前言
数据序列化存储,或者数据通过网络传输时,会遇到不可避免将数据转成字节数组的场景。字节数组的读写不会太难,但又有点繁琐,为了避免重复造轮子,jdk推出了ByteBuffer来帮助操作字节数组;而Netty是一款当前流行的java网络IO框架,它内部定义了一个ByteBuf来管理字节数组,和ByteBuffer大同小异
ByteBuffer- 零拷贝之
MappedByteBuffer DirectByteBuffer堆外内存回收机制-
Buffer结构
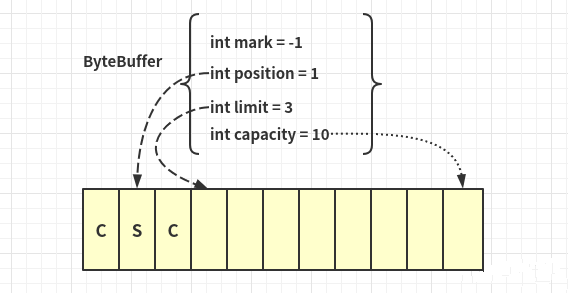
public abstract class Buffer {//关系: mark <= position <= limit <= capacityprivate int mark = -1;private int position = 0;private int limit;private int capacity;long address; // Used only by direct buffers,直接内存的地址}
mark:调用mark()方法的话,mark值将存储当前position的值,等下次调用reset()方法时,会设定position的值为之前的标记值position:是下一个要被读写的byte元素的下标索引limit:是缓冲区中第一个不能读写的元素的数组下标索引,也可以认为是缓冲区中实际元素的数量capacity:是缓冲区能够容纳元素的最大数量,这个值在缓冲区创建时被设定,而且不能够改变Buffer.API
Buffer(int mark, int pos, int lim, int cap)//Buffer创建时设置的最大数组容量值public final int capacity()//当前指针的位置public final int position()//限制可读写大小public final Buffer limit(int newLimit)//标记当前position的位置public final Buffer mark()//配合mark使用,position成之前mark()标志的位置。先前没调用mark则报错public final Buffer reset()//写->读模式翻转,单向的//position变成了初值位置0,而limit变成了写模式下position位置public final Buffer flip()//重置position指针位置为0,mark为-1;相对flip方法是limit不变public final Buffer rewind() //复位//和rewind一样,多出一步是limit会被设置成capacitypublic final Buffer clear()//返回剩余未读字节数public final int remaining()
ByteBuffer结构
public abstract class ByteBuffer extends Buffer implements Comparable<ByteBuffer>{final byte[] hb; //仅限堆内内存使用final int offset;boolean isReadOnly;}
ByteBuffer.API
//申请堆外内存public static ByteBuffer allocateDirect(int capacity)//申请堆内内存public static ByteBuffer allocate(int capacity)//原始字节包装成ByteBufferpublic static ByteBuffer wrap(byte[] array, int offset, int length)//原始字节包装成ByteBufferpublic static ByteBuffer wrap(byte[] array)//创建共享此缓冲区内容的新字节缓冲区public abstract ByteBuffer duplicate()//分片,创建一个新的字节缓冲区//新ByteBuffer的开始位置是此缓冲区的当前位置positionpublic abstract ByteBuffer slice()//获取字节内容public abstract byte get()//从ByteBuffer偏移offset的位置,获取length长的字节数组,然后返回当前ByteBuffer对象public ByteBuffer get(byte[] dst, int offset, int length)//设置byte内存public abstract ByteBuffer put(byte b);//以offset为起始位置设置length长src的内容,并返回当前ByteBuffer对象public ByteBuffer put(byte[] src, int offset, int length长)//将没有读完的数据移到到缓冲区的初始位置,position设置为最后一没读字节数据的下个索引,limit重置为为capacity//读->写模式,相当于flip的反向操作public abstract ByteBuffer compact()//是否是直接内存public abstract boolean isDirect()
