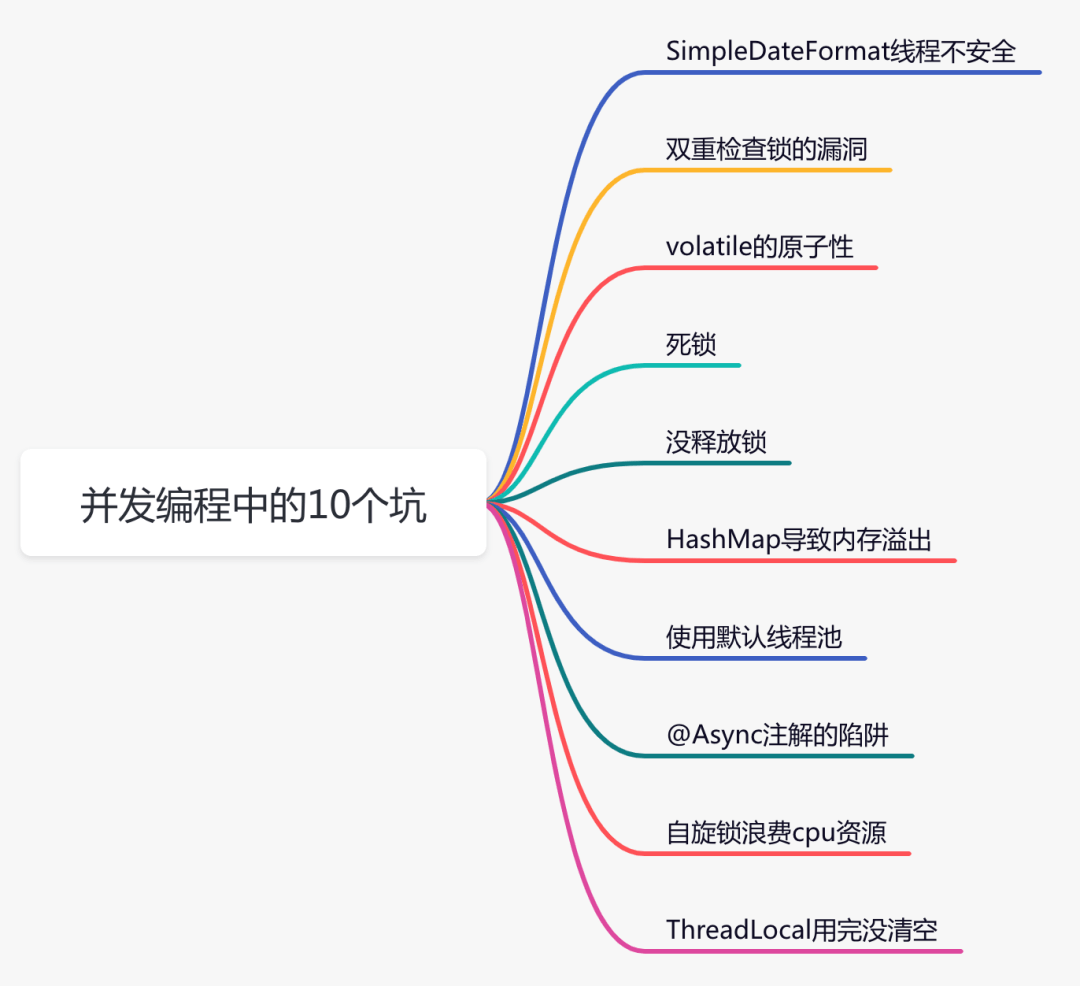
1、SimpleDateFormat线程不安全
在Java8之前,对时间的格式化处理,一般都是用的SimpleDateFormat类实现的。例如:
@Servicepublic class SimpleDateFormatService {public Date time(String time) throws ParseException {SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");return dateFormat.parse(time);}}
如果真的这样写,是没问题的。就怕哪天抽风,觉得dateFormat是一段固定的代码,应该要把它抽取成常量。
于是把代码改成下面的这样:
@Servicepublic class SimpleDateFormatService {private static SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");public Date time(String time) throws ParseException {return dateFormat.parse(time);}}
dateFormat对象被定义成了静态常量,这样就能被所有对象共用。
如果只有一个线程调用time方法,也不会出现问题。
但Serivce类的方法,往往是被Controller类调用的,而Controller类的接口方法,则会被tomcat的线程池调用。换句话说,可能会出现多个线程调用同一个Controller类的同一个方法,也就是会出现多个线程会同时调用time方法的情况。
而time方法会调用SimpleDateFormat类的parse方法:
@Overridepublic Date parse(String text, ParsePosition pos) {...Date parsedDate;try {parsedDate = calb.establish(calendar).getTime();...} catch (IllegalArgumentException e) {pos.errorIndex = start;pos.index = oldStart;return null;}return parsedDate;}
该方法会调用establish方法:
Calendar establish(Calendar cal) {...//1.清空数据cal.clear();//2.设置时间cal.set(...);//3.返回return cal;}
其中的步骤1、2、3是非原子操作。
但如果cal对象是局部变量还好,坏就坏在parse方法调用establish方法时,传入的calendar是SimpleDateFormat类的父类DateFormat的成员变量:
public abstract class DateFormat extends Forma {....protected Calendar calendar;...}
这样就可能会出现多个线程,同时修改同一个对象即:dateFormat,他的同一个成员变量即:Calendar值的情况。
这样可能会出现,某个线程设置好了时间,又被其他的线程修改了,从而出现时间错误的情况。
那么,如何解决这个问题呢?
SimpleDateFormat类的对象不要定义成静态的,可以改成方法的局部变量。- 使用
ThreadLocal保存SimpleDateFormat类的数据。 -
2、双重检查锁的漏洞
单例模式无论在实际工作,还是在面试中,都出现得比较多。
都知道单例模式有:饿汉模式和懒汉模式两种。
