什么是Collector
Collector它是一个可以变化的汇聚操作,它将输入元素累积到了一个可变的结果容器中去,在全部的元素处理完之后,Collector会把累积的结果转换成一个最终的结果来表示,Collector支持串行和并行两种方式。Collector接口有三个泛型:T为输入元素的类型,A为积累结果容器的类型,R为最终生成结果的类型。
collect方法的作用
一个终端的操作,用于对流中的数据进行归集操作,collect方法接受的参数是一个Collector
有两个重载的方法,在Stream接口里。
//重载⽅法⼀<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T>accumulator, BiConsumer<R, R>combiner);//重载⽅法⼆<R, A> R collect(Collector<? super T, A, R> collector);
Collectror的作用
就是收集器,也就是一个接口,它的工具类Collectors提供链路很多工厂方法
Collectors的作用
Collectors.toList()
public static <T> Collector<T, ?, List<T>> toList() {return new CollectorImpl<>((Supplier<List<T>>)ArrayList::new, List::add,(left, right) -> {left.addAll(right); return left; }, CH_ID);}
toMap和toConcurrentMap
toMap的操作可以将输入的元素给整理成Map,Collectors提供了三种对toMap重载的方法
1.toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper):keyMapper和valueMapper分别提供结果Map的键和值
2.toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction):mergeFunction对键相同的值进行累积
3.toMap(Function<? super T, ? extends K> keyMapper, Function<? super T, ? extends U> valueMapper, BinaryOperator<U> mergeFunction, Supplier<M> mapSupplier):mapSupplier可以指定结果的Map类型
ArrayList::new(创建一个ArrayList作为累加器)
List::add(对流中的元素操作就是直接添加到累加器中)
reduce操作(对子任务归集结果addAll,后一个子任务的结果直接全部添加到前一个子任务结果中)
CH_ID(是一个unmodifiableSet集合)
Collector工作原理
Collector是通过四种方法来协同工作完成数据汇聚的操作
(1)supplier:创建新的结果容器
(2)accumulator:将输入元素合并到结果容器当中
(3)combiner:合并两个有结果的容器(并行流使用,将多个线程产生的结果容器合并)
(4)finisher:将结果容器转换成最终的表示
下面以串行为例子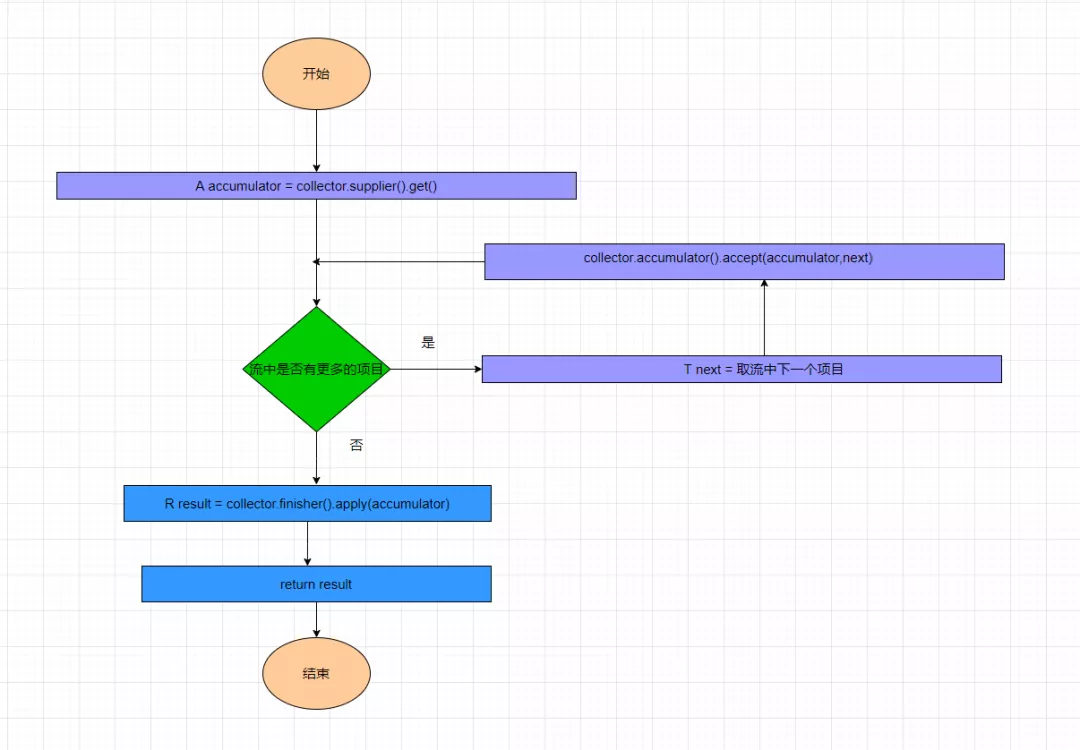
首先的话supplier会提供一个结果容器,然后accumulator就会向容器里累积元素,最后面的话finisher将结果容器转换成为最终的返回结构。如果结果容器的类型和最终返回结果的类型一致的话,那这个finisher就可以不用执行,这种行为属于可选操作。
但是combiner是和并行流有关的,这个在串行流并不会起作用。假如说并行流对元素的操作分在了三条线程完成,那么这三条线程会返回结果容器。此时此刻,combiner就可能会这样处理这三个线程的结果容器,会分别把容器进行合并,最终合并成为一个容器返回。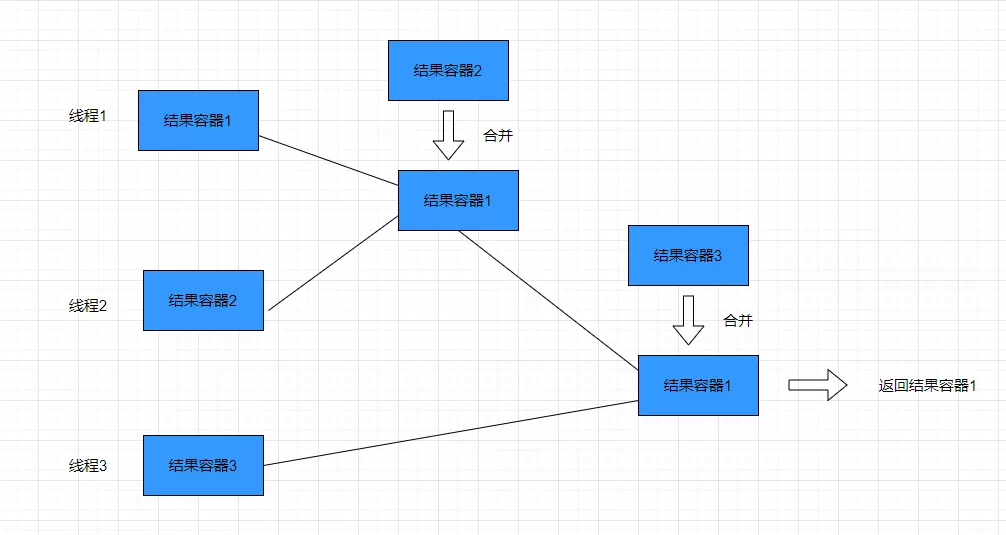
除了上面的四种Collector方法,还有一种characteristics方法,这个方法用于给Collector设置特征值。枚举常量具有三个特征值:
(1)Concurrent: 表示的结果容器只有一个(并行流也是如此)。只有在并行流且收集器不具备此特征的情况下,combiner返回的lambda表达式才会执行。设置了此特性时意味着多个线程可用堆同一个结果容器调用,因此结果容器必须是线程安全的
(2)Unordered: 表示流中的元素无序
(3)IDENTITY_FINISH:表示中间结果容器类型与最终结果类型一致。设置此特性的时候finiser方法不会被调用
收集器Joining函数
拼接函数Collectors.joining
//3种重载⽅法Collectors.joining()Collectors.joining("param")Collectors.joining("param1", "param2", "param3")
其中⼀个的实现
