比赛题
https://www.kaggle.com/c/nlp-getting-started
简单的说就是句子的二分类问题
基本思路
- 建立词典
- 输入句子序列(编号)
- 输入到embeding
- embeding再输入LSTM
- LSTM输入到Linear
- 最后利用输出的数和1,0计算损失
- 使用torch.nn.MSELoss()计算loss
- 优化算法optim.SGD(model.parameters(), lr=learning_rate)
总的架构:Embedding+LSTM+Linear
代码
import pandas as pdimport numpy as npfrom sklearn.preprocessing import MinMaxScalerimport timeimport copyimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.autograd as autogradimport torch.nn.functionalfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsimport warningsimport torchimport timeUSE_CUDA = torch.cuda.is_available()base_path="D:\\New_desktop\\nlp-getting-started\\"read_train=pd.read_csv(base_path+'train.csv')train_data=read_train.iloc[0:read_train.shape[0],[1,2,3]]train_label=read_train.iloc[0:read_train.shape[0],[4]]train_label=torch.tensor(train_label[:read_train.shape[0]].values,dtype=torch.float)read_test = pd.read_csv(base_path + 'test.csv')test_data = read_test.iloc[0:read_train.shape[0], [1, 2, 3]]a=[]sentence=""for i in range(0, len(train_data)):sentence=sentence+str(train_data.iloc[i]['keyword'])sentence+=" "sentence=sentence+str(train_data.iloc[i]['location'])sentence += " "sentence=sentence+str(train_data.iloc[i]['text'])sentence += " "for i in range(0, len(test_data)):sentence=sentence+str(test_data.iloc[i]['keyword'])sentence+=" "sentence=sentence+str(test_data.iloc[i]['location'])sentence += " "sentence=sentence+str(test_data.iloc[i]['text'])sentence += " "dict = sentence.split()dict=set(dict)print(len(dict))w2i={}def word2index():index=0for i in dict:w2i[i]=indexindex+=1word2index()train_data['keyword'] = [[w2i[i] for i in str(x).split()] for x in train_data.keyword]train_data['location'] = [[w2i[i] for i in str(x).split()] for x in train_data.location]train_data['text'] = [[w2i[i] for i in str(x).split()] for x in train_data.text]#print(train_data[:read_train.shape[0]])test_data['keyword'] = [[w2i[i] for i in str(x).split()] for x in test_data.keyword]test_data['location'] = [[w2i[i] for i in str(x).split()] for x in test_data.location]test_data['text'] = [[w2i[i] for i in str(x).split()] for x in test_data.text]data_list=[]max_len=0for i in