云原生( Cloud Native)应用定义
Applications adopting the principles of Microservices packaged as Containers orchestracted by Platforms running on top of Cloud infrastructure, developed using practices such as Continous Delivery and Devops.
译:基于微服务原理而开发的应用,以容器方式打包。在运行时,容器由运行于云基础设施之上的平台进行调度。应用开发采用持续交付和DevOps实践。
https://www.slideshare.net/bibryam/designing-cloud-native-applications-with-kubernetes
云演进史

CNCF
https://www.cncf.io/
https://landscape.cncf.io/
Kubernetes
Kubernetes历史

https://medium.com/containermind/a-new-era-of-container-cluster-management-with-kubernetes-cd0b804e1409
Kubernetes趋势
https://trends.google.com/trends/explore?date=today%205-y&q=Kubernetes
Kubernetes解决了什么问题

Kubernetes架构
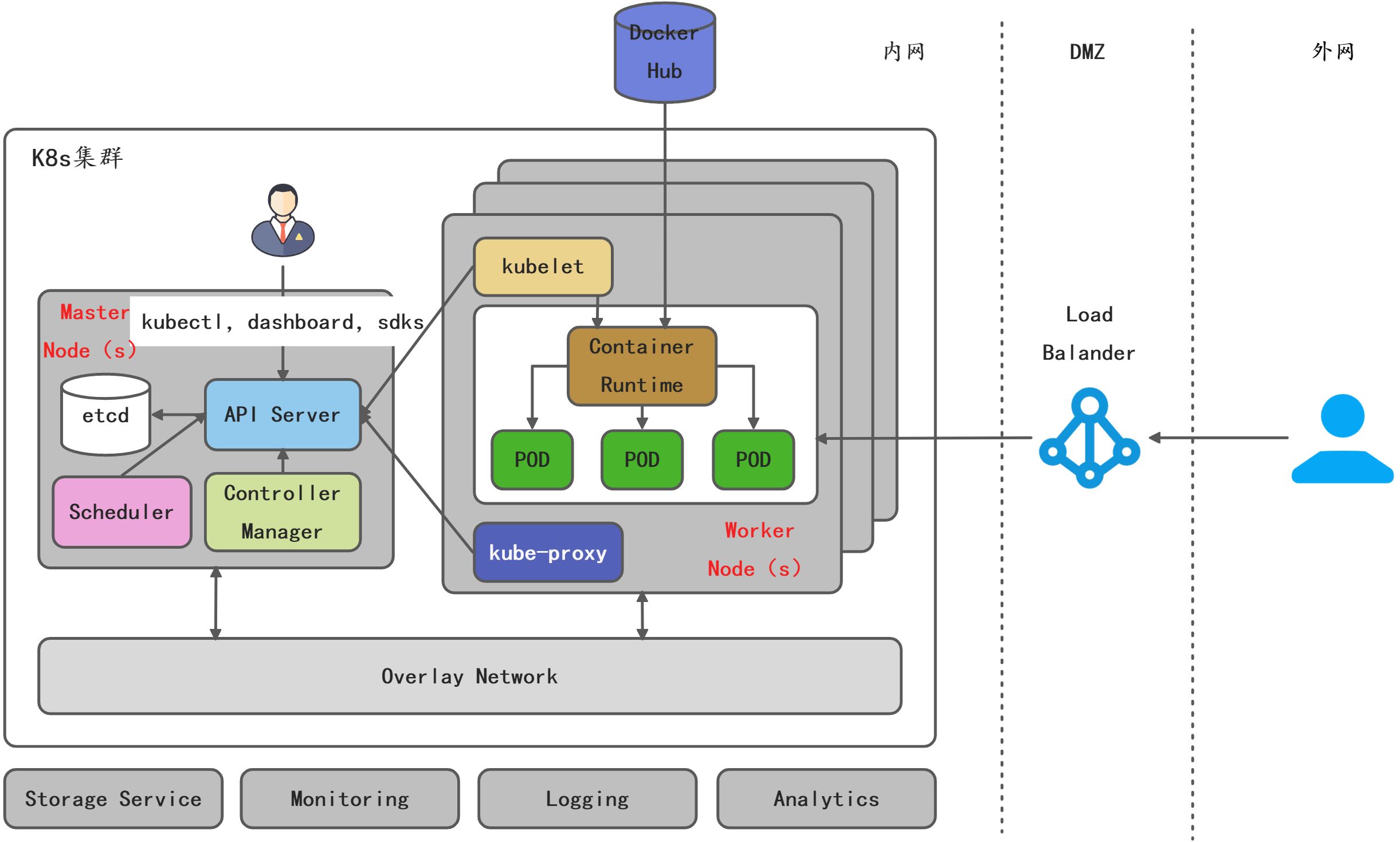
Kubernetes基本概念
