LockSupport类
了解线程的阻塞和唤醒,需要查看LockSupport类。具体代码如下:
public class LockSupport {private LockSupport() {} // Cannot be instantiated.private static void setBlocker(Thread t, Object arg) {U.putObject(t, PARKBLOCKER, arg);}public static void unpark(Thread thread) {if (thread != null)U.unpark(thread);}public static void park(Object blocker) {Thread t = Thread.currentThread();setBlocker(t, blocker);U.park(false, 0L);setBlocker(t, null);}public static void parkNanos(Object blocker, long nanos) {if (nanos > 0) {Thread t = Thread.currentThread();setBlocker(t, blocker);U.park(false, nanos);setBlocker(t, null);}}public static void parkUntil(Object blocker, long deadline) {Thread t = Thread.currentThread();setBlocker(t, blocker);U.park(true, deadline);setBlocker(t, null);}public static Object getBlocker(Thread t) {if (t == null)throw new NullPointerException();return U.getObjectVolatile(t, PARKBLOCKER);}public static void park() {U.park(false, 0L);}public static void parkNanos(long nanos) {if (nanos > 0)U.park(false, nanos);}public static void parkUntil(long deadline) {U.park(true, deadline);}//省略部分代码private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();private static final long PARKBLOCKER;private static final long SECONDARY;static {try {PARKBLOCKER = U.objectFieldOffset(Thread.class.getDeclaredField("parkBlocker"));SECONDARY = U.objectFieldOffset(Thread.class.getDeclaredField("threadLocalRandomSecondarySeed"));} catch (ReflectiveOperationException e) {throw new Error(e);}}}
从上面的代码中,可以知道LockSupport中的对外提供的方法都是静态方法。这些方法提供了最基本的线程阻塞和唤醒功能,在LockSupport类中定义了一组以park开头的方法用来阻塞当前线程。以及unPark(Thread thread)方法来唤醒一个被阻塞的线程。关于park开头的方法具体描述如下表所示:
其中park(Object blocker)与parkNanos(Object blocker, long nanos)及parkUntil(Object blocker, long deadline)三个方法是Java 6中新增加的方法。其中参数blocker是用来标识当前线程等待的对象(下文简称为阻塞对象),该对象主要用于问题排查和系统监控。
由于在Java 5之前,当线程阻塞时(使用synchronized关键字)在一个对象上时,通过线程dump能够查看到该线程的阻塞对象。方便问题定位,而Java 5退出的Lock等并发工具却遗漏了这一点,致使在线程dump时无法提供阻塞对象的信息。因此,在Java 6中,LockSupport新增了含有阻塞对象的park方法。用以替代原有的park方法。
LockSupport中的blocker
可能有很多读者对Blocker的原理有点好奇,既然线程都被阻塞了,是通过什么办法将阻塞对象设置到线程中去的呢? 继续查看含有阻塞对象(Object blocker)的park方法。 可以发现内部都调用了setBlocker(Thread t, Object arg)方法。具体代码如下所示:
private static void setBlocker(Thread t, Object arg) {U.putObject(t, PARKBLOCKER, arg);}
其中 U为sun.misc.包下的Unsafe类。而其中的PARKBLOCKER是在静态代码块中进行赋值的,也就是如下代码:
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();static {try {PARKBLOCKER = U.objectFieldOffset(Thread.class.getDeclaredField("parkBlocker"));//省略部分代码} catch (ReflectiveOperationException e) {throw new Error(e);}}
Thread.class.getDeclaredField("parkBlocker")方法其实很好理解,就是获取线程中的parkBlocker字段。如果有则返回其对应的Field字段,如果没有则抛出NoSuchFieldException异常。那么关于Unsafe中的objectFieldOffset(Field f)方法怎么理解呢?