饿汉模式代码如下:public class SimpleSingleton {//持有自己类的引用private static final SimpleSingleton INSTANCE = new SimpleSingleton();//私有的构造方法private SimpleSingleton() {}//对外提供获取实例的静态方法public static SimpleSingleton getInstance() {return INSTANCE;}}
使用饿汉模式的好处是:没有线程安全的问题,但带来的坏处也很明显。
private static final SimpleSingleton INSTANCE = new SimpleSingleton();
一开始就实例化对象了,如果实例化过程非常耗时,并且最后这个对象没有被使用,不是白白造成资源浪费吗?
这个时候也许会想到,不用提前实例化对象,在真正使用的时候再实例化不就可以了?
这就是接下来要介绍的:懒汉模式。
具体代码如下:public class SimpleSingleton2 {private static SimpleSingleton2 INSTANCE;private SimpleSingleton2() {}public static SimpleSingleton2 getInstance() {if (INSTANCE == null) {INSTANCE = new SimpleSingleton2();}return INSTANCE;}}
示例中的INSTANCE对象一开始是空的,在调用
getInstance方法才会真正实例化。
嗯,不错不错。但这段代码还是有问题。
假如有多个线程中都调用了getInstance方法,那么都走到if (INSTANCE == null)判断时,可能同时成立,因为INSTANCE初始化时默认值是null。这样会导致多个线程中同时创建INSTANCE对象,即INSTANCE对象被创建了多次,违背了只创建一个INSTANCE对象的初衷。
为了解决饿汉模式和懒汉模式各自的问题,于是出现了:双重检查锁。
具体代码如下:public class SimpleSingleton4 {private static SimpleSingleton4 INSTANCE;private SimpleSingleton4() {}public static SimpleSingleton4 getInstance() {if (INSTANCE == null) {synchronized (SimpleSingleton4.class) {if (INSTANCE == null) {INSTANCE = new SimpleSingleton4();}}}return INSTANCE;}}
需要在
synchronized前后两次判空。
但是:这段代码有漏洞的。
有什么问题?public static SimpleSingleton4 getInstance() {if (INSTANCE == null) {//1synchronized (SimpleSingleton4.class) {//2if (INSTANCE == null) {//3INSTANCE = new SimpleSingleton4();//4}}}return INSTANCE;//5}
getInstance方法的这段代码,是按1、2、3、4、5这种顺序写的,希望也按这个顺序执行。
但是java虚拟机实际上会做一些优化,对一些代码指令进行重排。重排之后的顺序可能就变成了:1、3、2、4、5,这样在多线程的情况下同样会创建多次实例。重排之后的代码可能如下:public static SimpleSingleton4 getInstance() {if (INSTANCE == null) {//1if (INSTANCE == null) {//3synchronized (SimpleSingleton4.class) {//2INSTANCE = new SimpleSingleton4();//4}}}return INSTANCE;//5}
原来如此,那有什么办法可以解决呢?