Kubernetes集群(Cluster)
集群由很多的节点组成,可以按序添加更多的节点,节点可以是物理机也可以说虚拟机,每个节点都有一定数量的CPU和内存,整个Kubernetes可以看作一个一个超大计算机,他的CPU和内存容量总和可以看作是所有节点和内存的容量总和,而且可以给这台超大计算机添加更多的CPU。
容器Container
Kubernetes是一个容器调度平台,所以容器是Kubernetes平台的基本概念。容器可以看作是一个个的进程。从容器内部可以看作是一个完整的操作系统,有自己的文件系统,网络,CPU。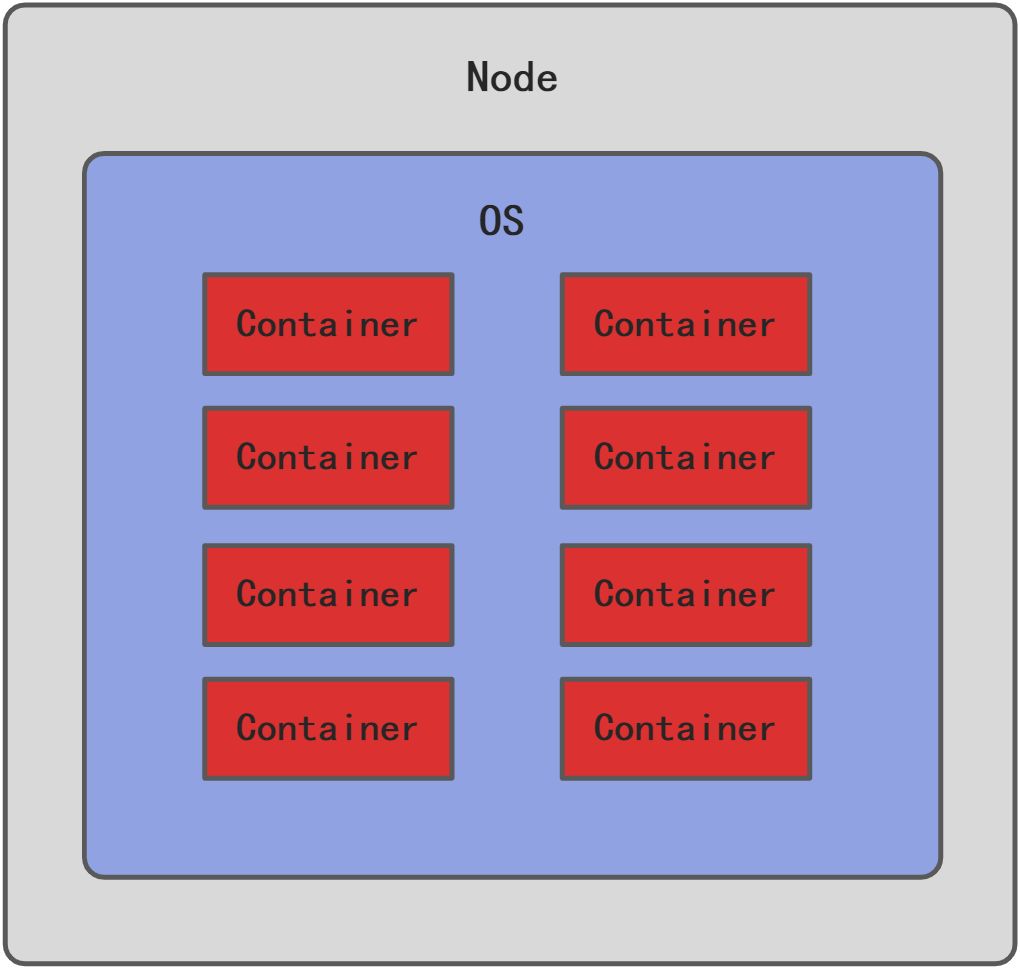
POD
POD是Kubernetes的基本调度单位,一个POD里面可以运行一个或者多个容器,他们共享POD的文件系统和网络,每个POD有一个IP,POD中的容器共享这个IP和端口,并且一个POD里面的容器可以通过localhost相互访问,大部分场景下一个POD只跑一个容器。Kubernetes没有直接调度容器,而是增加了POD封装。一个原因是考虑需要辅助容器的场景,比如有一些需要SideCar的场景,另一个原因可以考虑替换不同的容器技术。
副本集 ReplicaSet
一个应用发布的时候一般不会只发布一个POD,而是会发布多个POD,这样可以实现高可用,副本集ReplicaSet就是和和一个应用的一副POD相对应的,他可以通过模板来规范某个应用的端口,容器镜像以及副本数量,健康检查机制和环境变量等等相关的信息,运行时ReplicaSet会检测和维护副本数量。
服务Service
