https://github.com/Ricardokevins/Bert-In-Relation-Extraction
大创所需,所以写了一个模型用来完成关系抽取
数据
数据使用的是百度发布的DUIE数据,包含了实体识别和关系抽取
我对数据进行了预处理,提取关系抽取需要的部分
关系设定有49类,还是非常的丰富的
id2rel={0: 'UNK', 1: '主演', 2: '歌手', 3: '简称', 4: '总部地点', 5: '导演',6: '出生地', 7: '目', 8: '出生日期', 9: '占地面积', 10: '上映时间',11: '出版社', 12: '作者', 13: '号', 14: '父亲', 15: '毕业院校',16: '成立日期', 17: '改编自', 18: '主持人', 19: '所属专辑',20: '连载网站', 21: '作词', 22: '作曲', 23: '创始人', 24: '丈夫',25: '妻子', 26: '朝代', 27: '民族', 28: '国籍', 29: '身高', 30: '出品公司',31: '母亲', 32: '编剧', 33: '首都', 34: '面积', 35: '祖籍', 36: '嘉宾',37: '字', 38: '海拔', 39: '注册资本', 40: '制片人', 41: '董事长', 42: '所在城市',43: '气候', 44: '人口数量', 45: '邮政编码', 46: '主角', 47: '官方语言', 48: '修业年限'}
数据的格式如下,ent1和ent2是实体,rel是关系
Model
模型就是直接使用Bert用于序列分类的(BertEncoder+Fc+CrossEntropy)
具体的处理就是把ent1,ent2和sentence直接拼接送进模型
相对我之前对Bert的粗糙处理,这里加上了MASK-Attention一起送进模型
Result
从百度的原数据中选择20000条,测试数据2000条(原数据相对很小的一部分)
训练参数:10 Epoch,0.001学习率,设置label共有49种(包含UNK,代表新关系和不存在关系)
然后在训练前和训练后的分别在测试数据上测试,可以看到Fine-Tuing高度有效
测试集正确率达到 92.5%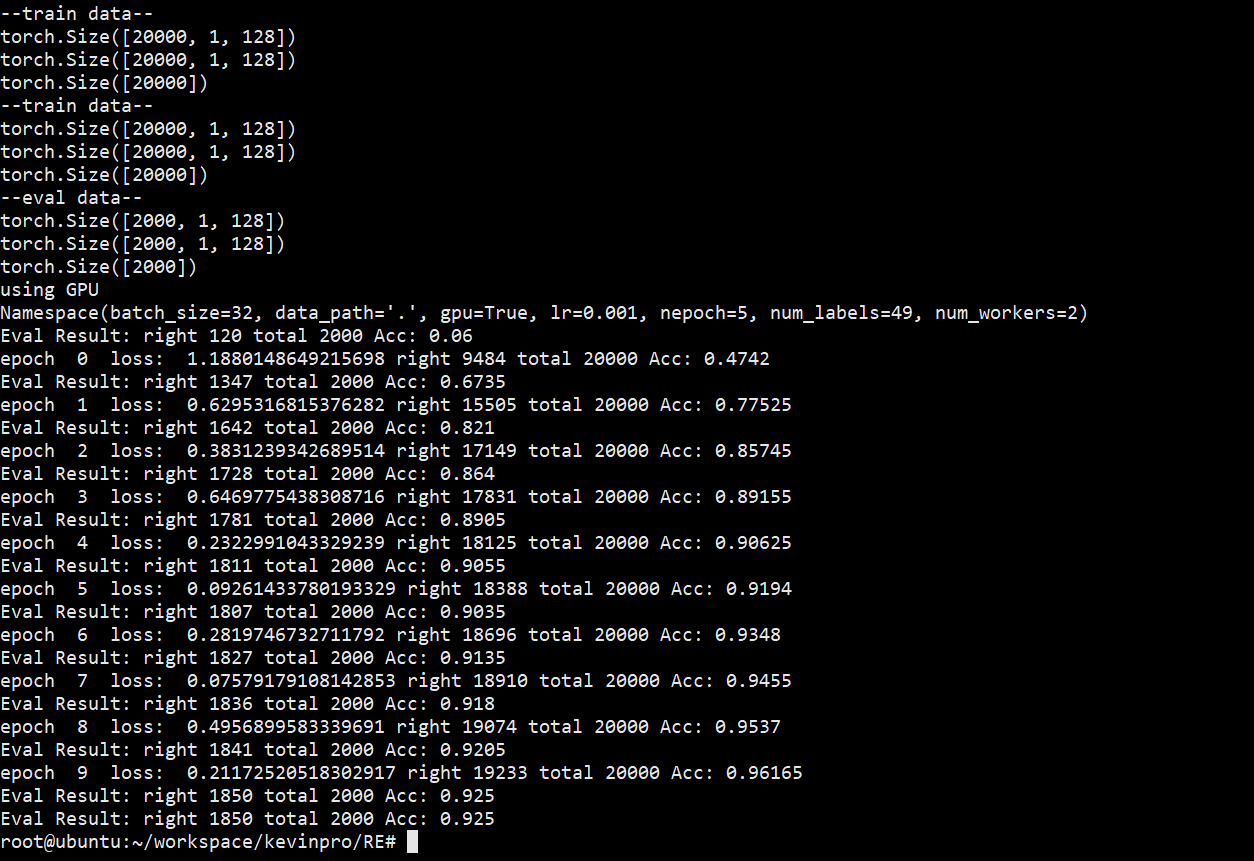
实际测试
在数据中抽取一部分实际测试
效果不错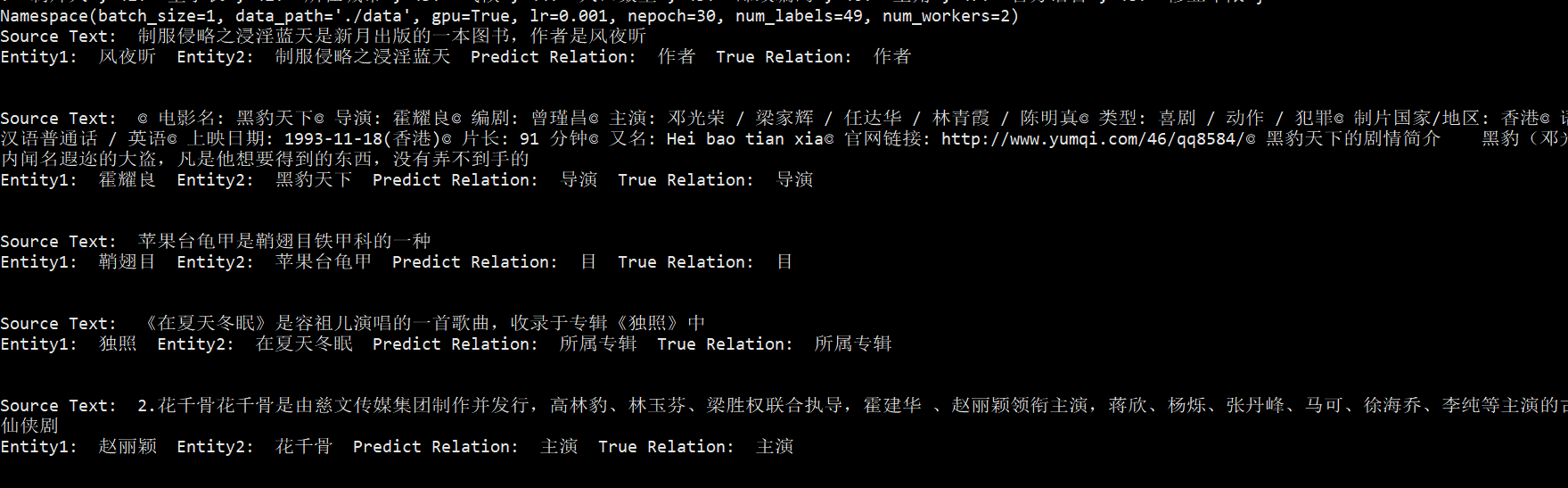


若有收获,就点个赞吧
0 人点赞