答:可以在定义INSTANCE是加上volatile关键字。具体代码如下:public class SimpleSingleton7 {private volatile static SimpleSingleton7 INSTANCE;private SimpleSingleton7() {}public static SimpleSingleton7 getInstance() {if (INSTANCE == null) {synchronized (SimpleSingleton7.class) {if (INSTANCE == null) {INSTANCE = new SimpleSingleton7();}}}return INSTANCE;}}
volatile关键字可以保证多个线程的可见性,但是不能保证原子性。同时它也能禁止指令重排。
双重检查锁的机制既保证了线程安全,又比直接上锁提高了执行效率,还节省了内存空间。3、
volatile的原子性从前面已经知道
volatile,是一个非常不错的关键字,它能保证变量在多个线程中的可见性,它也能禁止指令重排,但是不能保证原子性。
使用volatile关键字禁止指令重排,前面已经说过了,这里就不聊了。
可见性主要体现在:一个线程对某个变量修改了,另一个线程每次都能获取到该变量的最新值。
先一起看看反例:public class VolatileTest extends Thread {private boolean stopFlag = false;public boolean isStopFlag() {return stopFlag;}@Overridepublic void run() {try {Thread.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}stopFlag = true;System.out.println(Thread.currentThread().getName() + " stopFlag = " + stopFlag);}public static void main(String[] args) {VolatileTest vt = new VolatileTest();vt.start();while (true) {if (vt.isStopFlag()) {System.out.println("stop");break;}}}}
上面这段代码中,VolatileTest是一个Thread类的子类,它的成员变量stopFlag默认是false,在它的run方法中修改成了true。
然后在main方法的主线程中,用vt.isStopFlag()方法判断,如果它的值是true时,则打印stop关键字。
那么,如何才能让stopFlag的值修改了,在主线程中通过vt.isStopFlag()方法,能够获取最新的值呢?
正例如下:public class VolatileTest extends Thread {private volatile boolean stopFlag = false;public boolean isStopFlag() {return stopFlag;}@Overridepublic void run() {try {Thread.sleep(300);} catch (InterruptedException e) {e.printStackTrace();}stopFlag = true;System.out.println(Thread.currentThread().getName() + " stopFlag = " + stopFlag);}public static void main(String[] args) {VolatileTest vt = new VolatileTest();vt.start();while (true) {if (vt.isStopFlag()) {System.out.println("stop");break;}}}}
用
volatile关键字修饰stopFlag即可。
下面重点说说volatile的原子性问题。
使用多线程给count加1,代码如下:public class VolatileTest {public volatile int count = 0;public void add() {count++;}public static void main(String[] args) {final VolatileTest test = new VolatileTest();for (int i = 0; i < 20; i++) {new Thread() {@Overridepublic void run() {for (int j = 0; j < 1000; j++) {test.add();}};}.start();}while (Thread.activeCount() > 2) {//保证前面的线程都执行完Thread.yield();}System.out.println(test.count);}}
执行结果每次都不一样,但可以肯定的是count值每次都小于20000,比如:19999。
这个例子中count是成员变量,虽说被定义成了volatile的,但由于add方法中的count++是非原子操作。在多线程环境中,count++的数据可能会出现问题。
由此可见,volatile不能保证原子性。
那么,如何解决这个问题呢?