POD在Kubernetes中是不固定的,也可能随时换,或者是重启,重启可能是预期的或者非预期的,重启后相应的POD的IP就会变,如果一个实例的IP不固定,随时会变化,那么服务的消费者如何才能寻址呢?Kubernetes通过引入Service这样一个概念来解决这个问题,简单来讲,Service屏蔽了应用的IP寻址和负载均衡这些细节,消费方可以直接通过服务名访问目标服务,Kubernetes中Service的底层机制会做IP寻址和负载均衡,即使POD的IP发生了变更,Service也会屏蔽这个变更,让消费方无感知。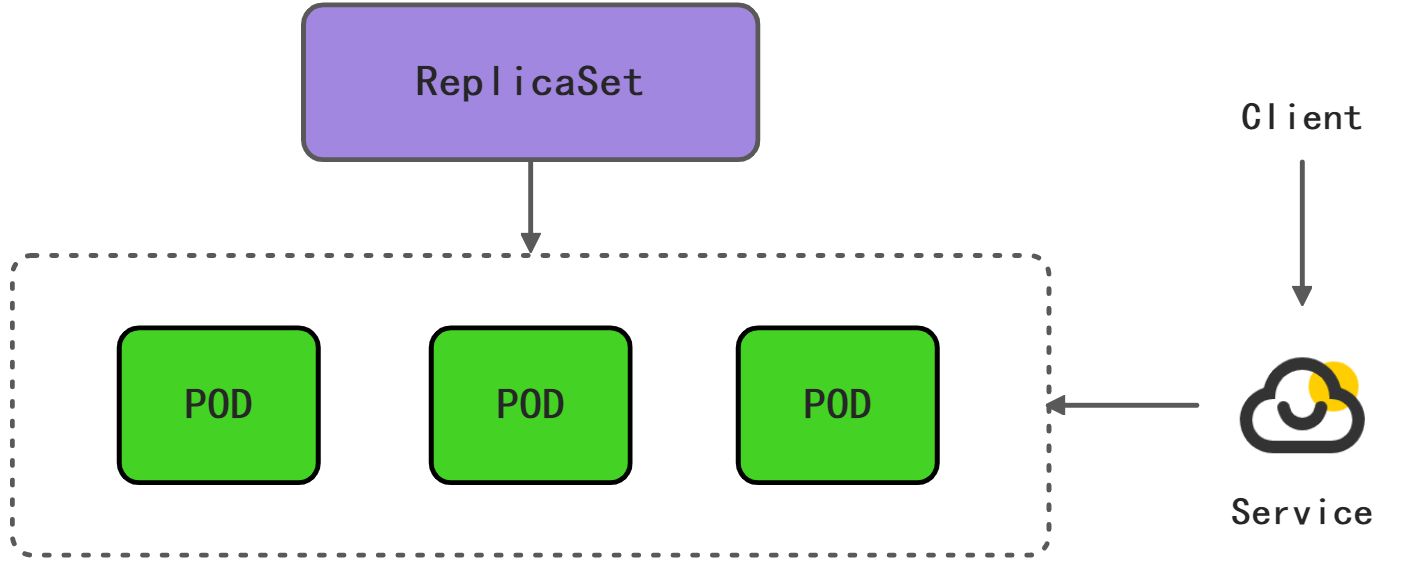
发布Deployment
副本集可以认为是一种最基础的发布机制,通过ReplicaSet副本集可以实现基本应用的发布,也可以实现高级的发布,比如说金丝雀、蓝绿发布以及滚动发布,但是这个操作起来比较繁琐,为了简化这些高级的发布,在ReplicaSet基础上,Kubernetes又引入了Deployment这个概念。简单来说Deployment就是用来管理ReplicaSet,实现蓝绿、滚动这些高级发布机制。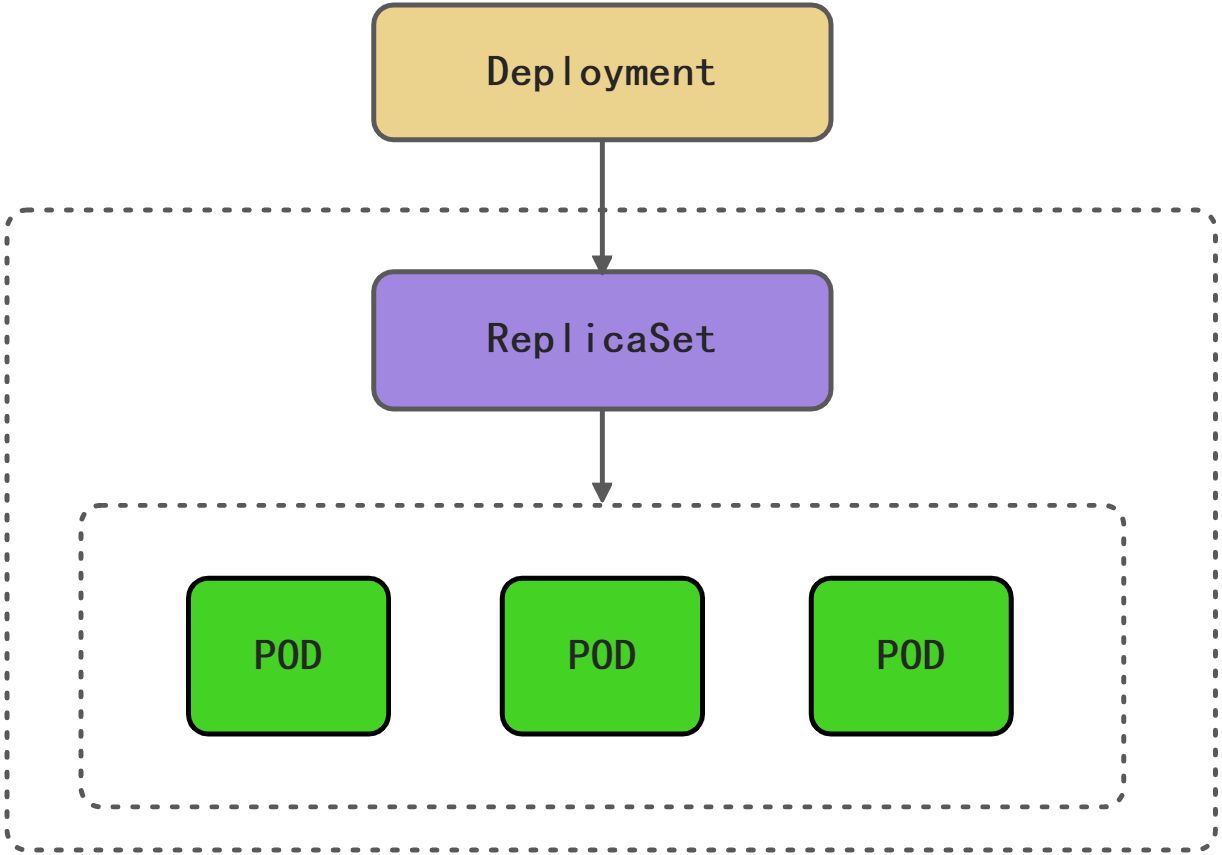
滚动发布Rolling Update

发布和服务总结

ConfigMap/Secret
微服务在上线时,需要用到一些可变的配置,这些配置对应不同环境配置的值也不一样,这些配置有些是在启动时一次性要配置好的,比如数据库连接的URL,还有一些是需要在运行期进行动态调整的,比如说缓存的过期值,业务商品的限购数量等,所以微服务需要配置中心的支持,针对不同环境的灵活配置。Kubernetes平台内置微服务的动态配置——ConfigMap,他是Kubernetes平台支持的一种资源,开发者人员只需要将配置填写在ConfigMap当中,Kubernetes支持将ConfigMap中的配置以环境变量的方式注入到POD里面。这样POD里面的容器就可以以环境变量的方式获取到这些配置值。
