Insight & target problem
基于token-level的细粒度错误检测
Solution
数据构造,使用了构造策略如下: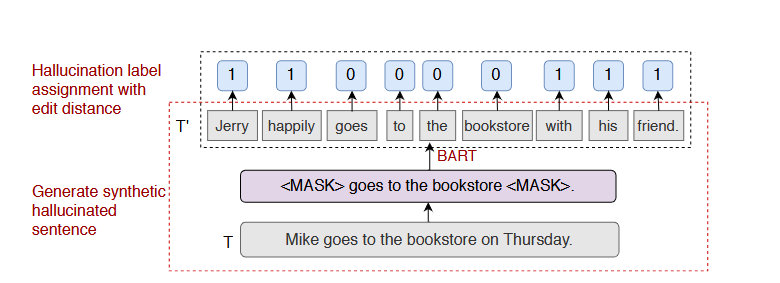

怕之学习到了基于编辑距离,导致退化,所以又搞了一个用paraphrase。然后标签用的是paraphrase到noise的编辑距离,这样在利用target和noise训练的时候就不只是单纯的编辑距离了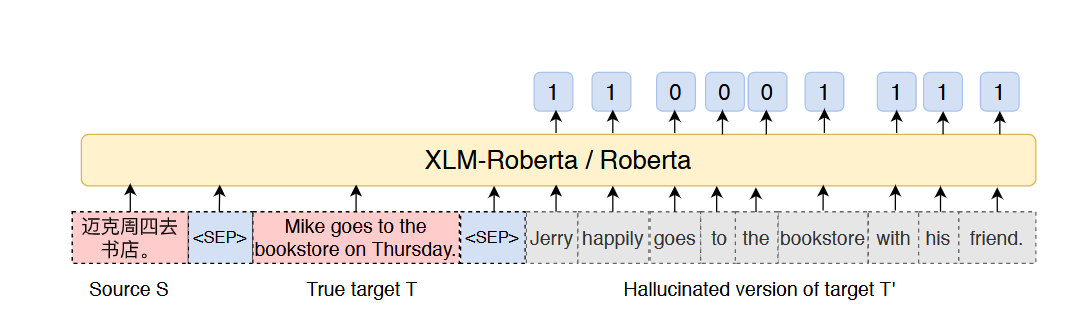
Highlight
很多错误的是名词啥的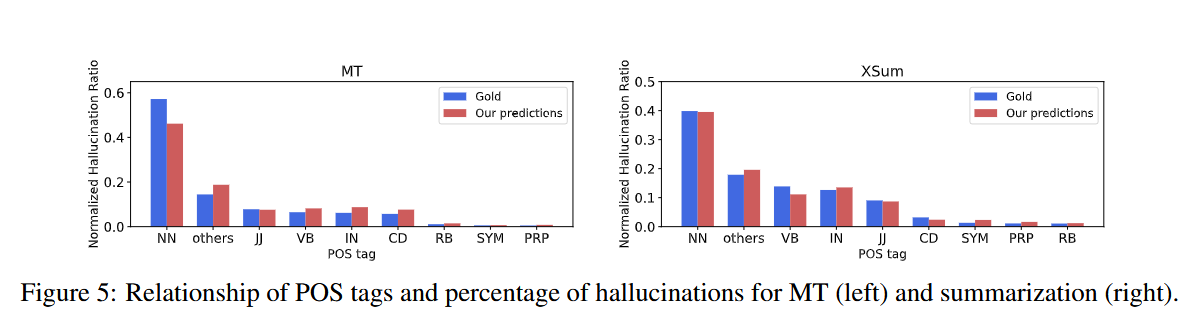
以及下游任务的进一步的使用,比如说
在训练的时候,做loss trunction,或者是在decode阶段直接Mask了可疑位置的表示,可以进一步的提升MT性能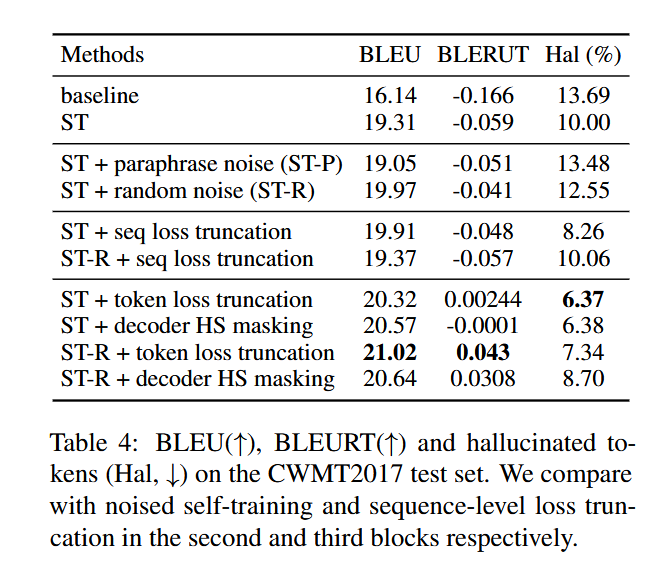
还有一个是从低资源的带噪数据中做筛选的一个算法
低资源的很多数据都是带噪音的,所以需要一个算法来做一个筛选
Others

若有收获,就点个赞吧
0 人点赞
