Model
encoder
论文对文章用段落进行划分
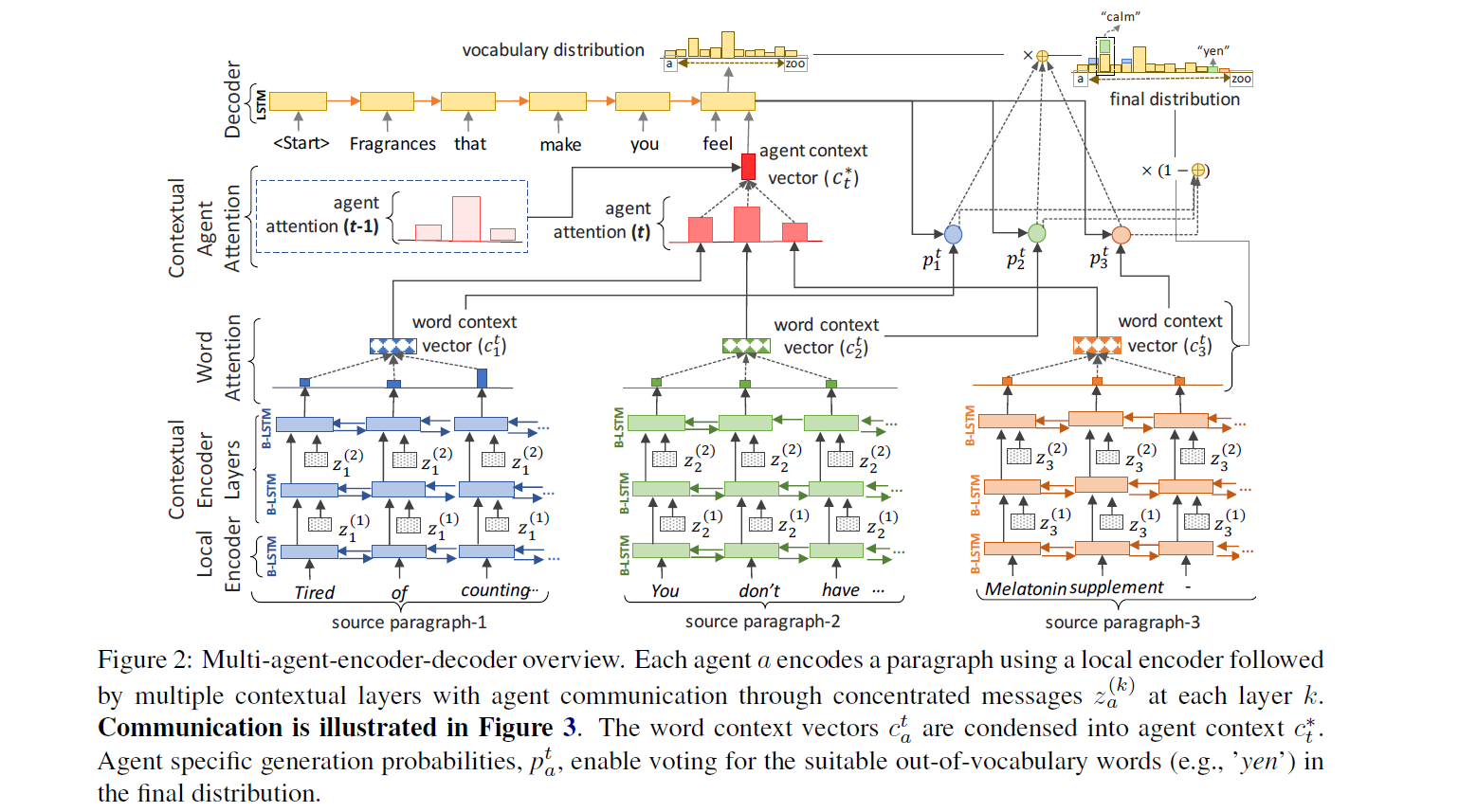
然后每一个段落用一个Agent进行提取,一个Agent是多行的LSTM模组
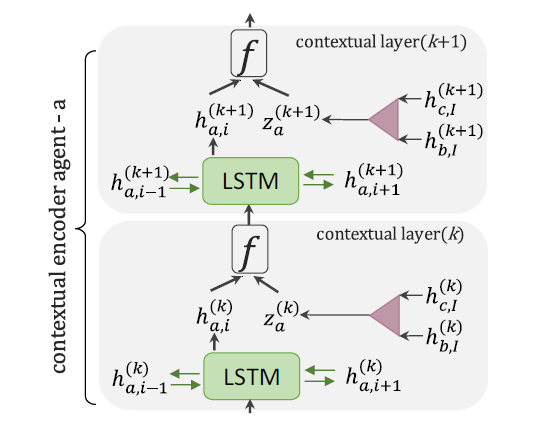
- 底层的LSTM编码单词
- 在底层的LSTM上堆叠几层的LSTM用于提取上下文信息,堆叠的上下文LSTM比较有讲究
- 接受底层传上来的
- 接受相邻BiLSTM的信息、
- 接受相邻的Agent信息(相邻段落)(对于多个Agent的最后一个token的 average pooling)
最后经过多层之后,每一个Agent,也就是每一个段落会对每一个tokens输出一个表示
截至这里encoder的工作就完成了
decoder
用decoder-state去每一个Agent内部对每一个token的表示做一个Attention,不是点积而是用线性函数
加权之后每一个Agent都会得到一个word context vector
随后和token级别Attention思路类似的Attention作用在Agent的Word Context Vector
最后汇合得到一个表示,以及decoder-state,联合计算Softmax
这里就可以对应的得到原始的Vocabulary的概率分布
这里有一个Trick,因为上述的过程可以看作是在选择decoder用哪个agent的信息,那么为了以防小的噪音导致decoder频繁的切换使用不同agent的信息,导致信息混乱,这里计算Vocabulary分布的时候加入了上一个状态的decoder-state,这样会计算权重更加稳定
最后又用了一个Multi-Agent Pointer Network,本质是Copy,让网络决定要不要复制个词到摘要里
这个我没太看懂,有点懵
Train Target
MLE
Semantic Cohesion
生成过程中,一旦生成到句号代表一句话生成的结束,用这个状态作为句子的结尾
然后相邻生成的句子之间计算相似度,希望句子之间的重复度不要太高
Reinforcement Learning Loss
强化学习方法把摘要和标注之间的ROUGE作为奖赏,然后在生成结果和贪心结果做对比作为损失,使得模型学习生成更好的摘要(比贪心策略更好的摘要)
Intermediate Rewards
每两步生成句子,之间都做一次ROUGE差值作为reward
Result
实验在CNN/DM上的结果经过了裁剪,不能直接比较
Analysis
Multi-Agent
agent的数量太多也不好,太少也不好,论文觉得3个最好
Independent vs. Communicating Agents
如果agent是独立的,多agent和单agent效果差不多,有了交互之后效果拔群
Contextual Agent Attention
这个模块有利于提取信息,同时保证decoder选择agent信息的稳定性
Repetition Penalty
强化学习方法,强化学习方法的确各方面提升ROUGE
结果
- 多个Agent的结果更好,生成的冗余少,主干全
- 多Agent分布全,对应的Attention分布均匀,用到了多处的数据,对应更高的ROUGE-L

若有收获,就点个赞吧
0 人点赞