ConfigMap也支持以持久卷Volume的形式Mount到POD当中,POD中的应用就可以以配置文件的形式来访问配置。
有些配置是涉及敏感数据的,Kubernetes通过Secret这个概念支持敏感数据的配置,Secret可以看作一种特殊的Config,他提供更安全存储和访问配置的机制。
DaemonSet
还有一种场景就是在每个节点上常驻一个守护进程,比如说监控场景,日志采集场景。针对这种场景Kubernetes支持DaemonSet这样一个发布概念,可以在每个Worker Node上面部署一个守护进程POD,并且保证每个节点上有且仅有一个这样的POD。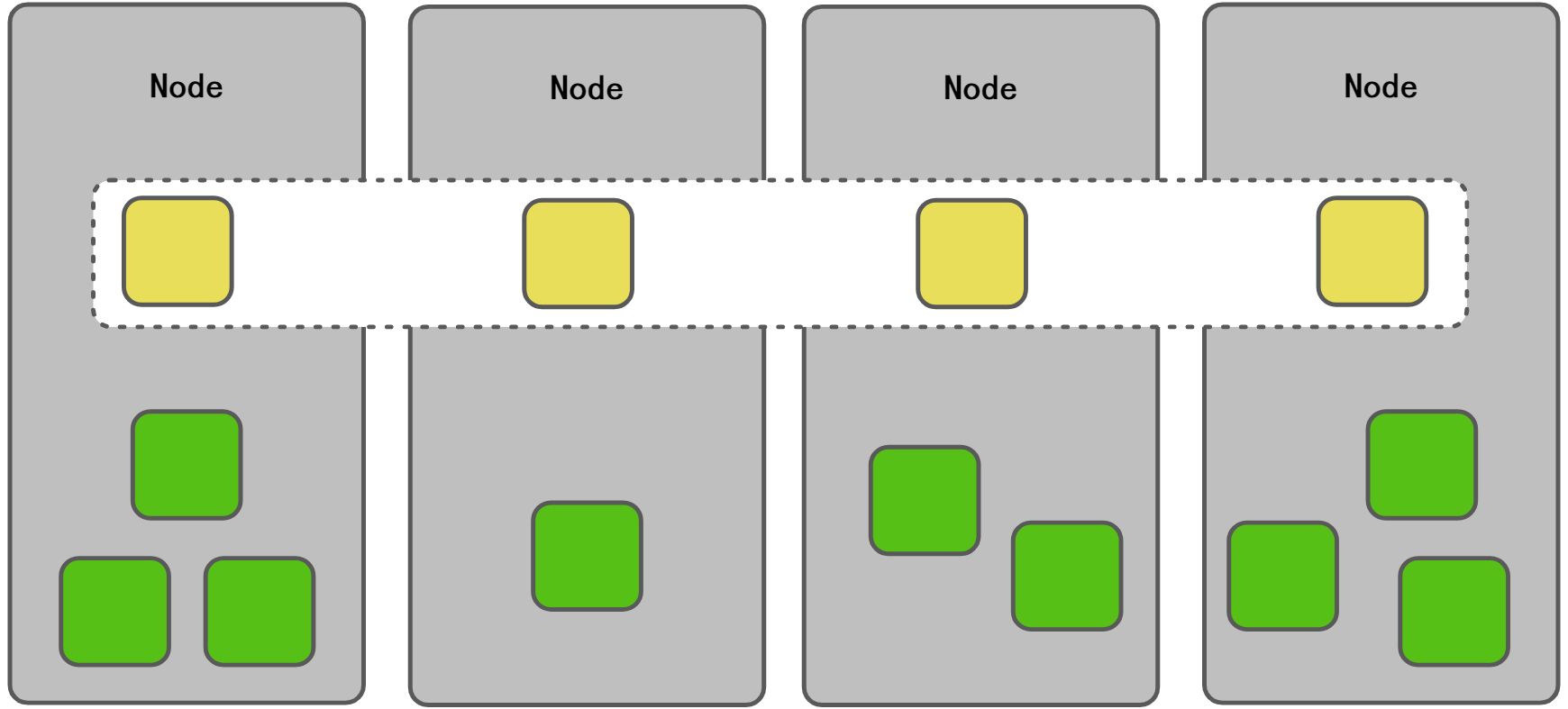
其他概念

- Volume(存储卷):可以简单理解为磁盘文件存储,可以是节点本地文件存储,也可以是远程文件存储,挂载Volume之后,Volume成为POD的一部分,POD销毁Volume也销毁。但是支持Volume的存储还存在。
- PersistentVolume(持久卷):如果Volume只用节点文件的本地存储,那么下次容器重启可能换一个节点,那么相应的文件存储就不存在了,持久卷简称PB,是一种高级的存储资源抽象,可以对接各种云存储,一般由集群管理员统一配置,如果把Kubernetes看作一个超大的计算机,那么PB可以看作灵活的插到这台计算机上的磁盘,如果使用PB挂载Volume,那么应用重启Volume上的数据不会丢,可以继续存在。
- PersistentVolumeClaims:这个是应用升级PB时需要填写的规范,包括磁盘大小类型等等。简称PVC。
