jieba入门
最简单的词频统计(数据源是全职高手小说)
import jiebafrom collections import Counterif __name__ == "__main__":#file_path_read=input("输入待识别文本位置")file_path_read = 'D:\\New_desktop\\12.txt'try:with open(file_path_read, 'r', encoding='utf-8') as f:sentence=f.read()except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')seg1 = jieba.cut(sentence, cut_all=False)frequency = Counter()for word in seg1:if len(word)>1:frequency[word] += 1for (k, v) in frequency.most_common(100):print(k," "*int(20-len(k)),v)
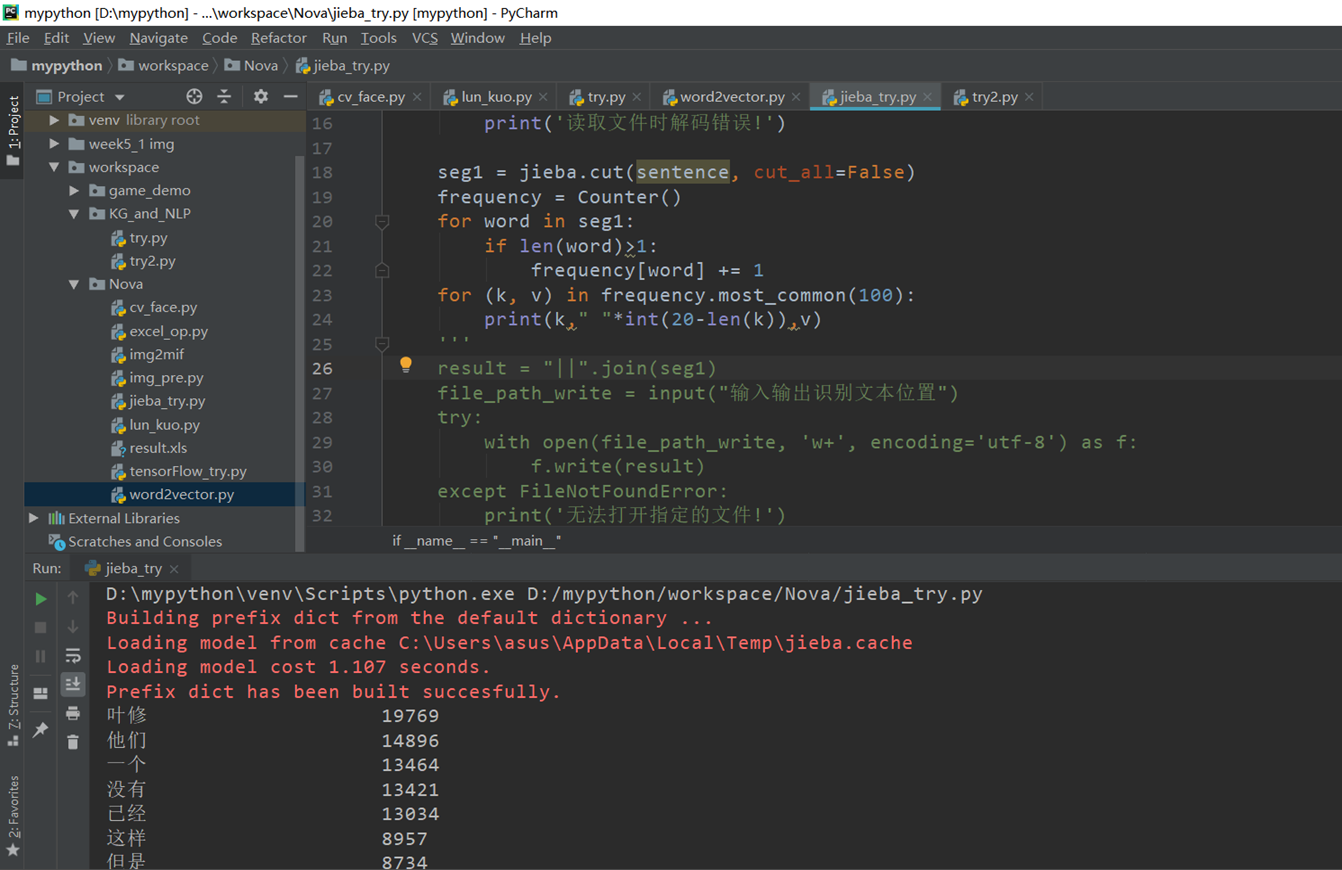
训练词向量和jieba结合
同样的训练数据源来源于全职高手
import jiebanovel = open('D:\\New_desktop\\12.txt','r',encoding='UTF-8')content=novel.read()novel_segmented = open('D:\\New_desktop\\1.txt','w')cutword = jieba.cut(content,cut_all=False)seg = ' '.join(cutword).replace(',','').replace('。','').replace('“','').replace('”','').replace(':','').replace('…','')\.replace('!','').replace('?','').replace('~','').replace('(','').replace(')','').replace('、','').replace(';','')try:with open('D:\\New_desktop\\1.txt', 'w+', encoding='utf-8') as f:f.write(seg)except FileNotFoundError:print('无法打开指定的文件!')except LookupError:print('指定了未知的编码!')except