答:使用synchronized关键字。
改造后的代码如下:public class VolatileTest {public int count = 0;public synchronized void add() {count++;}public static void main(String[] args) {final VolatileTest test = new VolatileTest();for (int i = 0; i < 20; i++) {new Thread() {@Overridepublic void run() {for (int j = 0; j < 1000; j++) {test.add();}};}.start();}while (Thread.activeCount() > 2) {//保证前面的线程都执行完Thread.yield();}System.out.println(test.count);}}
4、死锁
死锁可能是大家都不希望遇到的问题,因为一旦程序出现了死锁,如果没有外力的作用,程序将会一直处于资源竞争的假死状态中。
死锁代码如下: ```java public class DeadLockTest {public static String OBJECT_1 = “OBJECT_1”; public static String OBJECT_2 = “OBJECT_2”;
public static void main(String[] args) {
LockA lockA = new LockA();new Thread(lockA).start();LockB lockB = new LockB();new Thread(lockB).start();
}
}
class LockA implements Runnable {
@Overridepublic void run() {synchronized (DeadLockTest.OBJECT_1) {try {Thread.sleep(500);synchronized (DeadLockTest.OBJECT_2) {System.out.println("LockA");}} catch (InterruptedException e) {e.printStackTrace();}}}
}
class LockB implements Runnable {
@Overridepublic void run() {synchronized (DeadLockTest.OBJECT_2) {try {Thread.sleep(500);synchronized (DeadLockTest.OBJECT_1) {System.out.println("LockB");}} catch (InterruptedException e) {e.printStackTrace();}}}
}
一个线程在获取OBJECT_1锁时,没有释放锁,又去申请OBJECT_2锁。而刚好此时,另一个线程获取到了OBJECT_2锁,也没有释放锁,去申请OBJECT_1锁。由于OBJECT_1和OBJECT_2锁都没有释放,两个线程将一起请求下去,陷入死循环,即出现死锁的情况。<br />那么如果避免死锁问题呢?<a name="JZz8b"></a>### 4.1 缩小锁的范围出现死锁的情况,有可能是像上面那样,锁范围太大了导致的。<br />那么解决办法就是缩小锁的范围。<br />具体代码如下:```javaclass LockA implements Runnable {@Overridepublic void run() {synchronized (DeadLockTest.OBJECT_1) {try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}synchronized (DeadLockTest.OBJECT_2) {System.out.println("LockA");}}}class LockB implements Runnable {@Overridepublic void run() {synchronized (DeadLockTest.OBJECT_2) {try {Thread.sleep(500);} catch (InterruptedException e) {e.printStackTrace();}}synchronized (DeadLockTest.OBJECT_1) {System.out.println("LockB");}}}
在获取OBJECT_1锁的代码块中,不包含获取OBJECT_2锁的代码。同时在获取OBJECT_2锁的代码块中,也不包含获取OBJECT_1锁的代码。
4.2 保证锁的顺序
出现死锁的情况说白了是,一个线程获取锁的顺序是:OBJECT_1和OBJECT_2。而另一个线程获取锁的顺序刚好相反为:OBJECT_2和OBJECT_1。
那么,如果能保证每次获取锁的顺序都相同,就不会出现死锁问题。
具体代码如下:
class LockA implements Runnable {@Overridepublic void run() {synchronized (DeadLockTest.OBJECT_1) {try {Thread.sleep(500);synchronized (DeadLockTest.OBJECT_2) {System.out.println("LockA");}} catch (InterruptedException e) {e.printStackTrace();}}}}class LockB implements Runnable {@Overridepublic void run() {synchronized (DeadLockTest.OBJECT_1) {try {Thread.sleep(500);synchronized (DeadLockTest.OBJECT_2) {System.out.println("LockB");}} catch (InterruptedException e) {e.printStackTrace();}}}}
