Java SpringBoot Sharding-JDBC 分库分表
分库分表带来的问题
从单一表、单一库切分成多库、多表对于性能的提升是必然的,但是同时也带来了一些问题。
1、分布式事务问题
由于垂直分库、水平分库,将数据分摊在不同库中,甚至不同的服务器上,势必带来了分布式事务的问题。
对于单库单表的事务很好控制,分布式事务的控制却是非常头疼,但是好在现在已经有成熟的解决方案。
2、跨节点关联join问题
在切分之前关联查询非常简单,直接SQL JOIN便能解决,但是切分之后数据分摊在不同的节点上,此时JOIN就比较麻烦了,因此切分之后尽量避免JOIN。
解决这一问题的有些方法:
1、全局表
这种很好理解,对于一些全局需要关联的表可以在每个数据节点上都存储一份,一般是一些数据字典表。
全局表在Sharding-JDBC称之为广播表
2、字段冗余
这是一种典型的反范式设计,为了避免关联JOIN,可以将一些冗余字段保存,比如订单表保存userId时,可以将userName也一并保存,这样就避免了和User表的关联JOIN了。
字段冗余这种方案存在数据一致性问题
3、数据组装
这种还是比较好理解的,直接不使用JOIN关联,分两次查询,从第一次的结果集中找出关联数据的唯一标识,然后再次去查询,最后对得到的数据进行组装
需要进行手动组装,数据很大的情况对CPU、内存有一定的要求
4、绑定表
对于相互关联的数据节点,通过分片规则将其切分到同一个库中,这样就可以直接使用SQL的JOIN 进行关联查询。
Sharding-JDBC中称之为绑定表,比如订单表和用户表的绑定
3、跨节点分页、排序、函数问题
对于跨数据节点进行分页、排序或者一些聚合函数,筛选出来的仅仅是针对当前节点,比如排序,仅仅能够保证在单一数据节点上是有序,并不能保证在所有节点上都是有序的,需要将各个节点的数据的进行汇总重新手动排序。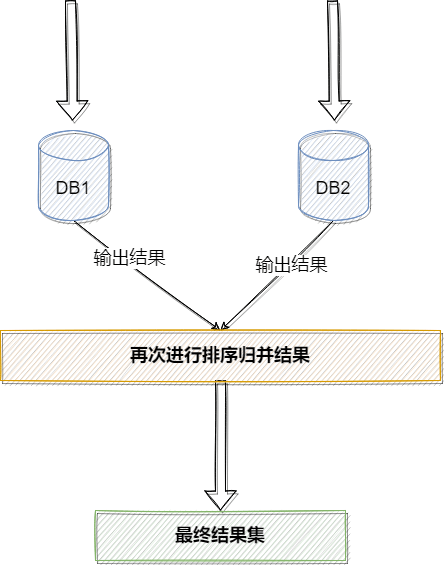
Sharding-JDBC 正是 按照上述流程进行分页、排序、聚合
4、全局主键避重问题
单库单表一般都是使用的自增主键,但是在切分之后每个自增主键将无法使用,因为这样会导致数据主键重复,因此必须重新设计主键。
目前主流的分布式主键生成方案如下:
1、UUID
UUID应该是大家最为熟悉的一种方案,优点非常明显本地生成,性能高,缺点也很明显,太长了存储耗空间,查询也非常耗性能,另外UUID的无序性将会导致InnoDB下的数据位置变动。
2、Snowflake
Twitter开源的由64位整数组成分布式ID,性能较高,并且在单机上递增。
3、UidGenerator
UidGenerator是百度开源的分布式ID生成器,其基于雪花算法实现。具体参考:
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
4、Leaf
Leaf是美团开源的分布式ID生成器,能保证全局唯一,趋势递增,但需要依赖关系数据库、Zookeeper等中间件。具体参考:https://tech.meituan.com/2017/04/21/mt-leaf.html
5、数据迁移、扩容问题
当业务高速发展,面临性能和存储的瓶颈时,才会考虑分片设计,此时就不可避免的需要考虑历史数据迁移的问题。一般做法是先读出历史数据,然后按指定的分片规则再将数据写入到各个分片节点中。此外还需要根据当前的数据量和QPS,以及业务发展的速度,进行容量规划,推算出大概需要多少分片。
如果采用数值范围分片,只需要添加节点就可以进行扩容了,不需要对分片数据迁移。如果采用的是数值取模分片,则考虑后期的扩容问题就相对比较麻烦。
分库分表虽然提升了性能,但是在切分过程中一定要考虑上述总结的5种问题。
Sharding-JDBC 介绍
Sharding-JDBC 是当当网研发的开源分布式数据库中间件,从 3.0 开始Sharding-JDBC被包含在 Sharding-Sphere 中,之后该项目进入进入Apache孵化器,4.0版本之后的版本为Apache版本。
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,由Sharding-JDBC、Sharding-Proxy、Sharding-Sidecar(规划中)组成。
官网:https://shardingsphere.apache.org
目前只需要关注Sharding-JDBC,后面的两种组件后文介绍。
Sharding-JDBC 的定位是一款轻量级JAVA框架,基于JDBC实现分库分表,通过Sharding-JDBC可以透明的访问已经经过分库、分表的数据源。
Sharding-JDBC的特性如下:
- 适用于任何基于Java的ORM框架,如:Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
Sharding-JDBC 中的一些概念
在介绍Sharding-JDBC 实战之前需要了解其中的一些概念,如下:1、逻辑表
在对表进行分片后,一张表分成了n个表,比如订单表t_order分成如下三张表:t_order_1,t_order_2,t_order_3。
此时订单表的逻辑表就是t_order,Sharding-JDBC在进行分片规则配置时针对的就是这张逻辑表2、真实表
上述t_ordr_1,t_order_2,t_order_3 称之为 真实表3、数据节点
数据分片的最小单元,由数据源名称和表名称组成,比如:ds1.t_order_14、分片键