UnicodeDecodeError:print('读取文件时解码错误!')novel.close()novel_segmented.close()# 训练word2vec模型,生成词向量from gensim.models import word2vec# 训练word2vec模型,生成词向量s = word2vec.LineSentence('D:\\New_desktop\\1.txt')# 这里如果报编码错误,notepad++打开,然后转码为对应编码即可。model = word2vec.Word2Vec(s,size=200,window=5,min_count=0,workers=4)model.save('D:\\New_desktop\\3.txt')print("1 2",model.wv.similarity("叶修","苏沐橙"))print("1 3",model.wv.similarity("叶修","千机"))for i in model.most_similar(u"叶修",topn=20):print (i[0],i[1])
seg1 = jieba.cut(sentence, cut_all=False)print(type(seg1))print(seg1)seg = ' '.join(seg1).replace(',', '').replace('。', '').replace('“', '').replace('”', '').replace(':', '').replace('…', '') \.replace('!', '').replace('?', '').replace('~', '').replace('(', '').replace(')', '').replace('、', '').replace(';', '').replace(',',' ')
利用正则表达式去除不必要的标点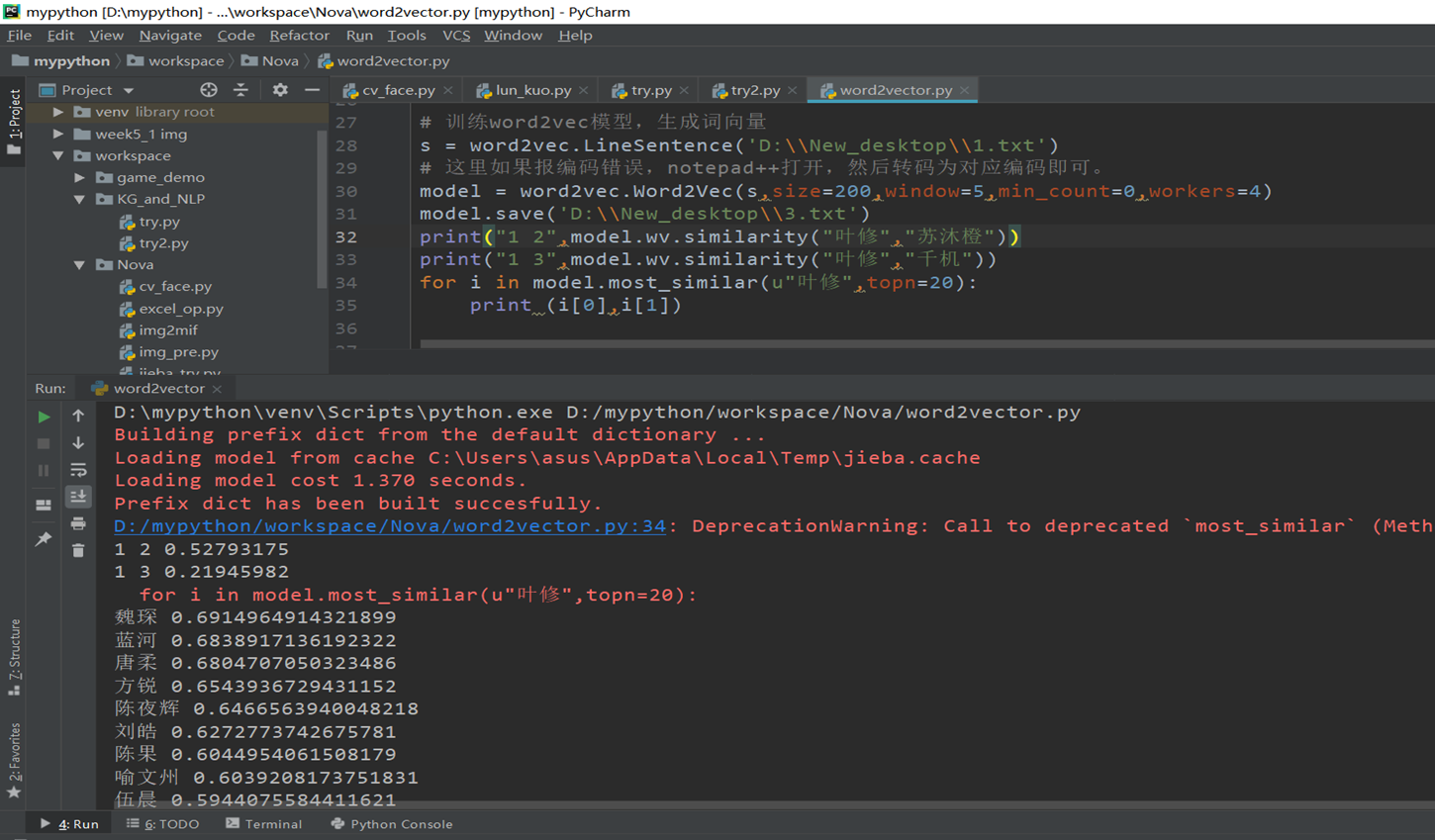
jieba关键词抽取
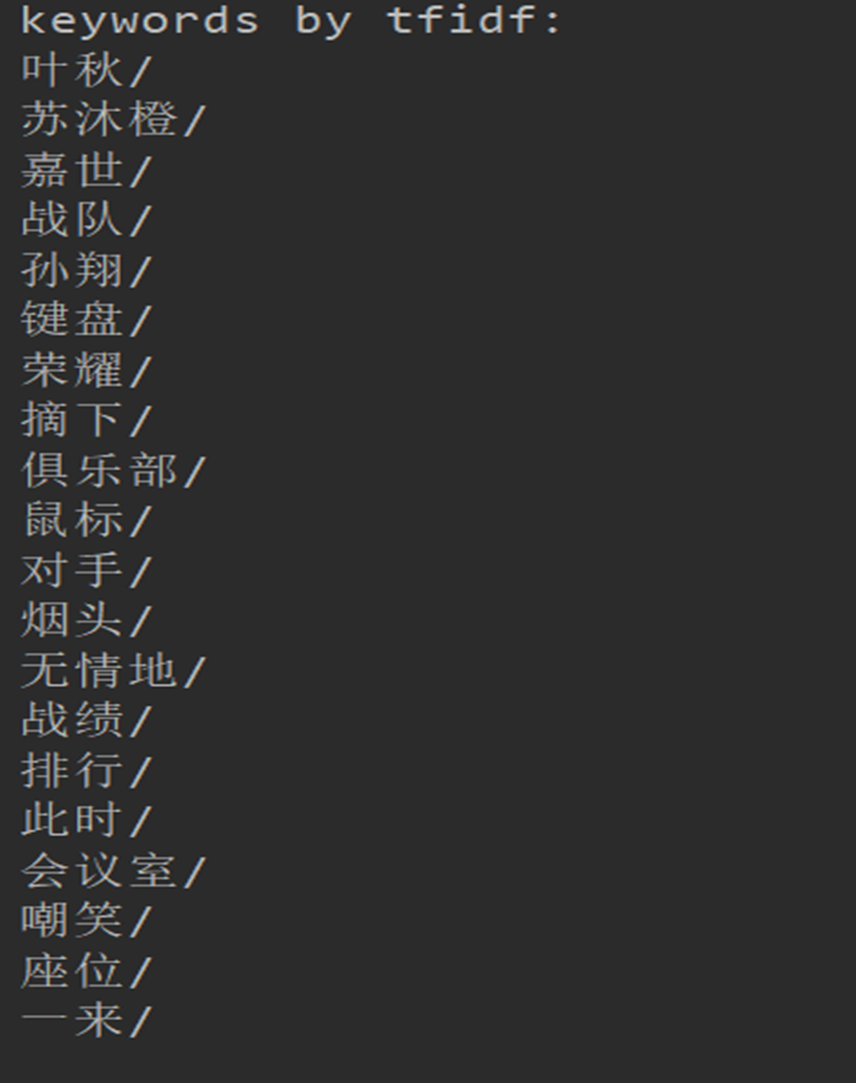
先前是使用全本的全职高手进行数据分析,字太多了。。。之前还行,在这个环节就不行了,运行了很久,所以随机抽取了一段进行分析测试,感觉第一个算法的结果和算法性能都更好一些