两个线程,每个线程都是先获取OBJECT_1锁,再获取OBJECT_2锁。
5、没释放锁
在Java中除了使用synchronized关键字,给所需要的代码块加锁之外,还能通过Lock关键字加锁。
使用synchronized关键字加锁后,如果程序执行完毕,或者程序出现异常时,会自动释放锁。
但如果使用Lock关键字加锁后,需要开发人员在代码中手动释放锁。
例如:
public class LockTest {private final ReentrantLock rLock = new ReentrantLock();public void fun() {rLock.lock();try {System.out.println("fun");} finally {rLock.unlock();}}}
代码中先创建一个ReentrantLock类的实例对象rLock,调用它的lock方法加锁。然后执行业务代码,最后再finally代码块中调用unlock方法。
但如果没有在finally代码块中,调用unlock方法手动释放锁,线程持有的锁将不会得到释放。
6、HashMap导致内存溢出
HashMap在实际的工作场景中,使用频率还是挺高的,比如:接收参数,缓存数据,汇总数据等等。
但如果在多线程的环境中使用HashMap,可能会导致非常严重的后果。
@Servicepublic class HashMapService {private Map<Long, Object> hashMap = new HashMap<>();public void add(User user) {hashMap.put(user.getId(), user.getName());}}
在HashMapService类中定义了一个HashMap的成员变量,在add方法中往HashMap中添加数据。在controller层的接口中调用add方法,会使用tomcat的线程池去处理请求,就相当于在多线程的场景下调用add方法。
在jdk1.7中,HashMap使用的数据结构是:数组+链表。如果在多线程的情况下,不断往HashMap中添加数据,它会调用resize方法进行扩容。该方法在复制元素到新数组时,采用的头插法,在某些情况下,会导致链表会出现死循环。
死循环最终结果会导致:内存溢出。
此外,如果HashMap中数据非常多,会导致链表很长。当查找某个元素时,需要遍历某个链表,查询效率不太高。
为此,jdk1.8之后,将HashMap的数据结构改成了:数组+链表+红黑树。
如果同一个数组元素中的数据项小于8个,则还是用链表保存数据。如果大于8个,则自动转换成红黑树。
为什么要用红黑树?
答:链表的时间复杂度是O(n),而红黑树的时间复杂度是O(logn),红黑树的复杂度是优于链表的。
既然这样,为什么不直接使用红黑树?
答:树节点所占存储空间是链表节点的两倍,节点少的时候,尽管在时间复杂度上,红黑树比链表稍微好一些。但是由于红黑树所占空间比较大,HashMap综合考虑之后,认为节点数量少的时候用占存储空间更多的红黑树不划算。
jdk1.8中HashMap就不会出现死循环?
答:错,它在多线程环境中依然会出现死循环。在扩容的过程中,在链表转换为树的时候,for循环一直无法跳出,从而导致死循环。
那么,如果想多线程环境中使用HashMap该怎么办呢?
答:使用ConcurrentHashMap。
7、使用默认线程池
都知道jdk1.5之后,提供了ThreadPoolExecutor类,用它可以自定义线程池。
线程池的好处有很多,比如:
- 降低资源消耗:避免了频繁的创建线程和销毁线程,可以直接复用已有线程。创建线程是非常耗时的操作。
- 提供速度:任务过来之后,因为线程已存在,可以拿来直接使用。
- 提高线程的可管理性:线程是非常宝贵的资源,如果创建过多的线程,不仅会消耗系统资源,甚至会影响系统的稳定。使用线程池,可以非常方便的创建、管理和监控线程。
当然JDK为了使用更便捷,专门提供了:Executors类用来快速创建线程池。
该类中包含了很多静态方法:
newCachedThreadPool:创建一个可缓冲的线程,如果线程池大小超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。newFixedThreadPool:创建一个固定大小的线程池,如果任务数量超过线程池大小,则将多余的任务放到队列中。newScheduledThreadPool:创建一个固定大小,并且能执行定时周期任务的线程池。newSingleThreadExecutor:创建只有一个线程的线程池,保证所有的任务安装顺序执行。
在高并发的场景下,如果大家使用这些静态方法创建线程池,会有一些问题。
那么,一起看看有哪些问题?
newFixedThreadPool:允许请求的队列长度是Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。newSingleThreadExecutor:允许请求的队列长度是Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。newCachedThreadPool:允许创建的线程数是Integer.MAX_VALUE,可能会创建大量的线程,从而导致OOM。
那该怎办呢?