range(0, len(train_data)):if len(train_data.iloc[i]['text'])>max_len:max_len=len(train_data.iloc[i]['text'])print(max_len)for x in train_data.text:while len(x)<max_len:x.append(0)for i in range(0, len(train_data)):data_list.append(train_data.iloc[i]['text'])#print(len(data_list))traindata_tensor = torch.Tensor(data_list)if USE_CUDA:print("using GPU")traindata_tensor =traindata_tensor.cuda()train_label = train_label.cuda()#print(a.shape)#train_data=torch.tensor(train_data[:read_train.shape[0]].values,dtype=torch.float)#print(train_data)#print (len(train_data.iloc[0]))'''输入数据格式:input(seq_len, batch, input_size)h0(num_layers * num_directions, batch, hidden_size)c0(num_layers * num_directions, batch, hidden_size)输出数据格式:output(seq_len, batch, hidden_size * num_directions)hn(num_layers * num_directions, batch, hidden_size)cn(num_layers * num_directions, batch, hidden_size)'''class LSTMTagger(nn.Module):def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size,batch_size,str_len):super(LSTMTagger, self).__init__()self.hidden_dim = hidden_dimself.str_len=str_lenself.batch_size=batch_sizeself.word_embeddings = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim)self.hidden2tag = nn.Linear(str_len*hidden_dim, tagset_size)self.hidden = self.init_hidden()def init_hidden(self):return (torch.zeros(1, self.batch_size, self.hidden_dim).cuda(),torch.zeros(1, self.batch_size, self.hidden_dim).cuda())def forward(self, sentence,state):embeds = self.word_embeddings(sentence)#print(embeds.shape)self.hidden=statelstm_out, self.hidden = self.lstm(embeds.view(self.str_len, len(sentence), -1), self.hidden)#print("ls",lstm_out.shape)tag_space = self.hidden2tag(lstm_out.view(self.batch_size,-1))#print(tag_space.shape)self.dropout = nn.Dropout(config.hidden_dropout_prob)#tag_scores = F.log_softmax(tag_space,dim=1)return tag_space ,self.hiddenmodel = LSTMTagger(10, 100, len(dict),1,16,31)model=model.cuda()def train(net, train_data, train_label,num_epochs, learning_rate, batch_size):train_ls=[]#loss =torch.nn.CrossEntropyLoss()state=Noneloss = torch.nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=learning_rate)dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)iter=0for epoch in