用于分片的数据库字段,是将数据库(表)水平拆分的关键字段。例:将订单表中的订单主键的尾数取模分片,则订
单主键为分片字段。SQL中如果无分片字段,将执行全路由,性能较差。除了对单分片字段的支持,Sharding- Jdbc也支持根据多个字段进行分片。5、分片算法
通过分片算法将数据分片,支持通过=、BETWEEN和IN分片。
分片算法需要应用方开发者自行实现,可实现的灵 活度非常高。包括:精确分片算法 、范围分片算法 ,复合分片算法 等。例如:where order_id = ?将采用精确分片算法,where order_id in (?,?,?)将采用精确分片算法,where order_id BETWEEN ? and ?将采用范围分片算 法,复合分片算法用于分片键有多个复杂情况。
Sharding-JDBC 中的分片算法需要开发者根据业务自定义6、分片策略
包含分片键和分片算法,由于分片算法的独立性,将其独立抽离。真正可用于分片操作的是分片键 + 分片算法,也 就是分片策略。
内置的分片策略大致可分为尾数取模、哈希、范围、标签、时间等。由用户方配置的分片策略则更加灵活,常用的使用行表达式配置分片策略,它采用Groovy表达式表示,如: tuser$->{u_id % 8} 表示t_user 表根据u_id模8,而分成8张表,表名称为 t_user_0 到 t_user_7 。1、标准分片策略
标准分片策略适用于单分片键,此策略支持 PreciseShardingAlgorithm 和 RangeShardingAlgorithm 两个分片算法。
其中 PreciseShardingAlgorithm 是必选的,用于处理 = 和 IN 的分片。RangeShardingAlgorithm 是可选的,用于处理BETWEEN AND, >, <,>=,<= 条件分片,如果不配置RangeShardingAlgorithm,SQL中的条件等将按照全库路由处理。2、复合分片策略
复合分片策略,同样支持对 SQL语句中的 =,>, <, >=, <=,IN和 BETWEEN AND 的分片操作。不同的是它支持多分片键,具体分配片细节完全由应用开发者实现。3、行表达式分片策略
行表达式分片策略,支持对 SQL语句中的 = 和 IN 的分片操作,但只支持单分片键。这种策略通常用于简单的分片,不需要自定义分片算法,可以直接在配置文件中接着写规则。
torder$->{t_order_id % 4} 代表 t_order 对其字段 t_order_id取模,拆分成4张表,而表名分别是t_order_0 到 t_order_3。4、Hint分片策略
Hint分片策略,对应上边的Hint分片算法,通过指定分片健而非从 SQL中提取分片健的方式进行分片的策略。7、分布式主键生成策略
通过在客户端生成自增主键替换以数据库原生自增主键的方式,做到分布式主键无重复。
Sharding-JDBC 内部支持UUID和Snowflake生成分布式主键Sharding-JDBC 实战
上述内容基本介绍了Sharding-JDBC的基本知识点,下面通过 Spring Boot + Sharding-JDBC 的方式实战演示一下。1、Sharding-JDBC 的 pom 依赖
想要使用Sharding-JDBC只需要添加一个maven依赖即可,如下:<dependency><groupId>org.apache.shardingsphere</groupId><artifactId>sharding-jdbc-spring-boot-starter</artifactId><version>${sharding-sphere.version}</version></dependency>
2、垂直分表、分库
垂直切分一般针对数据行数不大,但是单行的某些字段数据很大,表占用空间很大,检索的时候需要执行大量的IO,严重降低性能,此时需要将拆分到另外一张表,且与原表是一对一的关系,这就是垂直分表。
比如商品表中的商品描述数据很大,严重影响查询性能,可以将商品描述这个字段单独抽离出来存储,这样就拆分成了两张表(垂直分表),如下图:
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限 制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个 表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
此时就需要进行垂直分库,如下之前是在单独的卖家库存储的,现在需要将商品的信息给垂直切分出去,分成了两个库:商品库product_db、店铺库shop_db:
方案已经有了,那么现在就需要用Sharding-JDBC去实现。
Sharding-JDBC 使用非常简单,只需要在配置文件中指定数据源信息和切片规则即可实现分库分表。
这里支持三种配置,如下:
- yml配置文件
- properties配置文件
- Java Config 编码配置
这里使用的是第一种yml配置方式,详细配置如下:
