Summary Level Training of Sentence Rewriting for Abstractive Summarization笔记
- 强化学习方法在摘要生成上的应用
- 先前的强化学习的问题:
- 只对句子级别的打分作为激励(和MatchSum一样的思路,希望构造摘要级别打分)
- 构造了摘要级别的打分作为激励,对应的激励只有一次,但是句子抽取是一个多步的过程,怎么把最后的摘要分数这种一次性的激励作用到每一步的抽取上?
BackGround
现有的方法都还是停留在句子级别的抽取上,不管是神经网络方法还是强化学习方法
Eg。 Narayan et al. (2018)推出的方法虽然用到了摘要级别的分数,但是用高摘要分数来反作用指导句子抽取,有的句子在高分摘要中频繁出现,但是都选择可能导致冗余问题
Model
模型构造
模型分为抽取式和生成式两个方面
抽取式的模型是BERTSUM+LSTM
BERT用的是BERTSUM里的变种,也就是加上了CLS,Sentence Embedding后的BERT
然后每一次选择的句子作为初始状态送到LSTM,计算得到其余句子的权重分布,然后反复的选择
(BERTSUM的做法是直接把上述的句子向量上面叠加了Transformer,然后Sigmoid分类)
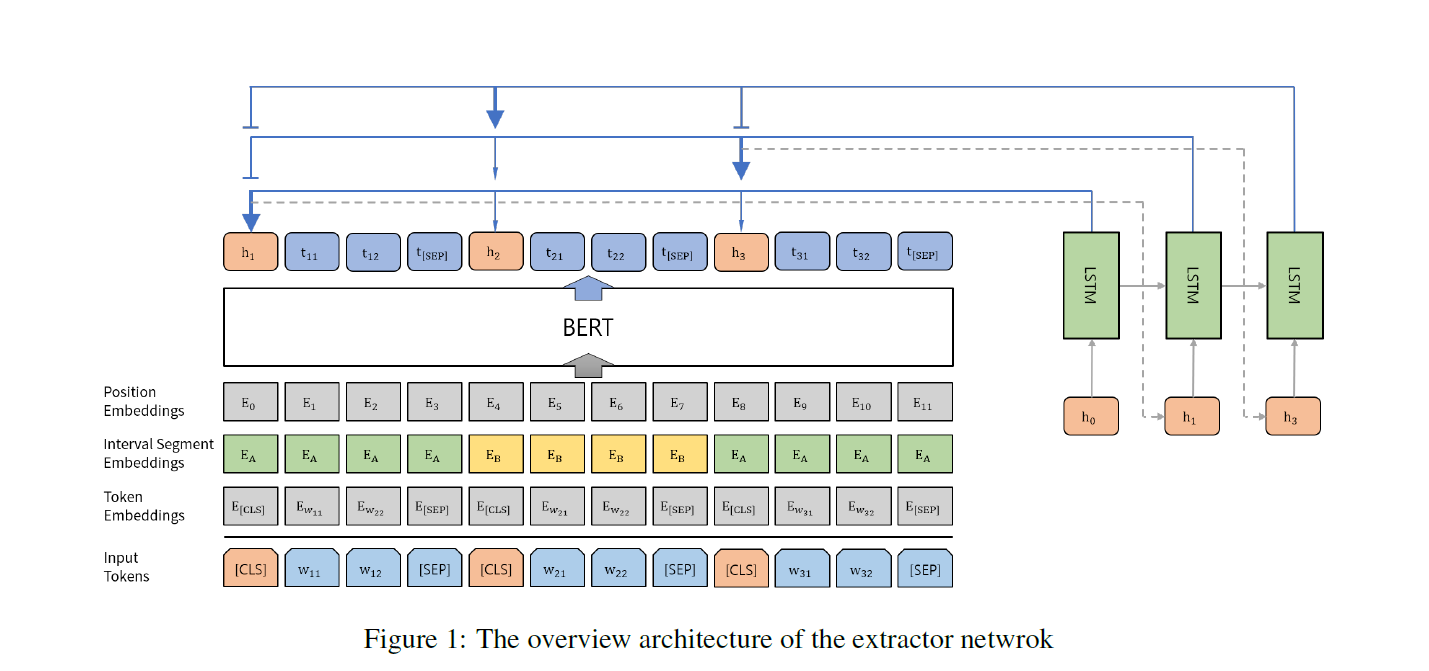
生成式部分就是一个Seq2Seq框架,负责对每一个抽取式摘要选择的句子做映射得到最后的摘要句子
对应这就有一个问题:
- 那就是抽取模型和生成模型的冲突。抽取模型不能不管后面的生成模型,生成模型原料来源于抽取框架。
- 但是如果让抽取式直接考虑生成式的生成结果,那么这个损失不直接的传导到抽取框架
This causes a weak supervision problem
这里就是使用强化学习方法来解决这个问题:
- 先用普通的Oracle和交叉熵预训练抽取式模型
- 使用强化学习方法结合生成式模型对抽取式模型做微调
训练策略
生成式模型预训练:略,就是构造Oracle,然后训练
抽取式模型训练:对每一个标注摘要的句子,找到原文里最相近的句子,构造得到了一个句子对,就可以在这个句子对上做Seq2Seq的训练
强化学习模块
