试图实现Extractive Summarization as Text Matching中的模型
数据处理读取
基本思路
- 暂时使用lead3里的处理和读取
- 然后对应的候选摘要是对原Docment里的所有句子和原文档计算Rouge平均值,然后选择较高的5个。原论文使用的是BertExt,没弄明白,先用这个代替
- 然后对5个句子排列组合C(5,3)得到10个句子,这里用到了python里的from itertools import combinations。使用起来比较方便
- 对所有的候选和所有的数据用token编码,并转为tensor
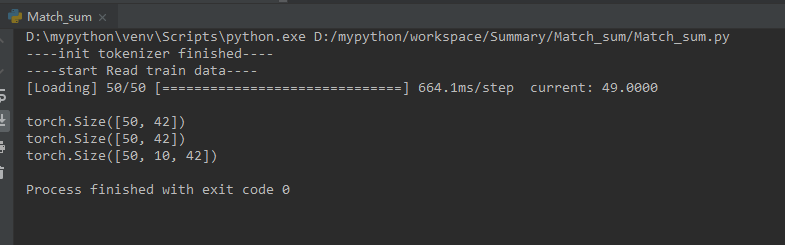
调用结果
```python from Dataloader import Loader document_path=”train.txt.src” label_path=”train.txt.tgt” base_path=”D:\New_desktop\summarization_papers\“
def Train(): loader=Loader(“bert”) train_data,train_label,train_candi=loader.read_data(base_path+document_path,base_path+label_path,50) print(“\n”) print(train_data.size()) print(train_label.size()) print(train_candi.size())
Train()
```pythonimport reimport numpy as npimport torch.nn as nnimport torch.nn.functional as Fimport torch.optim as optimimport torch.autograd as autogradimport torch.nn.functionalfrom torch.utils.data import Dataset, DataLoaderimport torchimport timeimport argparseimport osfrom itertools import combinationsfrom transformers import BertTokenizerfrom transformers import BertForSequenceClassificationfrom transformers import BertConfigfrom transformers import BertModelUSE_CUDA = torch.cuda.is_available()base_path="D:\\New_desktop\\summarization_papers\\"tokenizer = BertTokenizer.from_pretrained(base_path)print("----init tokenizer finished----")def normalizeString(s):#s = re.sub(r"([.!?])", r" \1", s)#s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)s=s.strip()s = s.replace("\n", "")return sdef possess_sentence(s):lines=s.split("##SENT##")for i in lines:i=normalizeString(i)return linesfrom rouge import Rougefrom util import ProgressBarclass Loader:def __init__(self, name):self.name = nameself.train_data={}self.train_data['text']=[]self.train_data['label']=[]self.train_data["candi"]=[]self.rouge=Rouge()def get_document(self,document):sentences=possess_sentence(document)return sentencesdef get_labels(self,label):sentences = possess_sentence(label)return sentencesdef get_score(self,sen1,sen2):score=0rouge_score = self.rouge.get_scores(sen1, sen2)score+= rouge_score[0]["rouge-1"]['r']score+= rouge_score[0]["rouge-2"]['r']score+= rouge_score[0]["rouge-l"]['r']return score/3def read_data(self,path1,path2,pairs_num,max_len=40):print("----start Read train data----")fo = open(path1, "r", encoding='gb18030', errors='ignore')fl = open(path2, "r", encoding='gb18030', errors='ignore')data_list=[]label_list=[]candi_list=[]pbar = ProgressBar(n_total=pairs_num, desc='Loading')for i in range(pairs_num):pbar(i, {'current': i})line1 = fo.readline()line2 = fl.readline()#line1="A ##SENT## B ##SENT## C ##SENT## D ##SENT## E ##SENT## F"do = self.get_document(line1)la = self.get_labels(line2)sentences={}document = " ".join(do)la = " ".join(la)for i in do:if i != None:sentences[i]=self.get_score(i,document)sentences = sorted(sentences.items(), key=lambda x: x[1],reverse = True)candidata_sentence_set=sentences[:5]sentences=[]#print(candidata_sentence_set)#print(type(candidata_sentence_set))for i in candidata_sentence_set:sentences.append(i[0])#indices = list(combinations(sentences, 2))indices = list(combinations(sentences, 3))candidata=[]#print(sentences)#print(indices)for i in indices:#print(type(i))#print(len(i))candidata.append(" ".join(i))#print(candidata[0])#print(type(candidata[0]))candidata_data=[]for i in candidata:candidata_data.append(tokenizer.encode(i, add_special_tokens=False))#print(len(candidata_data))#print(candidata_data[0])self.train_data['text'].append(tokenizer.encode(document, add_special_tokens=False))self.train_data['label'].append(tokenizer.encode(la, add_special_tokens=False))self.train_data['candi'].append(candidata_data)for x in self.train_data['text']:if len(x) >= max_len:x = x[0:max_len-1]while len(x) < max_len:x.append(0)x.append(102)l = xx = [101]x.extend(l)data_list.append(x)for x in self.train_data['label']:if len(x) >= max_len:x = x[0:max_len-1]while len(x) < max_len:x.append(0)x.append(102)l = xx = [101]x.extend(l)label_list.append(x)for i in self.train_data['candi']:temp=[]for x in i:if len(x) >= max_len:x = x[0:max_len-1]while len(x) < max_len:x.append(0)x.append(102)l = xx = [101]x.extend(l)temp.append(x)candi_list.append(temp)train_data = torch.tensor(data_list)train_label = torch.Tensor(label_list)train_candi = torch.Tensor(candi_list)return train_data,train_label,train_candi
构造损失函数
补充资料
原论文开源代码里用的损失函数我完全没有用过,看论文的时候只有几个公式觉得很简单来着。。。
开始补充资料
这个损失函数看起来很有意思?
似乎我之前做句子相似度匹配TextMatching的时候可以用的?
MarginRankingLoss 你们可能对这个损失函数比较陌生。在机器学习领域,了解一个概念最直观的最快速的方式即是从它的名字开始。前端
MarginRankingLoss也是如此,拆分一下,Margin,Ranking,Loss。机器学习
Margin:前端同窗对Margin是再熟悉不过了,它表示两个元素之间的间隔。在机器学习中其实Margin也有相似的意思,它能够理解为一个可变的加在loss上的一个偏移量。也就是代表这个方法能够手动调节偏移。固然Margin不是重点。函数
Ranking:它是该损失函数的重点和核心,也就是排序!若是排序的内容仅仅是两个元素而已,那么对于某一个元素,只有两个结果,那就是在第二个元素以前或者在第二个元素以前。其实这就是该损失函数的核心了。学习
咱们看一下它的loss funcion表达式。cdn
margin咱们能够先无论它,其实模型的含义不言而喻。blog
y只能有两个取值,也就是1或者-1。排序
- 当y=1的时候,表示咱们预期x1的排名要比x2高,也就是x1-x2>0
- 当y=-1的时候,表示咱们预期x1的排名要比x2高,也就是x1-x2<0
何时用?
- GAN
- 排名任务
- 开源实现和实例很是少


若有收获,就点个赞吧
0 人点赞
