servlet,那么这多个请求线程访问的是同一个Servlet对象,所以是并发不安全的 - 定义Servlet时如果实现了SingleThreadModel接口,那么在Tomcat中可能会产生多个该Servlet的实例对象,多个请求同时访问该Servlet,那么每个请求线程会有一个单独的Servlet对象,所以是并发安全的。
所以,可以发现,定义的某个Servlet,在Tomcat中可能会存在多个该类型的实例对象,所以Tomcat需要再抽象出来一层,这一层就是Wrapper,一个Wrapper对应一个Servlet类型,Wrapper中有一个集合,用来存储该Wrapper对应的Servlet类型的实例对象。
所以一个Context表示一个应用,如果一个应用中定义了10个Servlet,那么Context下面就有10个Wrapper对象,而每个Wrapper中可能又会存在多个Servlet对象。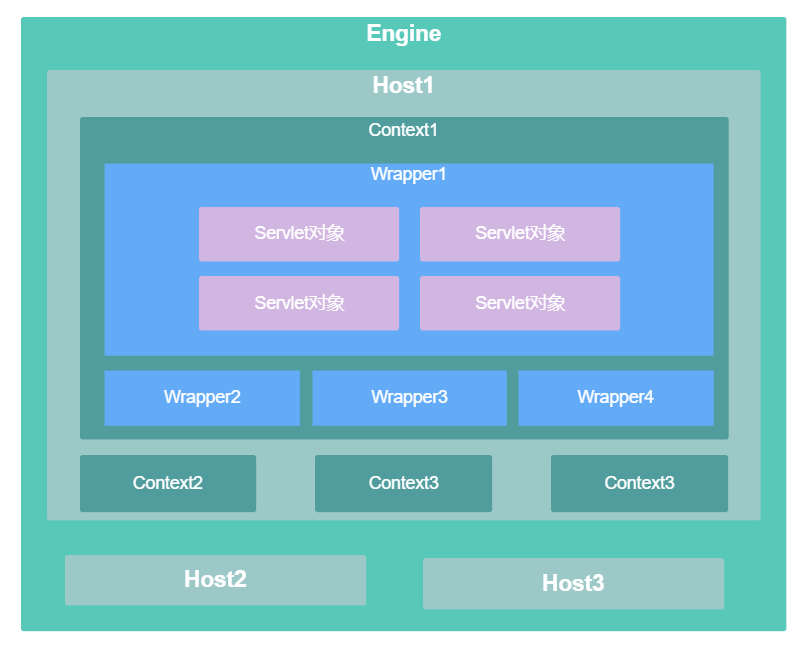
还有一点,在这个四个容器内部,有一个组件叫做Pipeline,也就管道,每个管道中可以设置多个Valve,也就阀门。
管道与阀门的作用是,每个容器在接收到请求时会先把请求交给容器中的每个阀门处理,所有阀门都处理完了之后,在会将请求交给下层容器,通过这种机制,就解决了上面所提到的四种假设:
Engine:可以处理Tomcat所接收到所有请求,不管这些请求是请求哪个应用或哪个Servlet的。Host:可以处理某个特定域名的所有请求Context:可以处理某个应用的所有请求Wrapper:可以处理某个Servlet的所有请求
值得一说的是,Wrapper还会负责调用Servlet对象的service()方法。
到此,Tomcat接收到字节流并解析为HttpServletRequest对象之后,HttpServletRequest对象是如何流转的分析完了,总结一下就是:
接下来再来分析一下,Tomcat是如何将字节流解析为HttpServletRequest对象的。
这个问题其实不难,只要想到这些字节流是谁发过来的?