from jieba import analyse# 引入TF-IDF关键词抽取接口tfidf = analyse.extract_tagstextrank = analyse.textrankfilename = "D:\\New_desktop\\123.txt"# 基于TF-IDF算法进行关键词抽取content = open(filename, 'rb').read()keywords = tfidf(content)print ("keywords by tfidf:")# 输出抽取出的关键词for keyword in keywords:print (keyword + "/")print ("\nkeywords by textrank:")# 基于TextRank算法进行关键词抽取keywords = textrank(content)# 输出抽取出的关键词for keyword in keywords:print (keyword)print("end")
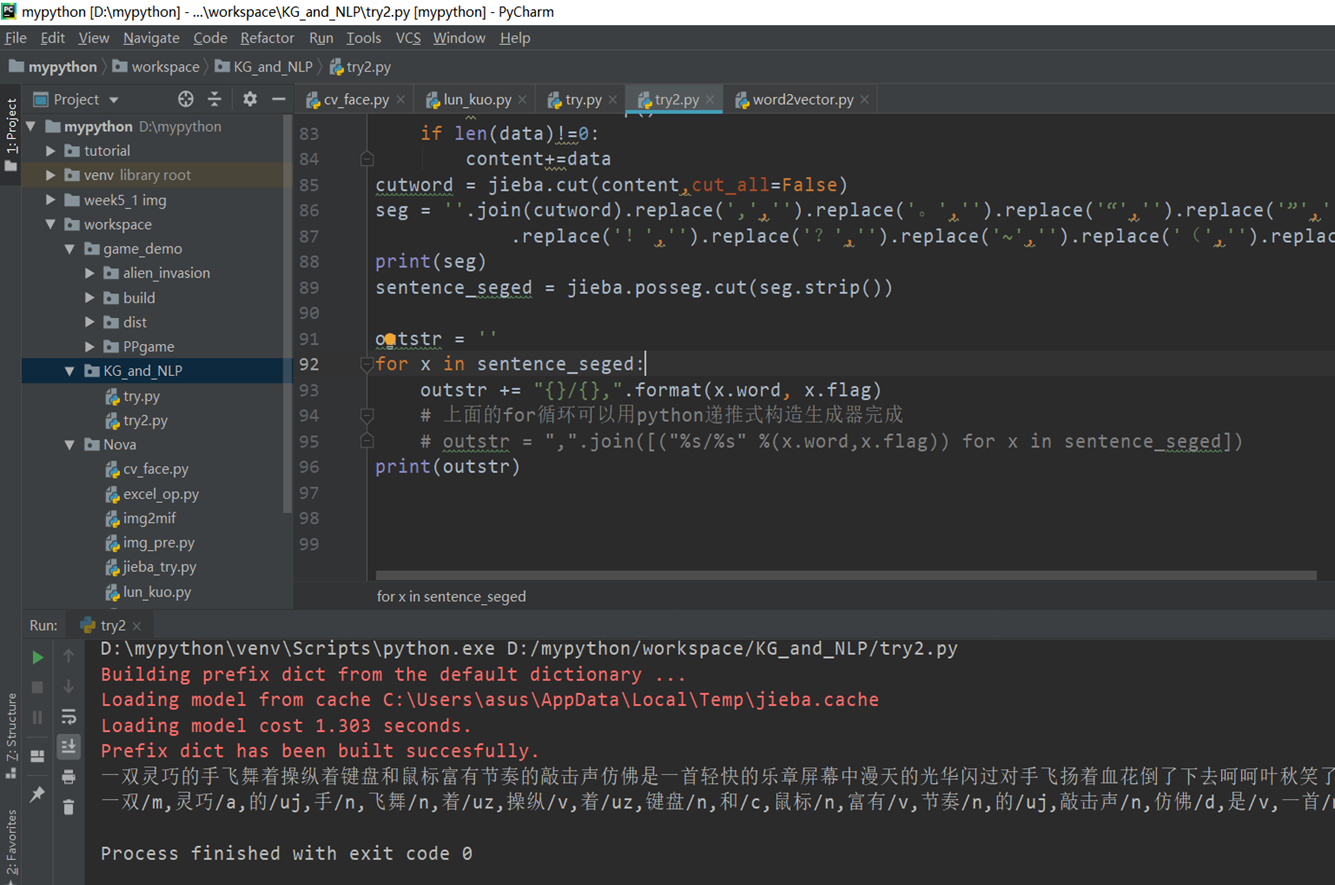
标注词性
import jiebaimport jieba.analyseimport jieba.posseg'''带词性标注,对句子进行分词,不排除停词等:param sentence:输入字符:return:'''filename = "D:\\New_desktop\\123.txt"f = open(filename,"r",encoding='utf-8')result = list()for line in f.readlines():line = line.strip()if not len(line):continueresult.append(line)f.closecontent=""for sentence in result:sentence.encode('utf-8')data=sentence.strip()if len(data)!=0:content+=datacutword = jieba.cut(content,cut_all=False)seg = ''.join(cutword).replace(',','').replace('。','').replace('“','').replace('”','').replace(':','').replace('…','')\.replace('!','').replace('?','').replace('~','').replace('(','').replace(')','').replace('、','').replace(';','').replace(',','')print(seg)sentence_seged = jieba.posseg.cut(seg.strip())outstr = ''for x in sentence_seged:outstr += "{}/{},".format(x.word, x.flag)# 上面的for循环可以用python递推式构造生成器完成# outstr = ",".join([("%s/%s" %(x.word,x.flag)) for x in sentence_seged])print(outstr)
