参考于:
旧方法
之前在苏剑林的博客有看过 Flooding方法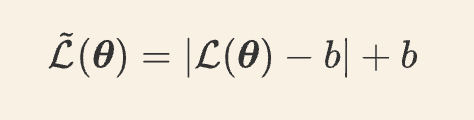
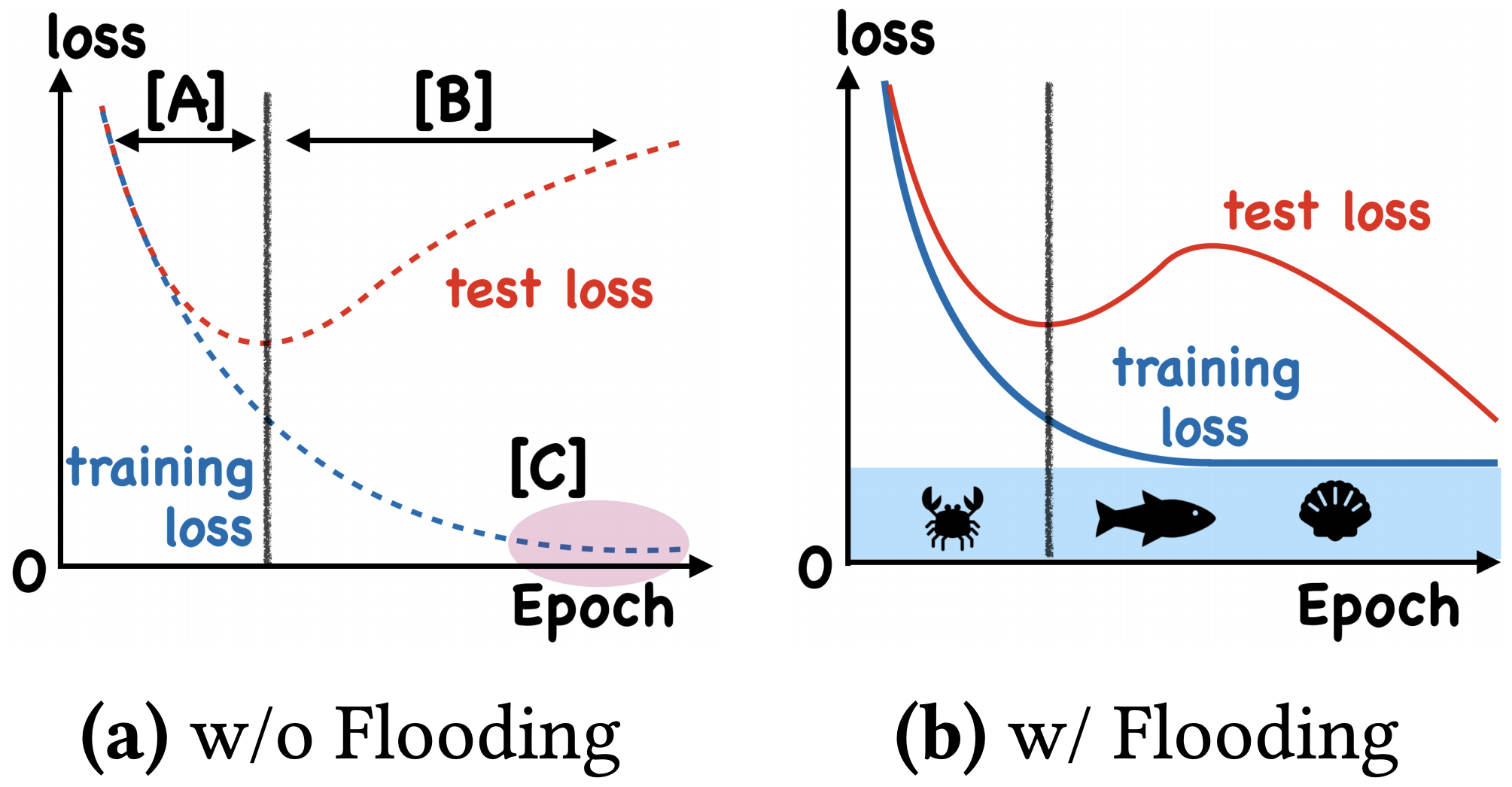
这个方法可以在训练集的损失低到了一定程度之后,不再梯度下降,而是做梯度上升
避免对训练集的过拟合,可以观察到验证集的损失进一步下降
但是问题在于这里有一个超参数B是需要实验才能够得到的
新方法
换句话来说,我们需要更加智能的去决定要不要优化当前的batch,也就是要判断当前的这个Batch的梯度是不是有用的
作者考虑两个数据,我们需要判断对X1数据的梯度更新之后,能不能有效的降低X2的损失



若有收获,就点个赞吧
0 人点赞