比如浏览器,浏览器在发送数据时,会先将数据按HTTP协议的格式进行包装,再把HTTP数据包通过TCP协议发送出去,Tomcat就是从TCP协议中接收到数据的,只是从TCP协议中接收的数据是字节流,接下来要做的就是同样按照HTTP协议进行解析,比如解析出请求行、请求头等,从而就可以生成HttpServletRequest对象。
Tomcat解析字节流得到HttpServletRequest对象后是如何在Tomcat内部流程并交给Servlet执行的,来详细解释一下Tomcat是如何根据HTTP协议来解析字节流的。
获取字节流
先从获取字节流开始,Tomcat底层是通过TCP协议,也就是Socket来获取网络数据的,那么从Socket上获取数据,就涉及到IO模型,在Tomcat8以后,就同时支持了NIO和BIO。
在Tomcat中,有一个组件叫做Connector,他就是专门用来接收Socket连接的,在Connector内部有一个组件叫ProtocolHandler,它有好几种实现:
- Http11Protocol
- Http11NioProtocol
- Http11AprProtocol
这样,应该就能更加明白了,就是通过这三个类来支持各种IO模型的,先来看Http11Protocol。
Http11Protocol(BIO)
在Http11Protocol中存在一个组件,叫JIoEndpoint,而在JIoEndpoint中存在一个组件,叫Acceptor。
Acceptor是一个线程,这个线程会不停的从ServerSocket中获取Socket连接,每接收到一个Socket连接之后,就会将这个Socket连接扔到一个线程池中,由线程池中的线程去处理Socket,包括从Socket中获取数据,将响应结果写到Socket中。
所以,如果现在用的是Tomcat中的BIO模式,如果要进行性能调优,就可以调整该线程池的大小,默认10个核心线程,最大为200个线程。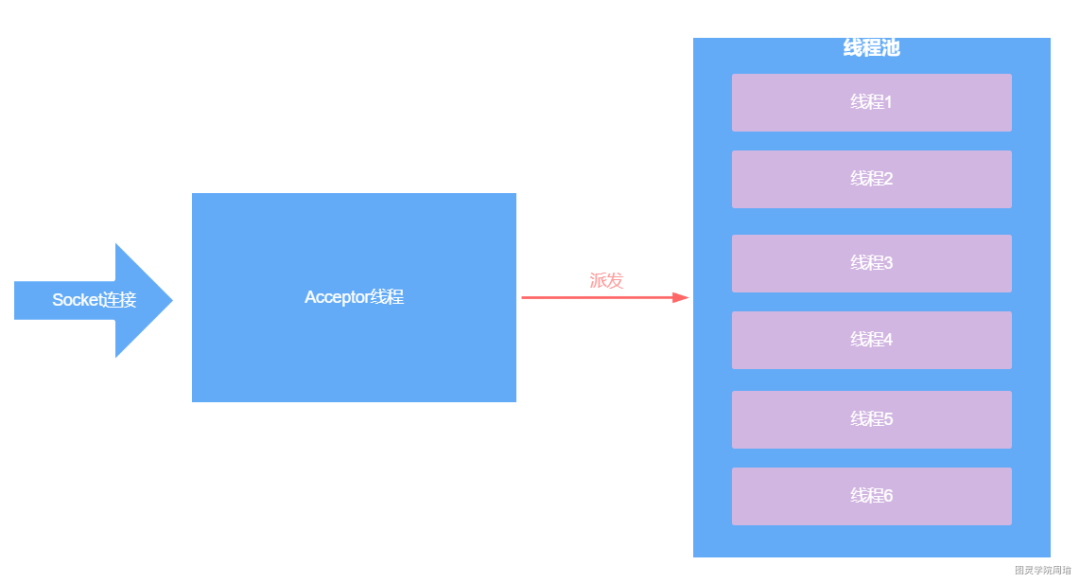
Http11NioProtocol(NIO)
再来看Http11NioProtocol,和Http11Protocol非常类似,在它的底层有一个NioEndpoint,NioEndpoint中也存在一个Acceptor线程。
但是需要注意的是,现在虽然是NIO模型,但是Acceptor线程在接收Socket连接时,并不是非阻塞的方式,仍然是通过阻塞的方式来接收Socket连接。
Acceptor线程每接收到一个Socket连接后,就会将该Socket连接注册给一个Poller线程,后续就由这个Poller线程来负责处理该Socket上读写事件,默认情况下Tomcat中至少存在两个Poller线程,要么就是CPU核心数个Poller线程。
值得注意的是,Poller线程不是通过线程池来实现的,是通过一个Poller数组来实现的,因为在NIO模型下,一个Poller线程要负责处理多个Socket连接中的读写事件,所以Acceptor线程在接收到一个Socket连接后,要能够比较方便的拿到Poller线程。
如果用线程池,那么就不方便拿线程对象了,而用Poller数组,就会轮询拿到Poller线程,并把接收到的Socket连接注册给Poller线程。
另外,某个Poller线程接收到一个读写事件后,会将该事件派发给另外一个线程池进行处理。所以,NIO模型是更加复杂的,总结一下就是:
- Acceptor线程负责接收Socket连接