- StateSet:支持有状态应用的发布机制,比如要发布MySQL数据库或者Redis缓存。
- Job:支持跑一次任务。
- CronJob:支持周期性跑任务,定时任务等。
- Label/Selector:Label是给Kubernetes中资源打标签的机制,比方说可以是POD上面打标签,这个POD是属于后端的还是前端的,是生产的Prod还是Staging,都可以使用Label来打标签,还可以包含版本信息等等。Selector是通过标签来查询资源的一种机制,比如说可以通过Selector查询出所有Prod环境并且是Frontend的POD。
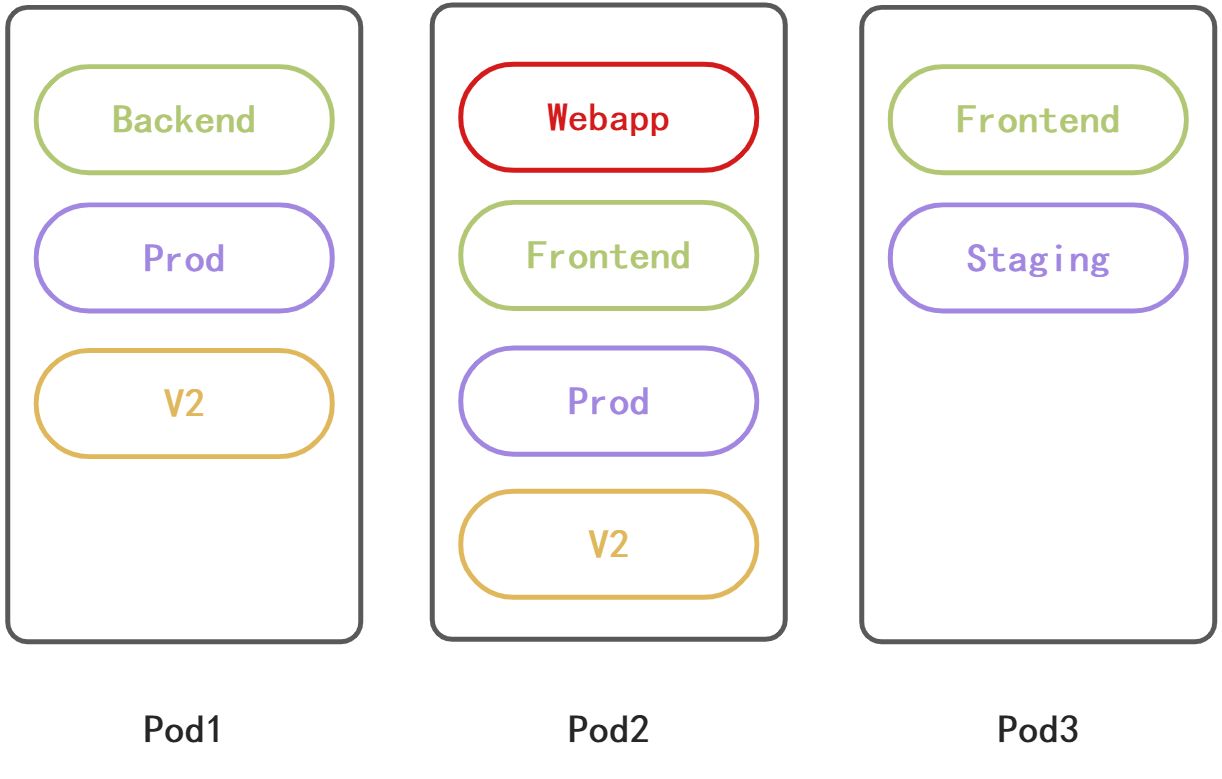
- Namespace:Kubernetes中逻辑隔离机制,基于Namespace可以实现多租户,环境,项目以及团队的逻辑隔离,可以限制配额。创建资源时如果未指定Namespace,那么创建的Namespace都在缺省的Namespace下面。

- Readiness Probe(就绪探针):Kubernetes支持就绪探针,用于判断POD是否可以接入流量,通过应用的Health健康检查端点可以检查这个POD是否就绪,就绪的话就可以接入流量,未就绪就不接入流量。
- Liveiness Probe(活跃探针):用于判断POD是否存活,通过应用的Health健康检查端点可以定期检查POD是否存活,不存活就kill掉这个POD,并根据配置的策略决定是否要重启这个POD。
Kubernetes概念总结