public static Collector<CharSequence, ?, String> joining() {return new CollectorImpl<CharSequence, StringBuilder, String>(StringBuilder::new, StringBuilder::append,(r1, r2) -> { r1.append(r2); return r1; },StringBuilder::toString, CH_NOID);}
说明:该方法可以将Stream得到一个字符串,joining函数可以接受三个参数,分别表示元素之间的连接符、前缀和后缀。
String result = Stream.of("springboot", "mysql", "html5", "css3").collect(Collectors.joining(",", "[", "]"));
收集器 partitioningBy分组
分区是分组的一种特殊情况,该操作将输入元素分为两类(即键是true和false的Map)。Collectors提供两个重载的partitioningBy()方法:partitioningBy(Predicate<? super T> predicate):predicate提供分区依据partitioningBy(Predicate<? super T> predicate,Collector<? super T, A, D> downstream):downstream提供结果Map的值。
public static <T>Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? superT> predicate) {return partitioningBy(predicate, toList());}
练习:根据list里面进行分组,字符串长度大于4的为⼀组,其他为另外⼀组
List<String> list = Arrays.asList("java", "springboot","HTML5","nodejs","CSS3");Map<Boolean, List<String>> result =list.stream().collect(partitioningBy(obj -> obj.length() > 4));
收集器 group by分组
分组 Collectors.groupingBy()
public static <T, K> Collector<T, ?, Map<K, List<T>>> groupingBy(Function<?super T, ? extends K> classifier) {return groupingBy(classifier, toList());}
练习:根据学生所在的省份,进行分组
List<Student> students = Arrays.asList(new Student("⼴东", 23), newStudent("⼴东", 24), new Student("⼴东", 23),new Student("北京", 22), newStudent("北京", 20), new Student("北京", 20),new Student("海南", 25));Map<String, List<Student>> listMap =students.stream().collect(Collectors.groupingBy(obj ->obj.getProvince()));listMap.forEach((key, value) -> {System.out.println("========");System.out.println(key);value.forEach(obj -> {System.out.println(obj.getAge());});});class Student {private String province;private int age;public String getProvince() {return province;}public void setProvince(String province) {this.province = province;}public int getAge() {return age;public void setAge(int age) {this.age = age;}public Student(String province, int age) {this.age = age;this.province = province;}}
关于性能
对于Stream所提供的几个收集器可以满足绝大部分的开发需求了,reduce提供了很多各种的自定义,但是有的时候还是需要自定义collector才能够实现。值得铭记是这个收集器是有序的,所以的话不能够并行,这个combiner方法是可以不要的,返回UnsupportedOperationException来警示此收集器的非并行性。

若有收获,就点个赞吧
0 人点赞