jieba并行计算提高速度
看教程看到的,没用过
import sysimport timesys.path.append("../../")import jiebajieba.enable_parallel()url = sys.argv[1]content = open(url,"rb").read()t1 = time.time()words = "/ ".join(jieba.cut(content))t2 = time.time()tm_cost = t2-t1log_f = open("1.log","wb")log_f.write(words.encode('utf-8'))print('speed %s bytes/second' % (len(content)/tm_cost))
chineseanlyse
没看懂在干嘛,但还是存下来了
from __future__ import unicode_literalsimport sys,ossys.path.append("../")from whoosh.index import create_in,open_dirfrom whoosh.fields import *from whoosh.qparser import QueryParserfrom jieba.analyse.analyzer import ChineseAnalyzeranalyzer = ChineseAnalyzer()schema = Schema(title=TEXT(stored=True), path=ID(stored=True), content=TEXT(stored=True, analyzer=analyzer))if not os.path.exists("tmp"):os.mkdir("tmp")ix = create_in("tmp", schema) # for create new index#ix = open_dir("tmp") # for read onlywriter = ix.writer()writer.add_document(title="document1",path="/a",content="This is the first document we’ve added!")writer.add_document(title="document2",path="/b",content="The second one 你 中文测试中文 is even more interesting! 吃水果")writer.add_document(title="document3",path="/c",content="买水果然后来世博园。")writer.add_document(title="document4",path="/c",content="工信处女干事每月经过下属科室都要亲口交代24口交换机等技术性器件的安装工作")writer.add_document(title="document4",path="/c",content="咱俩交换一下吧。")writer.commit()searcher = ix.searcher()parser = QueryParser("content", schema=ix.schema)for keyword in ("水果世博园","你","first","中文","交换机","交换"):print("result of ",keyword)q = parser.parse(keyword)results = searcher.search(q)for hit in results:print(hit.highlights("content"))print("="*10)for t in analyzer("我的好朋友是李明;我爱北京天安门;IBM和Microsoft; I have a dream. this is intetesting and interested me a lot"):print(t.text)
简单注明
- Jieba的cut函数的返回结果是一个generator,所以是使用join进行链接之后才能够使用正则表达式等等的对于字符串进行处理的操作,可以考虑直接使用lcut生成一个列表
- 附上jieba词性表 | 词性 | 类型 | 说明 | | —- | —- | —- | | Ag | 形语素 | 形容词性语素。形容词代码为 a,语素代码g前面置以A。 | | a | 形容词 | 取英语形容词 adjective的第1个字母。 | | ad | 副形词 | 直接作状语的形容词。形容词代码 a和副词代码d并在一起。 | | an | 名形词 | 具有名词功能的形容词。形容词代码 a和名词代码n并在一起。 | | b | 区别词 | 取汉字“别”的声母。 | | c | 连词 | 取英语连词 conjunction的第1个字母。 | | dg | 副语素 | 副词性语素。副词代码为 d,语素代码g前面置以D。 | | d | 副词 | 取 adverb的第2个字母,因其第1个字母已用于形容词。 | | e | 叹词 | 取英语叹词 exclamation的第1个字母。 | | f | 方位词 | 取汉字“方” | | g | 语素 | 绝大多数语素都能作为合成词的“词根”,取汉字“根”的声母。 | | h | 前接成分 | 取英语 head的第1个字母。 | | i | 成语 | 取英语成语 idiom的第1个字母。 | | j | 简称略语 | 取汉字“简”的声母。 | | k | 后接成分 | | | l | 习用语 | 习用语尚未成为成语,有点“临时性”,取“临”的声母。 | | m | 数词 | 取英语 numeral的第3个字母,n,u已有他用。 | | Ng | 名语素 | 名词性语素。名词代码为 n,语素代码g前面置以N。 | | n | 名词 | 取英语名词 noun的第1个字母。 | | nr | 人名 | 名词代码 n和“人(ren)”的声母并在一起。 | | ns | 地名 | 名词代码 n和处所词代码s并在一起。 | | nt | 机构团体 | “团”的声母为 t,名词代码n和t并在一起。 | | nz | 其他专名 | “专”的声母的第 1个字母为z,名词代码n和z并在一起。 | | o | 拟声词 | 取英语拟声词 onomatopoeia的第1个字母。 | | p | 介词 | 取英语介词 prepositional的第1个字母。 | | q | 量词 | 取英语 quantity的第1个字母。 | | r | 代词 | 取英语代词 pronoun的第2个字母,因p已用于介词。 | | s | 处所词 | 取英语 space的第1个字母。 | | tg | 时语素 | 时间词性语素。时间词代码为 t,在语素的代码g前面置以T。 | | t | 时间词 | 取英语 time的第1个字母。 | | u | 助词 | 取英语助词 auxiliary | | vg | 动语素 | 动词性语素。动词代码为 v。在语素的代码g前面置以V。 | | v | 动词 | 取英语动词 verb的第一个字母。 | | vd | 副动词 | 直接作状语的动词。动词和副词的代码并在一起。 | | vn | 名动词 | 指具有名词功能的动词。动词和名词的代码并在一起。 | | w | 标点符号 | | | x | 非语素字 | 非语素字只是一个符号,字母 x通常用于代表未知数、符号。 | | y | 语气词 | 取汉字“语”的声母。 | | z | 状态词 | 取汉字“状”的声母的前一个字母。 | | un | 未知词 | 不可识别词及用户自定义词组。取英文Unkonwn首两个字母。(非北大标准,CSW分词中定义) |

若有收获,就点个赞吧
0 人点赞