- 摘要级别的reward就是最后的ROUGE Score,然后计算了每一个状态步的ROUGE Score,每一步的奖赏就是两个状态之间的差值,把当前状态到之后的状态的每一步都累加(后续的状态的分数乘上一个因子减小)。
- 加上了一个类似EOS的Stop标志,使得模型可以自己决定抽取多少句子
- 使用了强化学习里的Advantage Actor Critic方法,简单的说就是训练一个actor和criticor,一个负责做出选择,另一个对选择打分,二者相辅相成,决策者根据打分决策,打分者根据决策和决策后反馈优化打分。这一块的具体公式没有看懂
Result
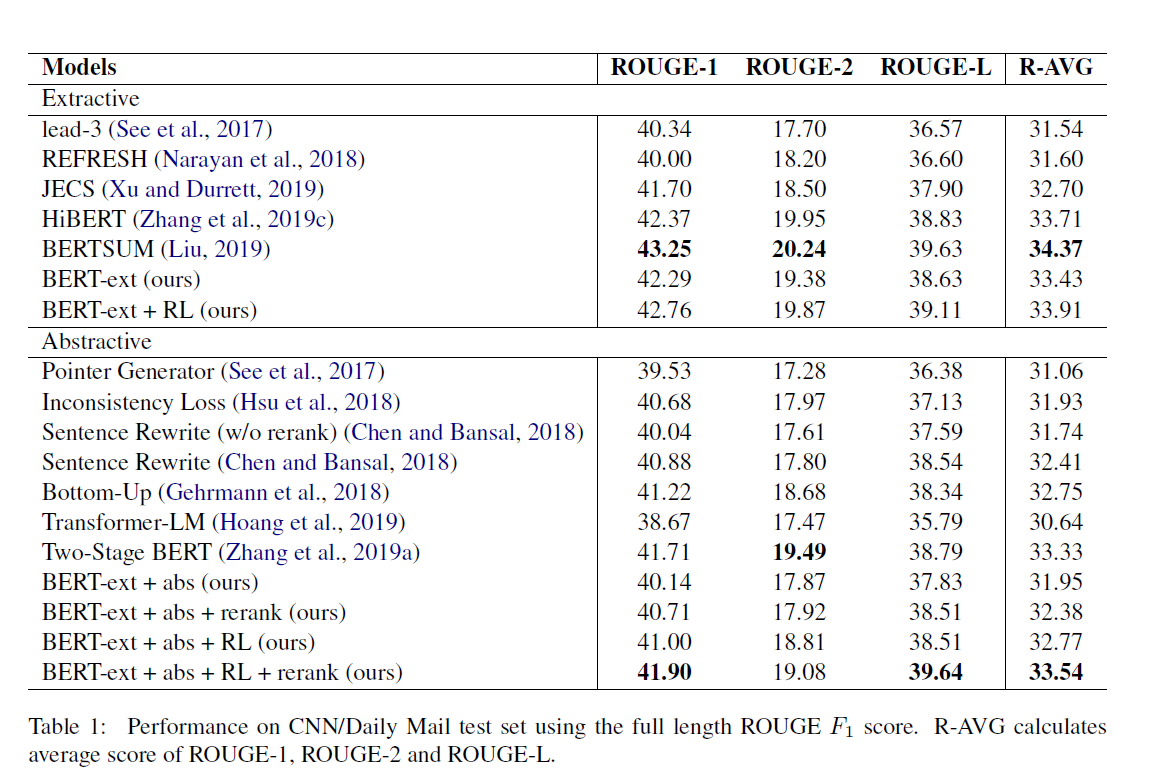
Score on Benchmark
我个人觉得这个结果其实不太理想,单纯和BERTSUM对比,BERTSUM和本论文的模型都是用了一样的BERT变种,但是这个论文加上了LSTM,BERTSUM选择堆叠Transformer,结果就很显然了,BERTSUM各项都领先
另一方面我对“抽取式加生成式改写”的方法被算作“生成式算法”,并与生成式算法对比的比较方法也存疑。
因为上述的算法是在抽取结果做了进一步的改造,理论上结果应该是好于普通的抽取式的,但是结果并不是,实际上各项指标都低于抽取式的SOTA模型,甚至不如不改写的
我对这一块的原因还存疑,或许需要看到更多的类似论文
Sentence reward VS Combination reward
后续给出了一些分析
对于Oracle构造有多种方法,一种是遍历标注摘要,对每一个标注摘要的句子找原文里ROUGE值最高,第二种是贪心,即选的句子能够使得ROUGE最快上升,第三种就是选择几个好的句子,然后排列组合找最大。
通过对这三种Oracle的构造分析,作者希望证明整体打分优于局部打分
同样的他构造了句子级别的Reward和论文用的类似于上面第三种的Reward比较
Human evaluation
最后一个比较有意思的点就是人工打分,作者使用了人工评估的方法,对CNN/DM抽取,然后给志愿者三个模型的结果,根据相关性和流畅性排名,根据排名得分最后计算
令人吃惊的就是他的模型在Benchmark上的ROUGE被BERTSUM暴打,但是在人工评估的相关性一项更好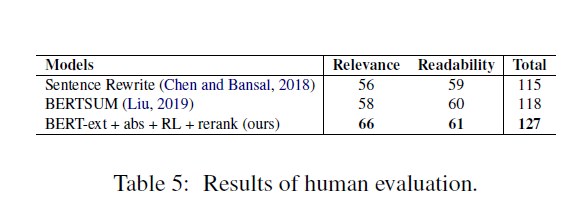

若有收获,就点个赞吧
0 人点赞
