在MatchSum的被引用列表里有这么一篇论文,实现了我们之前的设想,但是似乎没有取得足够好的效果
作者认为自己的亮点
- 推出了一个基于ALBERT的结构来获取优秀的句子(ALBERT 在pretrain的时候,训练目标不是NSP,而是SOP,预测关于句子的顺序,这也是作者认为这是一个改进点)
- 强调了文档级别的encoder的重要性以及获取文档级别embed的策略
模型结构
基于ALBERT的句子编码器
结构和BERTSUM一毛一样,都是魔改加上CLS和SEP,然后直接用每一个句子的CLS
这里提到的比较有意思的就是:在BERT基础上的复杂结构并没有提升甚至是退化,反而是BERTSUM那样简单的直接MLP+Sigmoid效果拔群
基于BERT的文档级别编码器
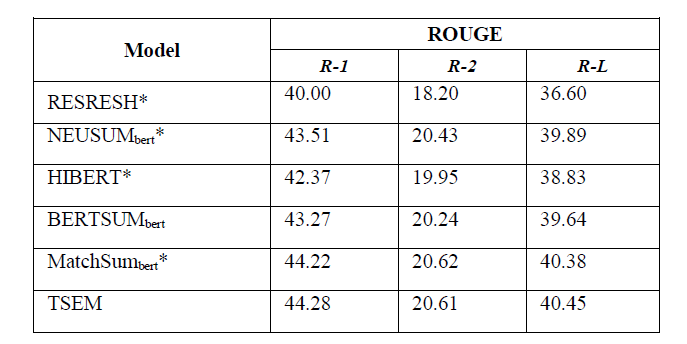
在每一个句子的后面加上SEP标识,然后用了Segment embedding
最后把整个文档的所有的token embedding 用了一个mean pooling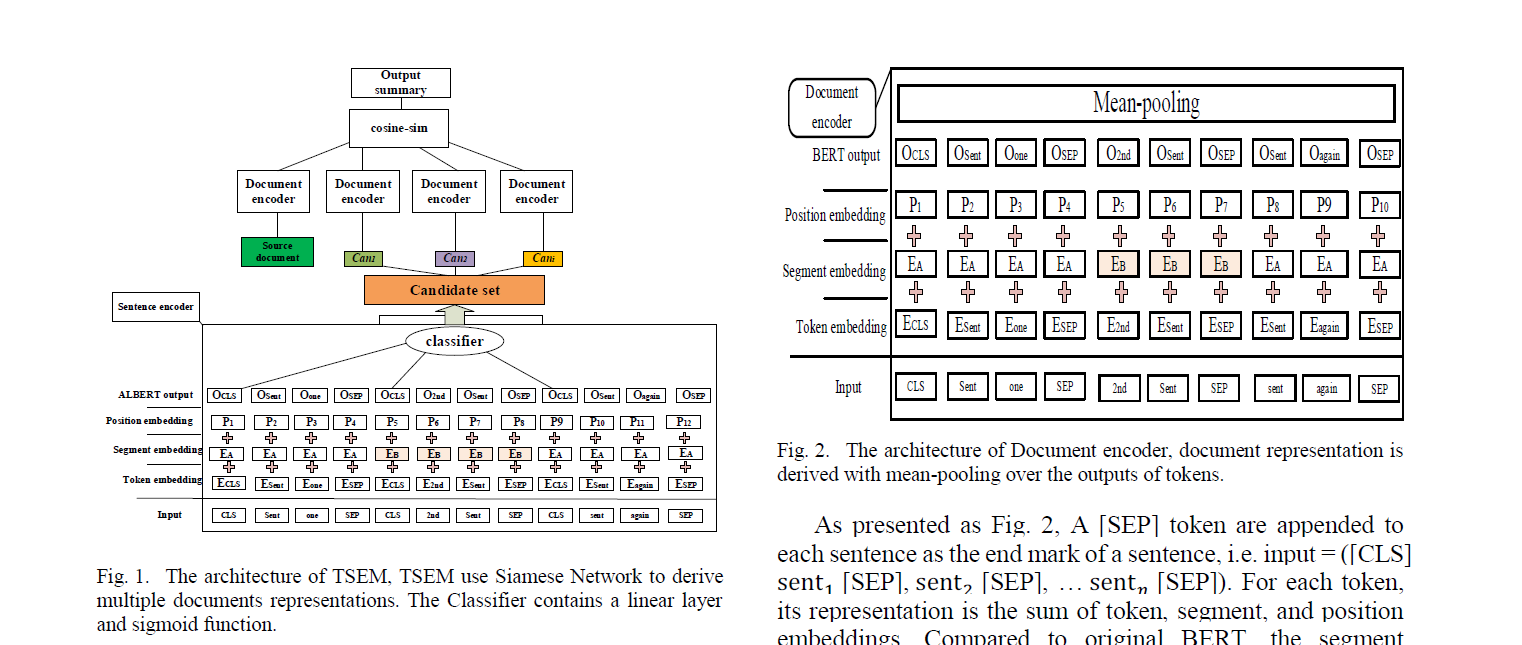
消融实验
ALBERT的有效性
没有pretrain的时候BERTSUM强于sentence encoder
但是加上了ALBERT的pretrain之后反超—->albert更好用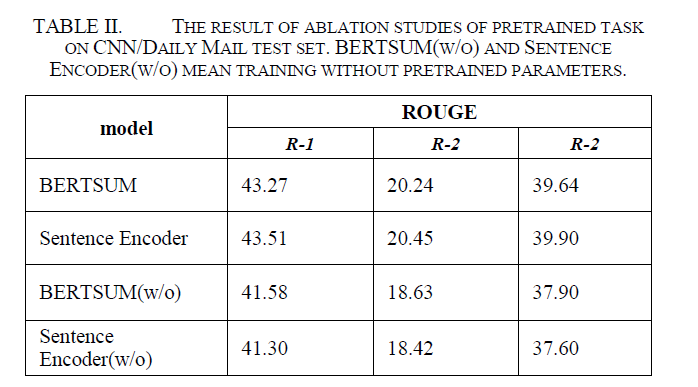
Pooling操作和segment的有效性
- mean pooling 比直接用CLS强一点
- 有segment强一点
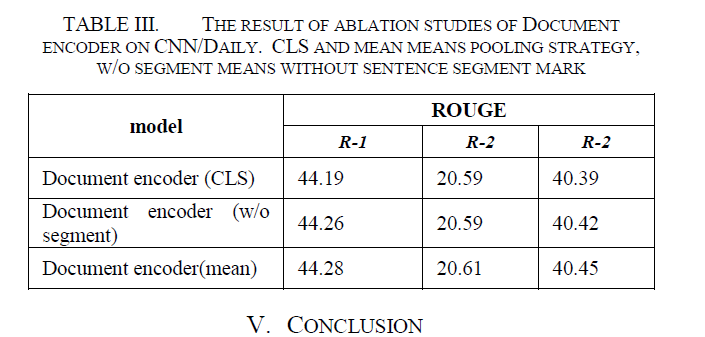
我就感觉他的实验有问题
前半部分证明了ALBERT更有效,强于BERTSUM,应该候选集更好?那什么在后面的实验里使用CLS的document encoder的结果只有44.19?MatchSum用的就是CLS,但是有44.22。
总的来看,前半部分强一点点,后半部分也强了一点,但是总的弄了半天ROUGE1和ROUGEL涨了不到0.1。。。

若有收获,就点个赞吧
0 人点赞