spring:# Sharding-JDBC的配置shardingsphere:datasource:# 数据源,这里配置两个,分别是ds1,ds2names: ds1,ds2# ds1的配置信息,product_db1ds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/product_db?useUnicode=true&characterEncoding=utf-8username: rootpassword: Nov2014# ds2的配置信息,shop_dbds2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/shop_db?useUnicode=true&characterEncoding=utf-8username: rootpassword: Nov2014# 分片的配置sharding:# 表的分片策略tables:## product_base是逻辑表的名称product_base:# 数据节点配置,采用Groovy表达式,切分之后的真实表所在的节点actual-data-nodes: ds$->{1}.product_base# 主键生成策略key-generator:# 主键column: product_id# 生成算法type: SNOWFLAKEproduct_description:# 数据节点配置,采用Groovy表达式actual-data-nodes: ds$->{1}.product_descriptionshop:# 数据节点配置,采用Groovy表达式actual-data-nodes: ds$->{2}.shop# 主键生成策略key-generator:# 主键column: shop_id# 生成算法type: SNOWFLAKEprops:sql:# 日志显示具体的SQLshow: true
1、数据源配置
由于垂直分库涉及到shop_db,product_db,肯定是要配置两个数据源,如下:
spring:# Sharding-JDBC的配置shardingsphere:datasource:# 数据源,这里配置两个,分别是ds1,ds2names: ds1,ds2# ds1的配置信息,product_db1ds1:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/product_db?useUnicode=true&characterEncoding=utf-8username: rootpassword: Nov2014# ds2的配置信息,shop_dbds2:type: com.alibaba.druid.pool.DruidDataSourcedriver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/shop_db?useUnicode=true&characterEncoding=utf-8username: rootpassword: Nov2014
这个很好理解,两个数据源名称分别为ds1,ds2,自己任意取名,然后配置相关信息。
2、数据节点配置
这里数据节点很重要,要告诉Sharding-JDBC 要操作的那张表在哪个库中,对应表的名称。
上述涉及到三张表,分别是shop、product_base、product_description,因此需要配置三个数据节点,如下:
spring:# Sharding-JDBC的配置shardingsphere:# 分片的配置sharding:# 表的分片策略tables:## product_base是逻辑表的名称product_base:# 数据节点配置,采用Groovy表达式,切分之后的真实表所在的节点actual-data-nodes: ds$->{1}.product_baseproduct_description:# 数据节点配置,采用Groovy表达式actual-data-nodes: ds$->{1}.product_descriptionshop:# 数据节点配置,采用Groovy表达式actual-data-nodes: ds$->{2}.shop
**ds$->{1}** 采用的是Groovy表达式,表示ds1
数据节点要具体到指定的数据库、表名。spring.shardingsphere.sharding.default-data-source-name=ds1可以指定默认的数据源
3、主键生成策略
Sharding-JDBC支持配置主键生成策略,比如使用雪花算法或者UUID方式,配置如下:
spring:# Sharding-JDBC的配置shardingsphere:# 分片的配置sharding:# 表的分片策略tables:## product_base是逻辑表的名称product_base:# 主键生成策略key-generator:# 主键column: product_id# 生成算法type: SNOWFLAKEshop:# 主键生成策略key-generator:# 主键column: shop_id# 生成算法type: SNOWFLAKE
SNOWFLAKE:雪花算法
配置完成后,向product_base插入一条数据,将会直接插入到ds1这个数据库中,demo如下:
@Testpublic void test1(){Product product = Product.builder().name("Spring Cloud Alibaba").price(159L).originAddress("Fcant").shopId(1L).build();productMapper.insertProductBase(product);}
3、水平分库
问题来了,现在有很多商家入驻,product_db单库存储数据已经超出预估,商品资源属于访问非常频繁的资源,单台服务器已经无法支撑,此时就需要对其进行水平分库,将商品库拆分成两个数据库:product_db1、product_db2,如下:
product_db1+product_db2数据合并则为完整的商品数据
Sharding-JDBC 配置也很简单,只需要配置一下数据库的切分规则,配置规则如下:
#分库策略,如何将一个逻辑表映射到多个数据源spring.shardingsphere.sharding.tables.<逻辑表名称>.database‐strategy.<分片策略>.<分片策略属性名>=
那么此时需要对product_base、product_description进行数据源切分,按照对2取模的方式,配置如下:
spring:# Sharding-JDBC的配置shardingsphere:# 分片的配置sharding:# 表的分片策略tables:product_base:database‐strategy:inline:## 分片键sharding‐column: product_id## 分片算法,内置的精确算法algorithm‐expression: ds$->{product_id%2+1}product_description:database‐strategy:inline:## 分片键sharding‐column: product_id## 分片算法,内置的精确算法algorithm‐expression: ds$->{product_id%2+1}
上述配置什么意思?
product_id是偶数的将会存储在product_db1库中,奇数的存储在product_db2中
测试也很简单,循环往数据库中插入10条商品数据,由于是雪花算法,因此应该有5条在db1库中,另外5条在db2中,单元测试如下:
@Testpublic void test3(){for (int i = 0; i < 10; i++) {Product product = Product.builder().name("Spring Cloud Alibaba").price(159L).originAddress("Fcant").shopId(1L).build();productMapper.insertProductBase(product);productMapper.insertProductDescribe(product.getProductId(),"内容",product.getShopId());}}
观察下控制台的SQL,可以发现是不停的往ds1和ds2中进行插入数据。
4、水平分表
经过水平分库后,性能得到了提升,但是经过一段时间后,商品的单表数据量急剧增长,查询非常慢,那么此时就需要对单表进行水平拆分了,如下图:
同样需要在Sharding-JDBC中配置分表的规则,如下:
#分表策略,如何将一个逻辑表映射为多个实际表spring.shardingsphere.sharding.tables.<逻辑表名称>.table‐strategy.<分片策略>.<分片策略属性名>=
实际的配置如下:
spring:# Sharding-JDBC的配置shardingsphere:# 分片的配置sharding:# 表的分片策略tables:product_base:# 数据节点配置,采用Groovy表达式,分库分表策略,这样是4个节点,ds1.product_base_$_1/ds1.product_base_$_2/ds2.product_base_$_1/ds2.product_base_$_2actual-data-nodes: ds$->{1..2}.product_base_$->{1..2}# 分表策略table‐strategy:inline:# 分片键为店铺IDsharding‐column: shop_id# 分片策略取模algorithm‐expression: product_base_$->{shop_id%2+1}product_description:# 数据节点配置,采用Groovy表达式actual-data-nodes: ds$->{1..2}.product_description_$->{1..2}table‐strategy:inline:sharding‐column: shop_idalgorithm‐expression: product_description_$->{shop_id%2+1}
这里需要注意的是:由于这里用了分库分表,那么数据节点一定要配置对,比如 ds$->{1..2}.product_base_$->{1..2} 这里的表达式分别对应的是4个数据节点,如下:
- ds1.productbase$_1
- ds1.productbase$_2
- ds2.productbase$_1
- ds2.productbase$_2
单元测试如下:
@Testpublic void test4(){for (int i = 0; i < 10; i++) {Product product = Product.builder().name("Spring Cloud Alibaba").price(159L).originAddress("Fcant").shopId((long)(new Random().nextInt(100)+1)).build();productMapper.insertProductBase(product);productMapper.insertProductDescribe(product.getProductId(),"内容",product.getShopId());}}

若有收获,就点个赞吧
0 人点赞
