队列比较
队列
队列比较
总结:
就性能而言,无锁(什么也不加) > CAS > LOCK;
从现实使用中考虑,一般选择有界队列(避免生产者速度过快,导致内存溢出);同时,为了减少Java的垃圾回收对系统性能的影响,会尽量选择array/heap格式的数据结构。所以实际使用中用ArrayBlockingQueue多一些;
注:之后会将ArrayBlockingQueue和Disruptor做一些对比。
Disruptor是什么
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
目前,包括Apache Storm、Camel、Log4j 2等在内的很多知名项目都应用了Disruptor以获取高性能。

数据来自:
https://github.com/LMAX-Exchange/disruptor/wiki/Performance-Results
Disruptor原理解析
CPU缓存

缓存层级越接近于 CPU core,容量越小,速度越快,当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。
缓存行

缓存行 (Cache Line) 是 CPU Cache 中的最小单位,CPU Cache 由若干缓存行组成,一个缓存行的大小通常是 64 字节(这取决于 CPU),并且它有效地引用主内存中的一块地址。一个 Java 的 long 类型是 8 字节,因此在一个缓存行中可以存 8 个 long 类型的变量。
CPU每次从主存中拉取数据时,会把相邻的数据也存入同一个cache line。
在访问一个long数组的时候,如果数组中的一个值被加载到缓存中,它会自动加载另外7个。因此能非常快的遍历这个数组。事实上,可以非常快速的遍历在连续内存块中分配的任意数据结构。
利用CPU缓存-示例

伪共享

如果多个线程的变量共享了同一个 CacheLine,任意一方的修改操作都会使得整个 CacheLine 失效(因为 CacheLine 是 CPU 缓存的最小单位),也就意味着,频繁的多线程操作,CPU 缓存将会彻底失效,降级为 CPU core 和主内存的直接交互。
如何解决伪共享(字节填充)


RingBuffer

在Disruptor中采用了数组的方式保存了数据,上面也介绍了采用数组保存访问时很好的利用缓存,但是在Disruptor中进一步选择采用了环形数组进行保存数据,也就是RingBuffer。在这里先说明一下环形数组并不是真正的环形数组,在RingBuffer中是采用取余的方式进行访问的,比如数组大小为 10,0访问的是数组下标为0这个位置,其实10,20等访问的也是数组的下标为0的这个位置。
当然其不仅解决了数组快速访问的问题,也解决了不需要再次分配内存的问题,减少了垃圾回收,因为0,10,20等都是执行的同一片内存区域,这样就不需要再次分配内存,频繁的被JVM垃圾回收器回收。
实际上,在这些框架中取余并不是使用%运算,都是使用的&与运算,这就要求设置的大小一般是2的N次方也就是,10,100,1000等等,这样减去1的话就是,1,11,111,就能很好的使用index & (size -1),这样利用位运算就增加了访问速度。如果在Disruptor中不用2的N次方进行大小设置,他会抛出buffersize必须为2的N次方异常。
Disruptor生产者和消费者
生产者写入数据
写入数据的步骤包括:
1.占位;
2.移动游标并填充数据;
需要考虑的问题:
1.如何避免生产者的生产速度过快而造成的新消息覆盖了未被消费的旧消息的问题;
2.如何解决多个生产者抢占生产位的问题;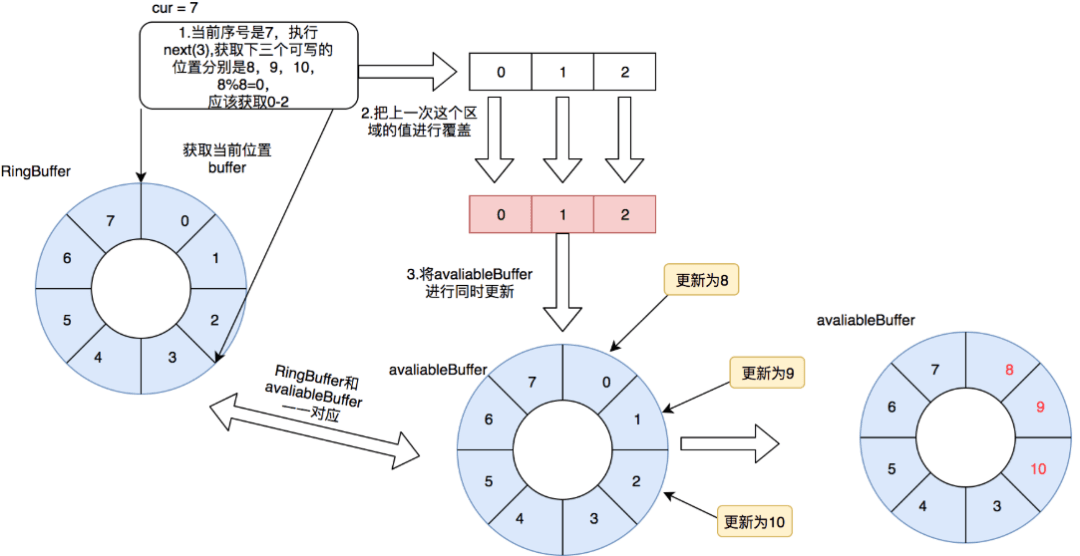
1.如何避免生产者的生产速度过快而造成的新消息覆盖了未被消费的旧消息的问题;
答:生产者再获取占位之前需要查看当前最慢的消费者位置,如果当前要发布的位置比消费者大,就等待;
2.如何解决多个生产者抢占生产位的问题;
答:多个生产者通过CAS获取生产位;
消费者读取数据

说明:
1.一个消费者一个线程;
2.每个消费者都有一个游标表示已经消费到哪了(Sequence);
3.消息者会等待(waitFor)新数据,直到生产者通知(signal);
需要考虑的问题:
如何防止读取的时候,读到还未写的元素?WaitStrategy(等待策略):BlockingWaitStrategy:默认策略,没有获取到任务的情况下线程会进入等待状态。cpu 消耗少,但是延迟高。TimeoutBlockingWaitStrategy:相对于BlockingWaitStrategy来说,设置了等待时间,超过后抛异常。BusySpinWaitStrategy:线程一直自旋等待。cpu 占用高,延迟低.YieldingWaitStrategy:尝试自旋 100 次,然后调用 Thread.yield() 让出 cpu。cpu 占用高,延迟低。SleepingWaitStrategy:尝试自旋 100 此,然后调用 Thread.yield() 100 次,如果经过这两百次的操作还未获取到任务,就会尝试阶段性挂起自身线程。此种方式是对cpu 占用和延迟的一种平衡,性能不太稳定。
生产者写入数据示例1

生产者写入数据示例2

总结
Disruptor与ArrayBlockingQueue不同的地方:
1.增加缓存行补齐, 提升cache缓存命中率, 没有为伪共享和非预期的竞争;
2. 可选锁无关lock-free, 没有竞争所以非常快;
3. 环形数组中的元素不会被删除;
4. 支持多个消费者,每个消费者都可以获得相同的消息(广播)。而ArrayBlockingQueue元素被一个消费者取走后,其它消费者就无法从Queue中取到;

若有收获,就点个赞吧
0 人点赞