ByteBuffer bf = ByteBuffer.allocate(10);,创建大小为10的ByteBuffer对象
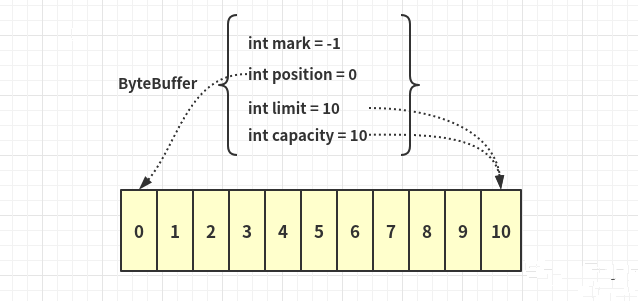
写入数据
ByteBuffer buf ByteBuffer.allocate(10);buf.put("csc".getBytes());
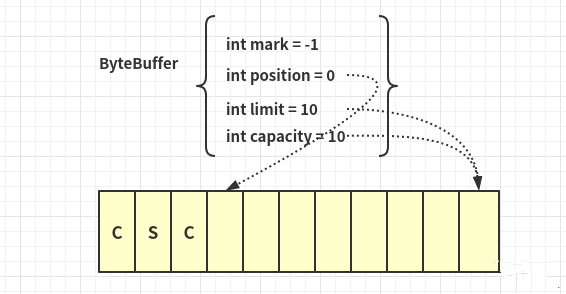
调用flip转换缓冲区为读模式;
buf.flip();
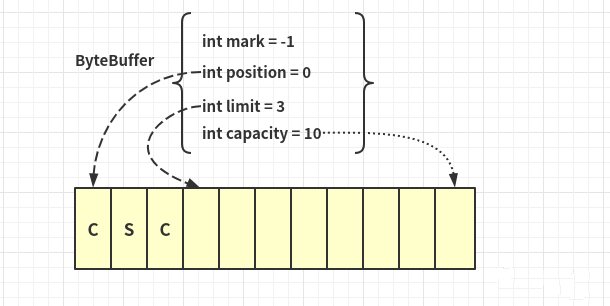
- 读取缓冲区中到内容:
get();System.out.println((char) buf.get());
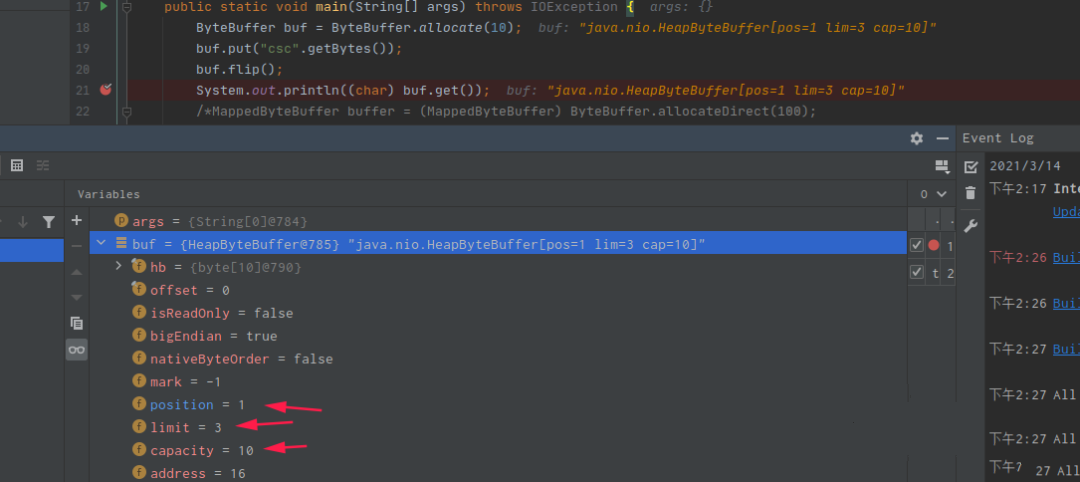
零拷贝之MappedByteBuffer
- 共享内存映射文件,对应的
ByteBuffer子操作类,MappedByteBuffer是基于mmap实现的。MappedByteBuffer需要FileChannel调用本地map函数映射。C++代码可以查阅下FileChannelImpl.c-Java_sun_nio_ch_FileChannelImpl_map0方法 - 使用MappedByteBuffer和文件映射,其读写可以减少内存拷贝次数
FileChannel readChannel = FileChannel.open(Paths.get("./cscw.txt"), StandardOpenOption.READ);MappedByteBuffer data = readChannel.map(FileChannel.MapMode.READ_ONLY, 0, 1024 * 1024 * 40);
下面看看直接内存的回收机制(java8);DirectByteBuffer堆外内存回收机制CleanerDirectByteBuffer内部存在一个Cleaner对象,并且委托内部类Deallocator对象进行内存回收
细看下class DirectByteBuffer extends MappedByteBuffer implements DirectBuffer{//构造函数DirectByteBuffer(int cap) {.... //内存分配cleaner = Cleaner.create(this, new Deallocator(base, size, cap));...}private static class Deallocator implements Runnable{...public void run() {if (address == 0) {// Paranoiareturn;}unsafe.freeMemory(address); //回收内存address = 0;Bits.unreserveMemory(size, capacity);}}
Cleaner,继承于PhantomReference,并且在public void clean()方法会调用Deallocator进行清除操作
在public class Cleaner extends PhantomReference<Object> {//如果DirectByteBuffer对象被回收,相应的Cleaner会被放入dummyQueue队列private static final ReferenceQueue<Object> dummyQueue = new ReferenceQueue();//构造函数public static Cleaner create(Object var0, Runnable var1) {return var1 == null ? null : add(new Cleaner(var0, var1));}private Cleaner(Object var1, Runnable var2) {super(var1, dummyQueue);this.thunk = var2;}private final Runnable thunk;public void clean() {if (remove(this)) {try {this.thunk.run();} catch (final Throwable var2) {....