优先推荐使用ThreadPoolExecutor类,自定义线程池。
具体代码如下:
ExecutorService threadPool = new ThreadPoolExecutor(8, //corePoolSize线程池中核心线程数10, //maximumPoolSize 线程池中最大线程数60, //线程池中线程的最大空闲时间,超过这个时间空闲线程将被回收TimeUnit.SECONDS,//时间单位new ArrayBlockingQueue(500), //队列new ThreadPoolExecutor.CallerRunsPolicy()); //拒绝策略
顺便说一下,如果是一些低并发场景,使用Executors类创建线程池也未尝不可,也不能完全一棍子打死。在这些低并发场景下,很难出现OOM问题,所以需要根据实际业务场景选择。
8、@Async注解的陷阱
之前在Java并发编程中实现异步功能,一般是需要使用线程或者线程池。
线程池的底层也是用的线程。
而实现一个线程,要么继承Thread类,要么实现Runnable接口,然后在run方法中写具体的业务逻辑代码。
开发Spring的大神们,为了简化这类异步操作,已经把异步功能封装好了。Spring中提供了@Async注解,可以通过它即可开启异步功能,使用起来非常方便。
具体做法如下:
1.在SpringBoot的启动类上面加上@EnableAsync注解。
@EnableAsync@SpringBootApplicationpublic class Application {public static void main(String[] args) {SpringApplication.run(Application.class, args);}}
2.在需要执行异步调用的业务方法加上@Async注解。
@Servicepublic class CategoryService {@Asyncpublic void add(Category category) {//添加分类}}
3.在controller方法中调用这个业务方法。
@RestController@RequestMapping("/category")public class CategoryController {@Autowiredprivate CategoryService categoryService;@PostMapping("/add")public void add(@RequestBody category) {categoryService.add(category);}}
这样就能开启异步功能了。
是不是很easy?
但有个坏消息是:用@Async注解开启的异步功能,会调用AsyncExecutionAspectSupport类的doSubmit方法。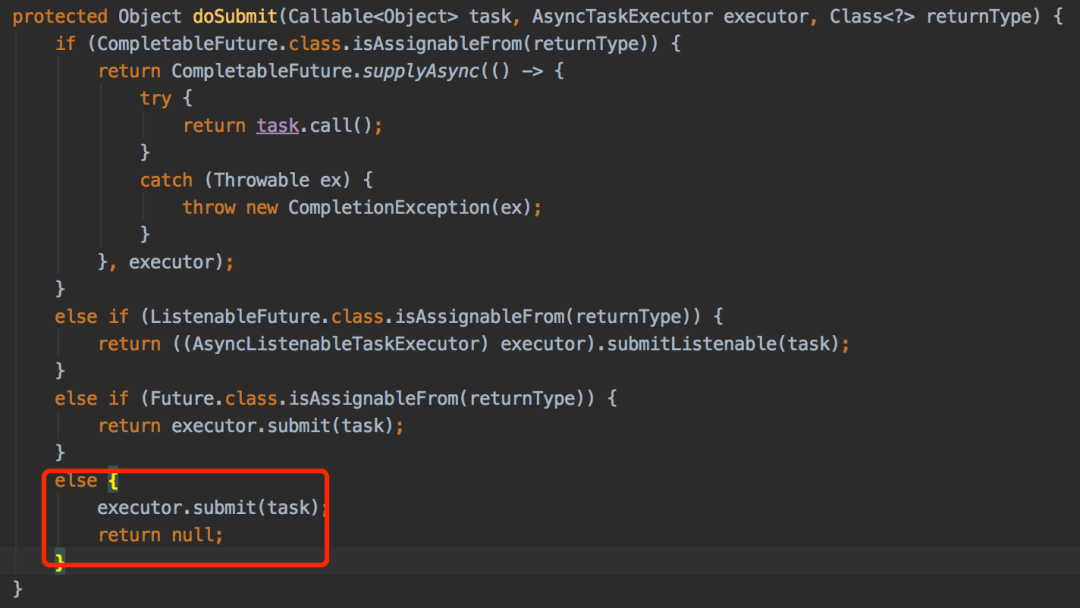 默认情况会走else逻辑。
默认情况会走else逻辑。
而else的逻辑最终会调用doExecute方法:
protected void doExecute(Runnable task) {Thread thread = (this.threadFactory != null ? this.threadFactory.newThread(task) : createThread(task));thread.start();}
这不是每次都会创建一个新线程吗?