在描述该方法之前,需要给大家讲一个知识点。在JVM中,可以自由选择如何实现Java对象的”布局”,也就Java对象的各个部分分别放在内存那个地方,JVM是可以感知和决定的。 在sun.misc.Unsafe中提供了objectFieldOffset()方法用于获取某个字段相对 Java对象的“起始地址”的偏移量,也提供了getInt、getLong、getObject之类的方法可以使用前面获取的偏移量来访问某个Java 对象的某个字段。
有可能大家理解起来比较困难,这里给大家画了一个图,帮助理解,具体如下图所示:
在上图中,创建了两个Thread对象,其中Thread对象1在内存中分配的地址为0x10000-0x10100,Thread对象2在内存中分配的地址为0x11000-0x11100,其中parkBlocker对应内存偏移量为2(这里假设相对于其对象的“起始位置”的偏移量为2)。那么通过objectFieldOffset(Field f)就能获取该字段的偏移量。需要注意的是某字段在其类中的内存偏移量总是相同的,也就是对于Thread对象1与Thread对象2,parkBlocker字段在其对象所在的内存偏移量始终是相同的。
那么再回到setBlocker(Thread t, Object arg)方法,当获取到parkBlocker字段在其对象内存偏移量后,
接着会调用U.putObject(t, PARKBLOCKER, arg);,该方法有三个参数,第一个参数是操作对象,第二个参数是内存偏移量,第三个参数是实际存储值。该方法理解起来也很简单,就是操作某个对象中某个内存地址下的数据。那么结合上面所讲的。该方法的实际操作结果如下图所示:
到现在,就应该懂了,尽管当前线程已经阻塞,但是还是能直接操控线程中实际存储该字段的内存区域来达到想要的结果。
LockSupport底层代码实现
通过阅读源代码可以发现,LockSupport中关于线程的阻塞和唤醒,主要调用的是sun.misc.Unsafe 中的park(boolean isAbsolute, long time)与unpark(Object thread)方法,也就是如下代码:
private static final jdk.internal.misc.Unsafe theInternalUnsafe =jdk.internal.misc.Unsafe.getUnsafe();public void park(boolean isAbsolute, long time) {theInternalUnsafe.park(isAbsolute, time);}public void unpark(Object thread) {theInternalUnsafe.unpark(thread);}
查看sun.misc.包下的Unsafe.java文件可以看出,内部其实调用的是jdk.internal.misc.Unsafe中的方法。继续查看jdk.internal.misc.中的Unsafe.java中对应的方法:
@HotSpotIntrinsicCandidatepublic native void unpark(Object thread);@HotSpotIntrinsicCandidatepublic native void park(boolean isAbsolute, long time);
通过查看方法,可以得出最终调用的是JVM中的方法,也就是会调用hotspot.share.parims包下的unsafe.cpp中的方法。继续跟踪。
UNSAFE_ENTRY(void, Unsafe_Park(JNIEnv *env, jobject unsafe, jboolean isAbsolute, jlong time)) {//省略部分代码thread->parker()->park(isAbsolute != 0, time);//省略部分代码} UNSAFE_ENDUNSAFE_ENTRY(void, Unsafe_Unpark(JNIEnv *env, jobject unsafe, jobject jthread)) {Parker* p = NULL;//省略部分代码if (p != NULL) {HOTSPOT_THREAD_UNPARK((uintptr_t) p);p->unpark();}} UNSAFE_END
通过观察代码发现,线程的阻塞和唤醒其实是与hotspot.share.runtime中的Parker类相关。继续查看:
class Parker : public os::PlatformParker {private:volatile int _counter ;//该变量非常重要,下文会具体描述//省略部分代码protected:~Parker() { ShouldNotReachHere(); }public:// For simplicity of interface with Java, all forms of park (indefinite,// relative, and absolute) are multiplexed into one call.void park(bool isAbsolute, jlong time);void unpark();//省略部分代码}