range(num_epochs):correct = 0total=0start = time.time()index=0for X, y in train_iter:iter+=1index+=1if index>=470:breakif state is not None:if isinstance (state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()X = X.long()(output, state) = model(X, state)#correct+=predicted.data.eq(label.data).cpu().sum()l = loss(output.float(), y)l.backward()optimizer.step()optimizer.zero_grad()#print(output)output = [1 if i > 0.5 else 0 for i in output]for i in range(len(output)):total+=1if output[i]==y[i]:correct+=1acc = correct / totalend = time.time()print("epoch ", str(epoch), "time: ",end-start ," loss: ", l.item())print("correct: ", correct, " total: ", total, "acc: ", acc)print("\n")train_ls.append(l.item())return train_ls#torch.save(model_object, 'model.pkl')#model = torch.load('model.pkl')def out_put(model):test_list = []max_len = 31for x in test_data.text:while len(x) < max_len:x.append(0)if len(x)>max_len:x =x[0:30]test_num=len(test_data.text)print("sda",test_num)for i in range(0, len(test_data)):data_list.append(test_data.iloc[i]['text'])test_data_tensor = torch.Tensor(data_list)if USE_CUDA:print("using GPU")test_data_tensor = test_data_tensor.cuda()with torch.no_grad():result_dataset = torch.utils.data.TensorDataset(test_data_tensor)result_dataloader = torch.utils.data.DataLoader(result_dataset, batch_size=16, shuffle=False)state=Noneindex=0for X in result_dataloader:X=X[0]if index>=203:breakindex+=1print(X.shape)if state is not None:if isinstance(state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()X = X.long()(output, state) = model(X, state)# correct+=predicted.data.eq(label.data).cpu().sum()output = [1 if i > 0.5 else 0 for i in output]for i in range(len(output)):test_list.append(output[i])print(test_list)print(len(test_list))while len(test_list)<3263:test_list.append(0)df_output = pd.DataFrame()aux = pd.read_csv(base_path + 'test.csv')df_output['id'] = aux['id']df_output['target'] = test_listdf_output[['id', 'target']].to_csv(base_path + 's1mple.csv', index=False)train(model,traindata_tensor,train_label,250,0.1,16)out_put(model)
结果
本地训练集
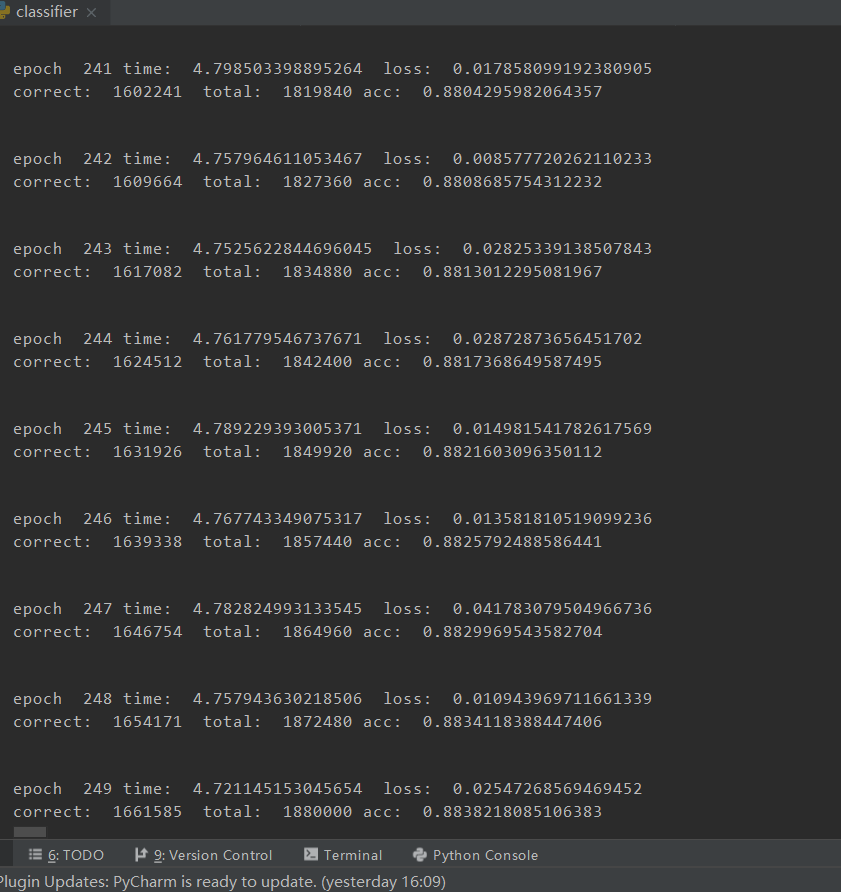
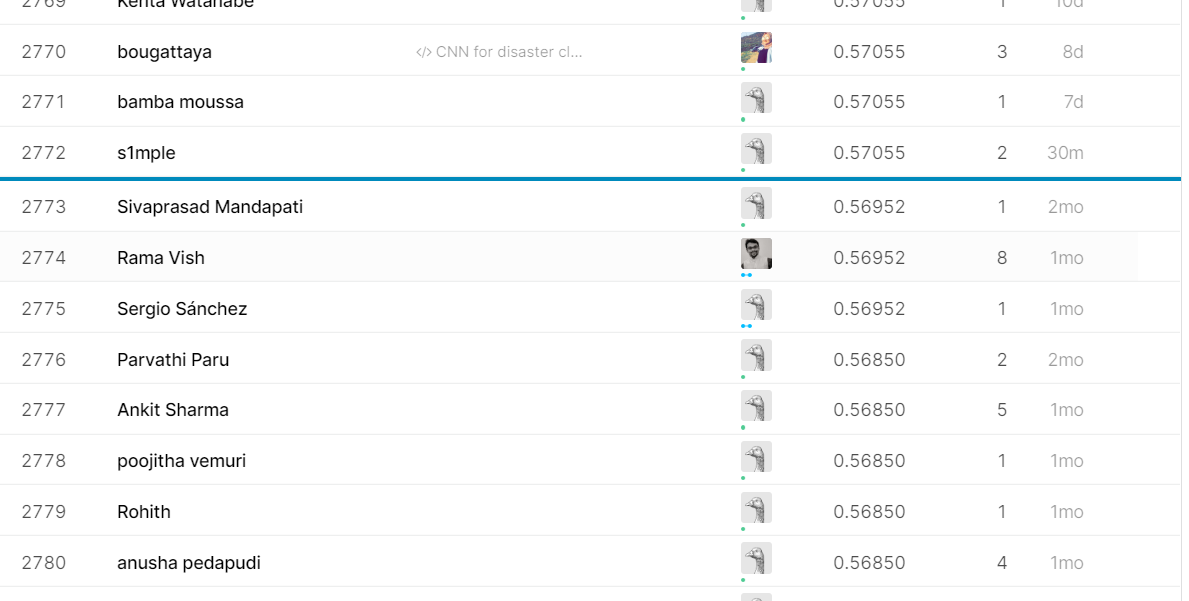
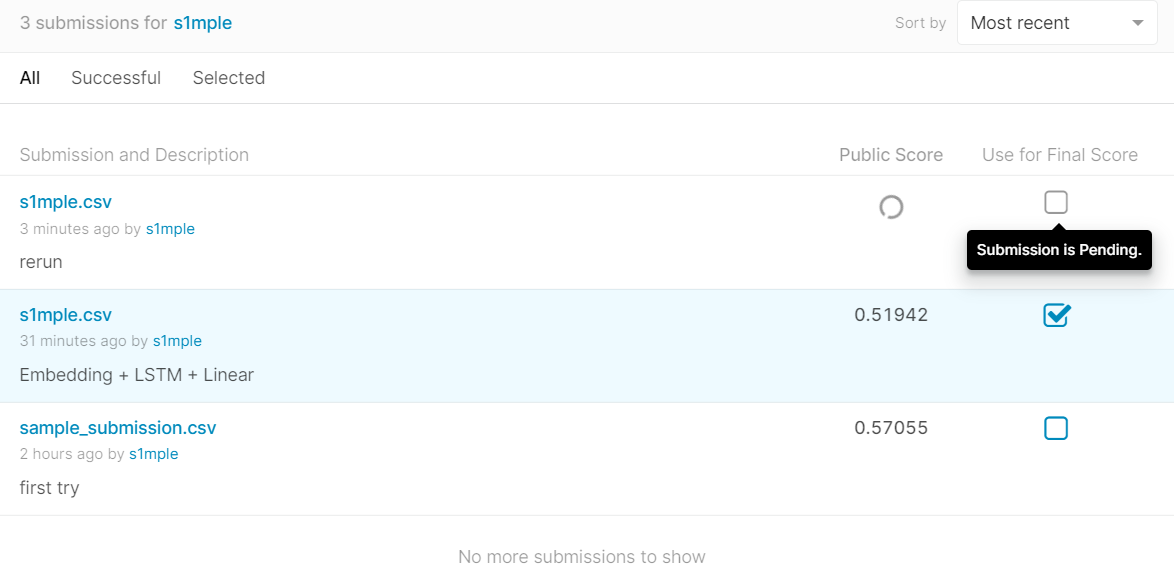