没错,使用@Async注解开启的异步功能,默认情况下,每次都会创建一个新线程。
如果在高并发的场景下,可能会产生大量的线程,从而导致OOM问题。
建议大家在@Async注解开启的异步功能时,请别忘了定义一个线程池。
9、自旋锁浪费cpu资源
在并发编程中,自旋锁想必大家都已经耳熟能详了。
自旋锁有个非常经典的使用场景就是:CAS(即比较和交换),它是一种无锁化思想(说白了用了一个死循环),用来解决高并发场景下,更新数据的问题。
而atomic包下的很多类,比如:AtomicInteger、AtomicLong、AtomicBoolean等,都是用CAS实现的。
以AtomicInteger类为例,它的incrementAndGet没有每次都给变量加1。
public final int incrementAndGet() {return unsafe.getAndAddInt(this, valueOffset, 1) + 1;}
它的底层就是用的自旋锁实现的:
public final int getAndAddInt(Object var1, long var2, int var4) {int var5;do {var5 = this.getIntVolatile(var1, var2);} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));return var5;}
在do…while死循环中,不停进行数据的比较和交换,如果一直失败,则一直循环重试。
如果在高并发的情况下,compareAndSwapInt会很大概率失败,因此导致了此处cpu不断的自旋,这样会严重浪费cpu资源。
那么,如果解决这个问题呢?
答:使用LockSupport类的parkNanos方法。
具体代码如下:
private boolean compareAndSwapInt2(Object var1, long var2, int var4, int var5) {if(this.compareAndSwapInt(var1,var2,var4, var5)) {return true;} else {LockSupport.parkNanos(10);return false;}}
当cas失败之后,调用LockSupport类的parkNanos方法休眠一下,相当于调用了Thread.Sleep方法。这样能够有效的减少频繁自旋导致cpu资源过度浪费的问题。
10、ThreadLocal用完没清空
在Java中保证线程安全的技术有很多,可以使用synchroized、Lock等关键字给代码块加锁。
但是它们有个共同的特点,就是加锁会对代码的性能有一定的损耗。
其实,在jdk中还提供了另外一种思想即:用空间换时间。
没错,使用ThreadLocal类就是对这种思想的一种具体体现。
ThreadLocal为每个使用变量的线程提供了一个独立的变量副本,这样每一个线程都能独立地改变自己的副本,而不会影响其它线程所对应的副本。
ThreadLocal的用法大致是这样的:
先创建一个CurrentUser类,其中包含了ThreadLocal的逻辑。
public class CurrentUser {private static final ThreadLocal<UserInfo> THREA_LOCAL = new ThreadLocal();public static void set(UserInfo userInfo) {THREA_LOCAL.set(userInfo);}public static UserInfo get() {THREA_LOCAL.get();}public static void remove() {THREA_LOCAL.remove();}}
在业务代码中调用CurrentUser类。
public void doSamething(UserDto userDto) {UserInfo userInfo = convert(userDto);CurrentUser.set(userInfo);...//业务代码UserInfo userInfo = CurrentUser.get();...}
在业务代码的第一行,将userInfo对象设置到CurrentUser,这样在业务代码中,就能通过
CurrentUser.get()获取到刚刚设置的userInfo对象。特别是对业务代码调用层级比较深的情况,这种用法非常有用,可以减少很多不必要传参。
但在高并发的场景下,这段代码有问题,只往ThreadLocal存数据,数据用完之后并没有及时清理。
ThreadLocal即使使用了WeakReference(弱引用)也可能会存在内存泄露问题,因为 entry对象中只把key(即threadLocal对象)设置成了弱引用,但是value值没有。
那么,如何解决这个问题呢?public void doSamething(UserDto userDto) {UserInfo userInfo = convert(userDto);try{CurrentUser.set(userInfo);...//业务代码UserInfo userInfo = CurrentUser.get();...} finally {CurrentUser.remove();}}
需要在
finally代码块中,调用remove方法清理没用的数据。

若有收获,就点个赞吧
0 人点赞
