这篇论文的主要贡献有三:
- 提出了更好的 Span Mask 方案,也再次展示了随机遮盖连续一段字要比随机遮盖掉分散字好;
- 通过加入 Span Boundary Objective (SBO) 训练目标,增强了 BERT 的性能,特别在一些与 Span 相关的任务,如抽取式问答;
- 用实验获得了和 XLNet 类似的结果,发现不加入 Next Sentence Prediction (NSP) 任务,直接用连续一长句训练效果更好。
根据几何分布,先随机选择一段(span)的长度,之后再根据均匀分布随机选择这一段的起始位置,最后按照长度遮盖。文中使用几何分布取 p=0.2,最大长度只能是 10,利用此方案获得平均采样长度分布。
SBO:我有个很黄很暴力的表兄 HBO
Span Boundary Objective 是该论文加入的新训练目标,希望被遮盖 Span 边界的词向量,能学习到 Span 的内容。或许作者想通过这个目标,让模型在一些需要 Span 的下游任务取得更好表现,结果表明也正如此。 具体做法是,在训练时取 Span 前后边界的两个词,值得指出,这两个词不在 Span 内,然后用这两个词向量加上 Span 中被遮盖掉词的位置向量,来预测原词。
详细做法是将词向量和位置向量拼接起来,过两层全连接层,很简单:
最后预测 Span 中原词时获得一个新损失,就是 SBO 目标的损失,之后将这个损失和 BERT 的 Mased Language Model (MLM)的损失加起来,一起用于训练模型。
加上 SBO 后效果普遍提高,特别是之前的指代消解任务,提升很大。
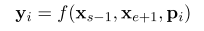
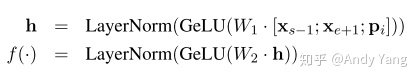
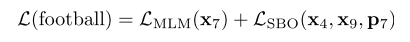

若有收获,就点个赞吧
0 人点赞