在线跑分
只有5分多
排名93%
效果奇差
总结
- 由于编程水平的限制,没有用更好的损失函数和优化算法
- 由于模型的输入被限制为了定长的batch_size的句子链,导致了部分的训练数据不可用以及部分的测试数据只能随便填(输入batchsize=16,只能取到16的倍数)
- 由于数据较少以及全用于训练,以至于本地的测试出现了过拟合的现象(本地最高训练准确率达到了98%,但实际显然在在线跑分上差到家了)
- 由于第二点的限制,导致一开始出现了最后一次读取的数据不足16的现象,导致了输入的维度不对,导致了Bug,但是经验有限,一直没看出来,尤其是使用GPU进行运行的时候,报错都特别的诡异,建议之后遇到bug可以关闭GPU再进行分析
- 还有一个问题是没有充分的利用信息,我只用了text这个维度进行预测
改进
减小训练
初步随手设置15epoch,减少过拟合
得分增加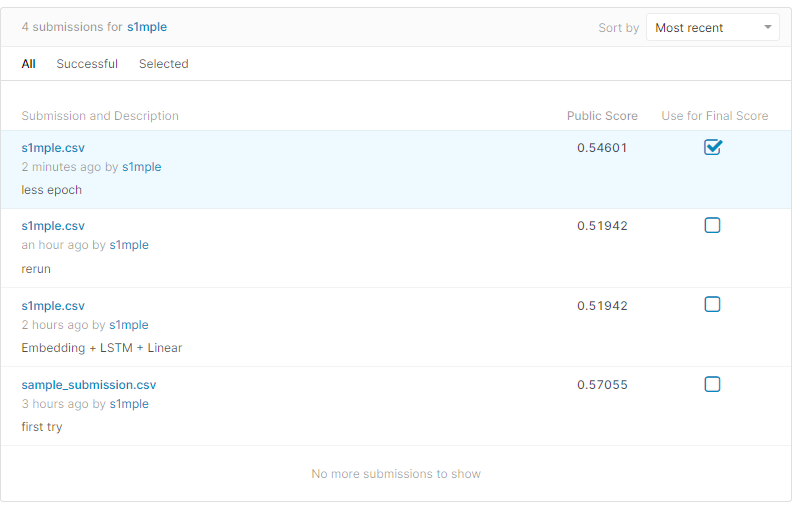
Drop_out
加上dropout
成绩有所进步
class LSTMTagger(nn.Module):def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size,batch_size,str_len):super(LSTMTagger, self).__init__()self.hidden_dim = hidden_dimself.str_len=str_lenself.batch_size=batch_sizeself.word_embeddings = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim)self.dropout = nn.Dropout(0.5)self.hidden2tag = nn.Linear(str_len*hidden_dim, tagset_size)self.hidden = self.init_hidden()def init_hidden(self):return (torch.zeros(1, self.batch_size, self.hidden_dim).cuda(),torch.zeros(1, self.batch_size, self.hidden_dim).cuda())def forward(self, sentence,state,train_flag):embeds = self.word_embeddings(sentence)#print(embeds.shape)self.hidden=statelstm_out, self.hidden = self.lstm(embeds.view(self.str_len, len(sentence), -1), self.hidden)#print("ls",lstm_out.shape)if train_flag:lstm_out=self.dropout(lstm_out)tag_space = self.hidden2tag(lstm_out.view(self.batch_size,-1))#print(tag_space.shape)#tag_scores = F.log_softmax(tag_space,dim=1)return tag_space ,self.hidden
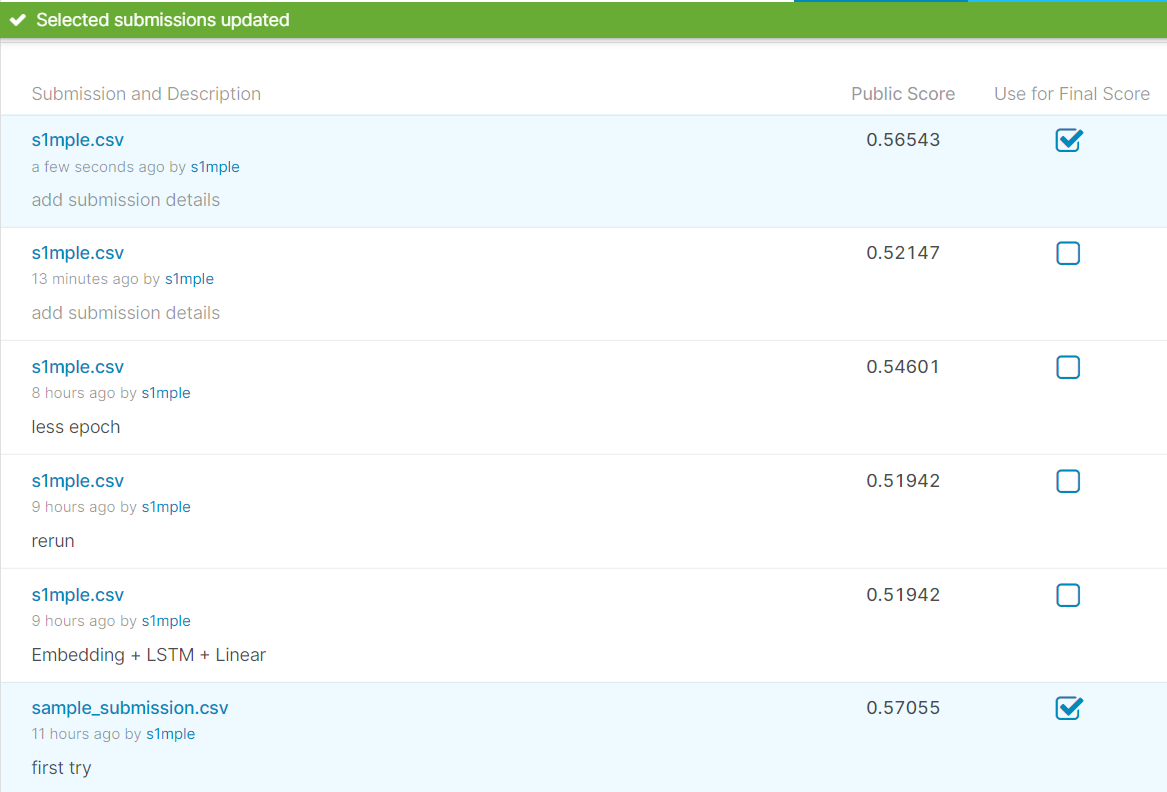
增加embedding维数和hidden_dim
懒的提交测试了。。。
model = LSTMTagger(300, 256, len(dict),1,16,31)
最终代码(不改了)
import pandas as pdimport numpy as npfrom sklearn.preprocessing import MinMaxScalerimport timeimport copyimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.autograd as autogradimport torch.nn.functionalfrom torch.utils.data import Dataset, DataLoaderfrom torchvision import transformsimport warningsimport torchimport timeUSE_CUDA = torch.cuda.is_available()base_path="D:\\New_desktop\\nlp-getting-started\\"read_train=pd.read_csv(base_path+'train.csv')train_data=read_train.iloc[0:read_train.shape[0],[1,2,3]]train_label=read_train.iloc[0:read_train.shape[0],[4]]train_label=torch.tensor(train_label[:read_train.shape[0]].values,dtype=torch.float)read_test = pd.read_csv(base_path + 'test.csv')test_data = read_test.iloc[0:read_train.shape[0], [1, 2, 3]]a=[]sentence=""for i in range(0, len(train_data)):sentence=sentence+str(train_data.iloc[i]['keyword'])sentence+=" "sentence=sentence+str(train_data.iloc[i]['location'])sentence += " "sentence=sentence+str(train_data.iloc[i]['text'])sentence += " "for i in range(0, len(test_data)):sentence=sentence+str(test_data.iloc[i]['keyword'])sentence+=" "sentence=sentence+str(test_data.iloc[i]['location'])sentence += " "sentence=sentence+str(test_data.iloc[i]['text'])sentence += " "dict = sentence.split()dict=set(dict)print(len(dict))w2i={}def word2index():index=0for i in dict:w2i[i]=indexindex+=1word2index()train_data['keyword'] = [[w2i[i] for i in str(x).split()] for x in train_data.keyword]train_data['location'] = [[w2i[i] for i in str(x).split()] for x in train_data.location]train_data['text'] = [[w2i[i] for i in str(x).split()] for x in train_data.text]#print(train_data[:read_train.shape[0]])test_data['keyword'] = [[w2i[i] for i in str(x).split()] for x in test_data.keyword]test_data['location'] = [[w2i[i] for i in str(x).split()] for x in test_data.location]test_data['text'] = [[w2i[i] for i in str(x).split()] for x in test_data.text]data_list=[]max_len=0for i in range(0, len(train_data)):if len(train_data.iloc[i]['text'])>max_len:max_len=len(train_data.iloc[i]['text'])print(max_len)for x in train_data.text:while len(x)<max_len:x.append(0)for i in range(0, len(train_data)):data_list.append(train_data.iloc[i]['text'])#print(len(data_list))traindata_tensor = torch.Tensor(data_list)if USE_CUDA:print("using GPU")traindata_tensor =traindata_tensor.cuda()train_label = train_label.cuda()#print(a.shape)#train_data=torch.tensor(train_data[:read_train.shape[0]].values,dtype=torch.float)#print(train_data)#print (len(train_data.iloc[0]))'''输入数据格式:input(seq_len, batch, input_size)h0(num_layers * num_directions, batch, hidden_size)c0(num_layers * num_directions, batch, hidden_size)输出数据格式:output(seq_len, batch, hidden_size * num_directions)hn(num_layers * num_directions, batch, hidden_size)cn(num_layers * num_directions, batch, hidden_size)'''class LSTMTagger(nn.Module):def __init__(self, embedding_dim, hidden_dim, vocab_size, tagset_size,batch_size,str_len):super(LSTMTagger, self).