| 概念 | 作用 | | —- | —- | | Cluster | 超大计算机抽象,由节点组成 | | Container | 应用居住和运行在容器在 | | Pod | Kubernetes基本的调度单位 | | ReplicaSet | 创建和管理Pod,支持无状态应用 | | Service | 应用Pods的访问点,屏蔽IP寻址和负载均衡 | | Deployment | 管理ReplicaSet,支持滚动等高级发布机制 | | ConfigMap/Secrets | 应用配置,secret敏感数据配置 | | DaemonSet | 保证每个节点有且仅有一个Pod,常见于监控 | | StatefulSet | 类似ReplicaSet,但支持有状态应用 | | Job | 运行一次就结束的任务 | | CronJob | 周期性运行的任务 | | Volume | 可装载磁盘文件存储 | | PersisentVolume/PersistenVolumeClaims | 超大磁盘存储抽象和分配机制 | | Label/Selector | 资源打标签和定位机制 | | Namespace | 资源逻辑隔离机制 | | Readiness Probe | 就绪探针,流量接入Pod判断依据 | | Liveiness Probe | 存活探针,是否Kill Pod的判断依据 |
Kubernetes节点网络和Pod网络
节点和Pod网络

Service寻址
POD在Kubernetes中是不固定的,POD的IP可能会变化,这个变化可能是预期的,也可能是非预期的,另外一个应用一般是有一组POD组成集群的,来实现高可用HA,这里面就有一个负载均衡的问题,客户端要以负载均衡的方式去访问目标或者实例,如果将负载均衡的逻辑交给客户端自己去处理,就会增加客户端的复杂性,为了解决上述问题,Kubernetes引入了Service的概念,Service可以屏蔽POD的地址变化,同时也实现对目标POD实例负载均衡的访问,由于Service抽象的屏蔽作用,需要访问Service,一般通过ServiceName就可以访问到对应的访问,不需要关心底层POD的IP地址以及负载均衡的这些细节,所以在POD底层网络的基础之上,Kubernetes引入了第三层网络——Service网络。
如果在Kubernetes集群中发布了对应的POD和Service,可以通过kubectl命令查看Service对应的CLUSTER-IP,Service网络和POD网络不在同一个地址空间,对应的访问具体流程如下所示:
thing IP network----- -- -------pod1 10.0.1.2 10.0.0.0/14pod2 10.0.2.2 10.0.0.0/14service 10.3.241.152 10.3.240.0/20$ kubectl get service service-testNAME CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice-test 10.3.241.152 <none> 80/tcp 11s
Service网络寻址——用户空间代理模式
用户空间代理模式可以实现Kubernetes的Service网络,并且早起的Kubernetes版本,1.2之前就是基于用户代理模式实现服务网络和服务发现。
但是他存在一个问题:用户空间代理模式比较重,在用户空间和内核空间进行迁移是有一定的开销的。
为了提升性能,新的Kubernetes版本1.2以后采用了iptables/ipvs模式。
Service网络寻址——iptables/ipvs模式