Reference内部存在一个守护线程,循环获取Reference,并判断是否Cleaner对象,如果是则调用其clean方法 ```java public abstract class Referencestatic {
} … //内部类调用 tryHandlePending private static class ReferenceHandler extends Thread {ThreadGroup tg = Thread.currentThread().getThreadGroup();for (ThreadGroup tgn = tg; tgn != null; g = tgn, tgn = tg.getParent());Thread handler = new ReferenceHandler(tg, "Reference Handler");...handler.setDaemon(true);handler.start();...
… static boolean tryHandlePending(boolean waitForNotify) {public void run() {while (true) {tryHandlePending(true);}}
Cleaner c;.... //从链表获取对象被回收的引用// 判断Reference是否Cleaner,如果是则调用其clean方法if (c != null) {c.clean(); //调用Cleaner的clean方法return true;}ReferenceQueue<? super Object> q = r.queue;if (q != ReferenceQueue.NULL) q.enqueue(r);return true;
<a name="ifzL3"></a>## Netty之`ByteBuf`<a name="ky6Ls"></a>### `ByteBuf`原理- `Bytebuf`通过两个位置指针来协助缓冲区的读写操作,分别是`readIndex`和`writerIndex````java* +-------------------+------------------+------------------+* | discardable bytes | readable bytes | writable bytes |* | | (CONTENT) | |* +-------------------+------------------+------------------+* | | | |* 0 <= readerIndex <= writerIndex <= capacity
ByteBuf.API
//获取ByteBuf分配器public abstract ByteBufAllocator alloc()//丢弃可读字节public abstract ByteBuf discardReadBytes()//返回读指针public abstract int readerIndex()//设置读指针public abstract ByteBuf readerIndex(int readerIndex);//标志当前读指针位置,配合resetReaderIndex使用public abstract ByteBuf markReaderIndex()public abstract ByteBuf resetReaderIndex()//返回可读字节数public abstract int readableBytes()//返回写指针public abstract int writerIndex()//设置写指针public abstract ByteBuf writerIndex(int writerIndex);//标志当前写指针位置,配合resetWriterIndex使用public abstract ByteBuf markWriterIndex()public abstract ByteBuf resetWriterIndex()//返回可写字节数public abstract int writableBytes()public abstract ByteBuf clear();//设置读写指针public abstract ByteBuf setIndex(int readerIndex, int writerIndex)//指针跳过lengthpublic abstract ByteBuf skipBytes(int length)//以当前位置切分ByteBuf todopublic abstract ByteBuf slice();//切割起始位置为index,长度为length的ByteBuf todopublic abstract ByteBuf slice(int index, int length);//Returns a copy of this buffer's readable bytes. //复制ByteBuf todopublic abstract ByteBuf copy()//是否可读public abstract boolean isReadable()//是否可写public abstract boolean isWritable()//字节编码顺序public abstract ByteOrder order()//是否在直接内存申请的ByteBufpublic abstract boolean isDirect()//转为jdk.NIO的ByteBuffer类public abstract ByteBuffer nioBuffer()
使用示例
public static void main(String[] args) {//分配大小为10的内存ByteBuf buf = Unpooled.buffer(10);//写入buf.writeBytes("csc".getBytes());//读取byte[] b = new byte[3];buf.readBytes(b);System.out.println(new String(b));System.out.println(buf.writerIndex());System.out.println(buf.readerIndex());}
----result----
csc33
ByteBuf初始化时,readIndex和writerIndex等于0,调用writeXXX()方法写入数据,writerIndex会增加(setXXX方法无作用);调用readXXX()方法读取数据,则会使readIndex增加(getXXX方法无作用),但不会超过writerIndex- 在读取数据之后,0-
readIndex之间的byte数据被视为discard,调用discardReadBytes(),释放这部分空间,作用类似于ByteBuffer的compact方法

若有收获,就点个赞吧
0 人点赞