在上述代码中,volatile int _counter该字段的值非常重要,一定要注意其用volatile修饰(在下文中会具体描述,接着当通过SourceInsight工具(推荐大家阅读代码时,使用该工具)点击其park与unpark方法时,会得到如下界面: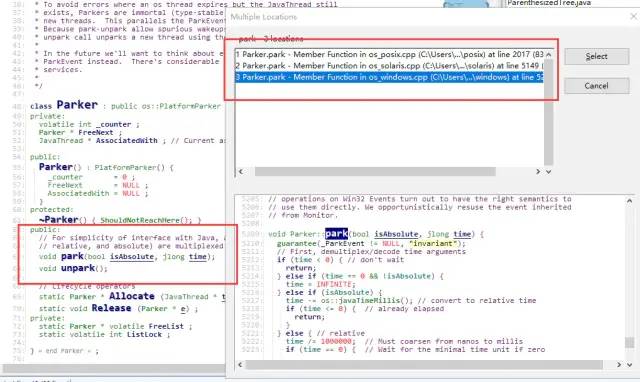
从图中红色矩形中可也看出,针对线程的阻塞和唤醒,不同操作系统有着不同的实现。众所周知Java是跨平台的。针对不同的平台,做出不同的处理。也是非常理解的。因为作者对windows与solaris操作系统不是特别了解。所以这里选择对Linux下的平台下进行分析。也就是选择hotspot.os.posix包下的os_posix.cpp文件进行分析。
Linux下的park实现
为了方便大家理解Linux下的阻塞实现,在实际代码中省略了一些不重要的代码,具体如下图所示:
void Parker::park(bool isAbsolute, jlong time) {//(1)如果_counter的值大于0,那么直接返回if (Atomic::xchg(0, &_counter) > 0) return;//获取当前线程Thread* thread = Thread::current();JavaThread *jt = (JavaThread *)thread;//(2)如果当前线程已经中断,直接返回。if (Thread::is_interrupted(thread, false)) {return;}//(3)判断时间,如果时间小于0,或者在绝对时间情况下,时间为0直接返回struct timespec absTime;if (time < 0 || (isAbsolute && time == 0)) { // don't wait at allreturn;}//如果时间大于0,判断阻塞超时时间或阻塞截止日期,同时将时间赋值给absTimeif (time > 0) {to_abstime(&absTime, time, isAbsolute);}//(4)如果当前线程已经中断,或者申请互斥锁失败,则直接返回if (Thread::is_interrupted(thread, false) ||pthread_mutex_trylock(_mutex) != 0) {return;}//(5)如果是时间等于0,那么就直接阻塞线程,if (time == 0) {_cur_index = REL_INDEX; // arbitrary choice when not timedstatus = pthread_cond_wait(&_cond[_cur_index], _mutex);assert_status(status == 0, status, "cond_timedwait");}//(6)根据absTime之前计算的时间,阻塞线程相应时间else {_cur_index = isAbsolute ? ABS_INDEX : REL_INDEX;status = pthread_cond_timedwait(&_cond[_cur_index], _mutex, &absTime);assert_status(status == 0 || status == ETIMEDOUT,status, "cond_timedwait");}//省略部分代码//(7)当线程阻塞超时,或者到达截止日期时,直接唤醒线程_counter = 0;status = pthread_mutex_unlock(_mutex);//省略部分代码}
从整个代码来看其实关于Linux下的park方法分为以下七个步骤:
- (1)调用
Atomic::xchg方法,将_counter的值赋值为0,其方法的返回值为之前_counter的值,如果返回值大于0(因为有其他线程操作过_counter的值,也就是其他线程调用过unPark方法),那么就直接返回。 - (2)如果当前线程已经中断,直接返回。也就是说如果当前线程已经中断了,那么调用
park()方法来阻塞线程就会无效。 - (3) 判断其设置的时间是否合理,如果合理,判断阻塞超时时间或阻塞截止日期,同时将时间赋值给
absTime - (4) 在实际对线程进行阻塞前,再一次判断如果当前线程已经中断,或者申请互斥锁失败,则直接返回
- (5) 如果是时间等于0(时间为0,表示一直阻塞线程,除非调用
unPark方法唤醒),那么就直接阻塞线程, - (6)根据
absTime之前计算的时间,并调用pthread_cond_timedwait方法阻塞线程相应的时间。 - (7) 当线程阻塞相应时间后,通过
pthread_mutex_unlock方法直接唤醒线程,同时将_counter赋值为0。