__init__()self.hidden_dim = hidden_dimself.str_len=str_lenself.batch_size=batch_sizeself.word_embeddings = nn.Embedding(vocab_size, embedding_dim)self.lstm = nn.LSTM(embedding_dim, hidden_dim)self.dropout = nn.Dropout(0.5)self.hidden2tag = nn.Linear(str_len*hidden_dim, tagset_size)self.hidden = self.init_hidden()def init_hidden(self):return (torch.zeros(1, self.batch_size, self.hidden_dim).cuda(),torch.zeros(1, self.batch_size, self.hidden_dim).cuda())def forward(self, sentence,state,train_flag):embeds = self.word_embeddings(sentence)#print(embeds.shape)self.hidden=statelstm_out, self.hidden = self.lstm(embeds.view(self.str_len, len(sentence), -1), self.hidden)#print("ls",lstm_out.shape)if train_flag:lstm_out=self.dropout(lstm_out)tag_space = self.hidden2tag(lstm_out.view(self.batch_size,-1))#print(tag_space.shape)#tag_scores = F.log_softmax(tag_space,dim=1)return tag_space ,self.hiddenmodel = LSTMTagger(300, 256, len(dict),1,16,31)model=model.cuda()print(model)exit()def train(model, train_data, train_label,num_epochs, learning_rate, batch_size):train_ls=[]#loss =torch.nn.CrossEntropyLoss()state=Noneloss = torch.nn.MSELoss()optimizer = optim.SGD(model.parameters(), lr=learning_rate,weight_decay=0)dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True)iter=0for epoch in range(num_epochs):correct = 0total=0start = time.time()index=0for X, y in train_iter:iter+=1index+=1if index>400:breakif state is not None:if isinstance (state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()X = X.long()(output, state) = model(X, state,True)#correct+=predicted.data.eq(label.data).cpu().sum()l = loss(output.float(), y)l.backward()optimizer.step()optimizer.zero_grad()#print(output)output = [1 if i > 0.5 else 0 for i in output]for i in range(len(output)):total+=1if output[i]==y[i]:correct+=1acc = correct / totalend = time.time()print("epoch ", str(epoch), "time: ",end-start ," loss: ", l.item(),"correct: ", correct, " total: ", total, "acc: ", acc)torch.save(model, 