ipvs也是Linux内核的包路由转发机制,他的性能更高,他是Kubernetes 1.8引入的,ipvs这种模式,在请求包截获之后,并不是交给kube-proxy进行转发,而是netfilter通过修改iptables或者ipvs这种规则直接进行转发,这样就省去了额外的内核空间和用户空间的迁移的开销。
在这种模式下,kube-proxy的职责大大简化了,基本上只要将服务器信息同步个netfilter就可以了,netfilter是一种内核机制,性能高,而且稳定。
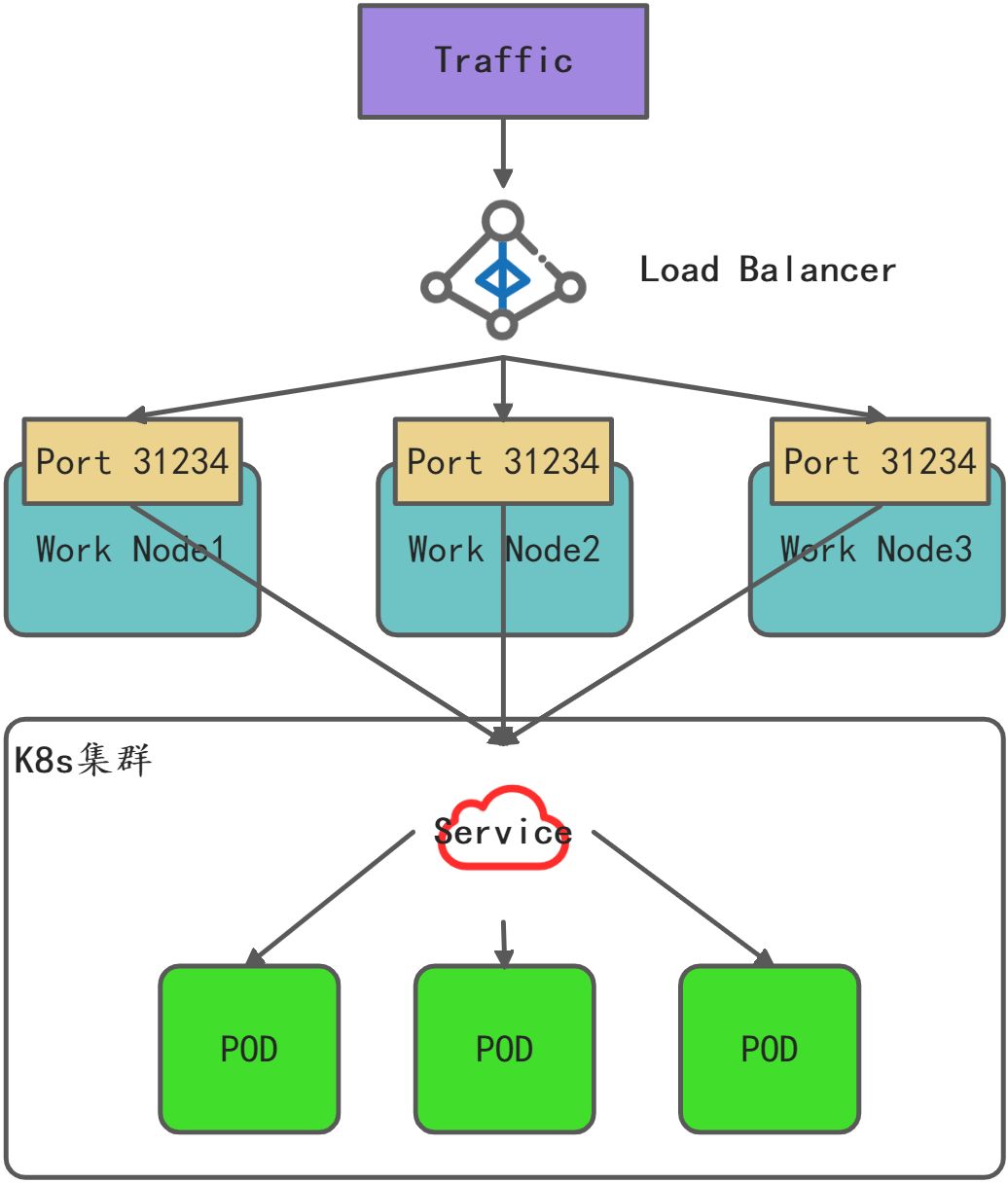
NodePort vs LoadBalancer vs Ingress
外部流量对Service寻址

NodePort

Load Balancer
Ingress

总结
| 作用 | 实现 | |
|---|---|---|
| 节点网络 | Master/Worker节点之间网络互通 | 路由器,交换机,网卡 |
| Pod网络 | Pod之间互通 | 虚拟网卡,虚拟网桥,路由器 |
| Service网络 | 屏蔽Pod地址变化+负载均衡 | Kube-proxy,Netfilter,Api-Server,DNS |
| NodePort | 将Service暴露在节点网络之上 | Kube-proxy+Netfilter |
| LoadBalancer | 将Service暴露在公网上+负载均衡 | 公有云LB+NodePort |
| Ingress | 反向路由,安全,日志监控(类似反向代理 or 网关) | Nginx/Envoy/Traefik/Faraday |

若有收获,就点个赞吧
0 人点赞