因为关于Linux的阻塞涉及到其内部函数,这里将用到的函数都进行了声明。大家可以根据下表所介绍的方法进行理解。具体方法如下表所示: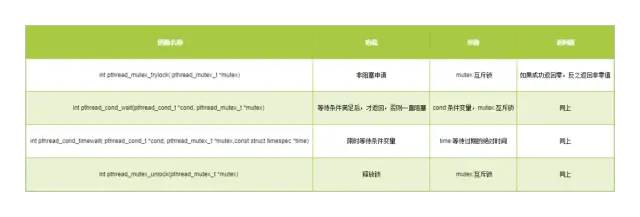
Linux下的unpark实现
在了解了Linux的park实现后,再来理解Linux的唤醒实现就非常简单了,查看相应方法:
void Parker::unpark() {int status = pthread_mutex_lock(_mutex);assert_status(status == 0, status, "invariant");const int s = _counter;//将_counter的值赋值为1_counter = 1;// must capture correct index before unlockingint index = _cur_index;status = pthread_mutex_unlock(_mutex);assert_status(status == 0, status, "invariant");//省略部分代码}
其实从代码整体逻辑来讲,最终唤醒其线程的方法为pthread_mutex_unlock(_mutex)(关于该函数的作用,已经在上表进行介绍了。可以参照Linux下的park实现中的图表进行理解)。同时将_counter的值赋值为1, 那么结合上文所讲的park(将线程进行阻塞)方法,那么可以得知整个线程的唤醒与阻塞,在Linux系统下,其实是受到Parker类中的_counter的值的影响的。
LockSupport的使用
现在基本了解了LockSupport的基本原理。现在来看看它的基本使用吧。在例子中,为了方便大家顺便弄清blocker的作用,这里调用了带blocker的park方法。具体代码如下所示:
class LockSupportDemo {public static void main(String[] args) throws InterruptedException {Thread a = new Thread(new Runnable() {@Overridepublic void run() {LockSupport.park("线程a的blocker数据");System.out.println("我是被线程b唤醒后的操作");}});a.start();//让当前主线程睡眠1秒,保证线程a在线程b之前执行Thread.sleep(1000);Thread b = new Thread(new Runnable() {@Overridepublic void run() {String before = (String) LockSupport.getBlocker(a);System.out.println("阻塞时从线程a中获取的blocker------>" + before);LockSupport.unpark(a);//这里睡眠是,保证线程a已经被唤醒了try {Thread.sleep(1000);String after = (String) LockSupport.getBlocker(a);System.out.println("唤醒时从线程a中获取的blocker------>" + after);} catch (InterruptedException e) {e.printStackTrace();}}});b.start();}}
代码中,创建了两个线程,线程a与线程b(线程a优先运行与线程b),在线程a中,通过调用LockSupport.park("线程a的blocker数据");给线程a设置了一个String类型的blocker,当线程a运行的时候,直接将线程a阻塞。在线程b中,先会获取线程a中的blocker,打印输出后。再通过LockSupport.unpark(a);唤醒线程a。当唤醒线程a后。最后输出并打印线程a中的blocker。 实际代码运行结果如下:
阻塞时从线程a中获取的blocker------>线程a的blocker数据我是被线程b唤醒后的操作唤醒时从线程a中获取的blocker------>null
从结果中,可以看出,线程a被阻塞时,后续就不会再进行操作了。当线程a被线程b唤醒后。之前设置的blocker也变为null了。同时如果在线程a中park语句后还有额外的操作。那么会继续运行。关于为毛之前的blocker之前变为null,具体原因如下:
public static void park(Object blocker) {Thread t = Thread.currentThread();setBlocker(t, blocker);U.park(false, 0L);//当线程被阻塞时,会阻塞在这里setBlocker(t, null);//线程被唤醒时,会将blocer置为null}
通过上述例子,知道了blocker可以在线程阻塞的时候,获取数据。也就证明了当对线程进行问题排查和系统监控的时候blocker的有着非常重要的作用。

若有收获,就点个赞吧
0 人点赞