- Poller线程负责接收读写事件
- 线程池负责处理读写事件
所以,如果现在用的是Tomcat中的NIO模式,如果要进行性能调优,可以调整该Poller数组的大小,也可以调整线程池的大小。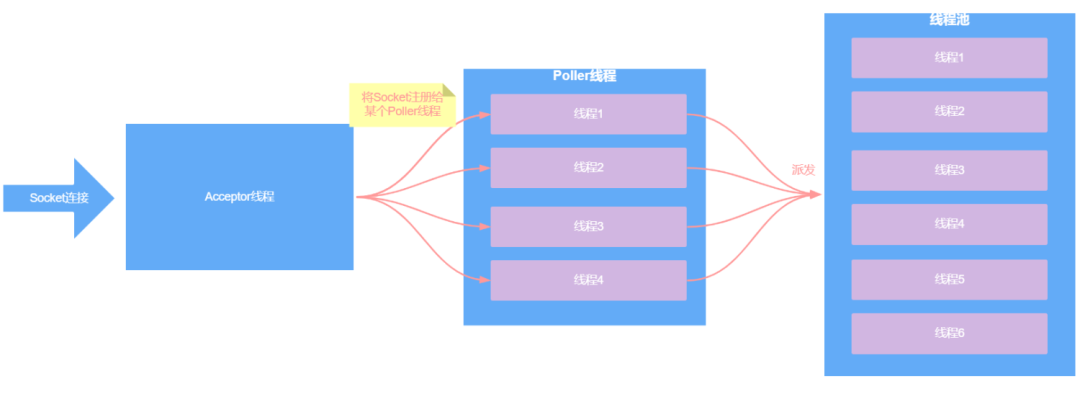
解析字节流
不同的IO模型只是表示从Socket上获取字节流的方式不同而已,而获取到字节流之后,就需要进行解析了,之前说过,Tomcat需要按照HTTP协议的格式来解析字节流,下面是HTTP协议的格式: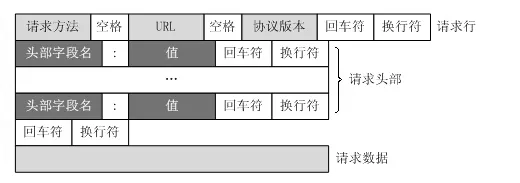
所以,浏览器或者HttpClient在发送数据时,同样需要按照Http协议来构造数据(字符串),然后将字符串转成字节发送出去,所以Tomcat解析字节流的逻辑就是:
- 从获得的第一个字节开始,遍历每个字节,当遇到空格时,那么之前所遍历到的字节数据就是请求方法
- 然后继续遍历每个字节,当遇到空格时,那么之前遍历到的字节数据就是URL
- 然后继续遍历每个字节,当遇到回车、换行符时,那么之前遍历到的字节数据就是协议版本,并且表示请求行遍历结束
- 然后继续遍历当遇到一个回车符和换行符时,那么所遍历的数据就是一个请求头
- 继续遍历当遍历到两个回车符和换行符时,那么所遍历的数据就是一个请求头,并且表示请求头全部遍历完毕
- 剩下的字节流数据就表示请求体
值得注意的是,如果使用的是长连接,那么就有可能多个HTTP请求共用一个Socket连接。
那么Tomcat在获取并解析Socket连接中的字节流时,该如何判断某个HTTP请求的数据在哪个位置结束了呢?也就是如何判断一个请求的请求体何时结束?
有两种方式:
- 设置Content-Length:在发送请求时直接设置请求体的长度,那么Tomcat在解析时,自然就知道了当前请求的请求体在哪个字节结束
设置Transfer-Encoding为chunk:也就是分块传输,在发送请求时,按如下格式来传输请求体,
[chunk size][\r\n][chunk data][\r\n][chunk size][\r\n][chunk data][\r\n][chunk size = 0][\r\n][\r\n],注意最后的chunk size=0和两个回车换行符,只要Tomcat解析到这些时,就表示接收到了最后一块,也就表示请求体结束了总结
总结一下Tomcat处理请求的流程:
浏览器在请求一个
Servlet时,会按照HTTP协议构造一个HTTP请求,通过Socket连接发送给Tomcat- Tomcat通过不同的IO模型都可以接收到
Socket的字节流数据 - 接收到数据后,按HTTP协议解析字节流,得到
HttpServletRequest对象 - 再通过
HttpServletRequest对象,也就是请求信息,找到该请求对应的Host、Context、Wrapper - 然后将请求交给
Engine层处理 Engine层处理完,就会将请求交给Host层处理Host层处理完,就会将请求交给Context层处理Context层处理完,就会将请求交给Wrapper层处理Wrapper层在拿到一个请求后,就会生成一个请求所要访问的Servlet实例对象- 调用
Servlet实例对象的service()方法,并把HttpServletRequest对象当做入参 - 从而就调用到
Servlet所定义的逻辑

若有收获,就点个赞吧
0 人点赞