'model.pkl')eval(model, train_data, train_label, batch_size)train_ls.append(l.item())return train_lsTrain=train_data#model = torch.load('model.pkl')def eval(model,train_data, train_label,batch_size):test_list=[]dataset = torch.utils.data.TensorDataset(train_data, train_label)train_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=False)with torch.no_grad():state = Noneindex = 0for X, y in train_iter:index += 1if index <=400:continueif index >= 470:breakif state is not None:if isinstance(state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()X = X.long()(output, state) = model(X, state,False)output = [1 if i > 0.5 else 0 for i in output]for i in range(len(output)):test_list.append(output[i])correct=0for i in range(0, len(test_list)):if train_label[i]==test_list[i]:correct+=1print("eval: ",correct/len(test_list))def out_put(model):test_list = []max_len = 31for x in test_data.text:while len(x) < max_len:x.append(0)if len(x)>max_len:x =x[0:30]test_num=len(test_data.text)#print("sda",test_num)for i in range(0, len(test_data)):data_list.append(test_data.iloc[i]['text'])test_data_tensor = torch.Tensor(data_list)if USE_CUDA:print("using GPU")test_data_tensor = test_data_tensor.cuda()with torch.no_grad():result_dataset = torch.utils.data.TensorDataset(test_data_tensor)result_dataloader = torch.utils.data.DataLoader(result_dataset, batch_size=16, shuffle=False)state=Noneindex=0for X in result_dataloader:X=X[0]if index>=203:breakindex+=1if state is not None:if isinstance(state, tuple): # LSTM, state:(h, c)state = (state[0].detach(), state[1].detach())else:state = state.detach()X = X.long()(output, state) = model(X, state,False)# correct+=predicted.data.eq(label.data).cpu().sum()output = [1 if i > 0.5 else 0 for i in output]for i in range(len(output)):test_list.append(output[i])print(len(test_list))while len(test_list)<3263:test_list.append(0)df_output = pd.DataFrame()aux = pd.read_csv(base_path + 'test.csv')df_output['id'] = aux['id']df_output['target'] = test_listdf_output[['id', 'target']].to_csv(base_path + 's1mple.csv', index=False)train(model,traindata_tensor,train_label,30,0.01,16)print("\n")eval(model,traindata_tensor, train_label,16)out_put(model)

若有收获,就点个赞吧
0 人点赞
