大致的意思就是现有的基于置信度、不确定性的工作
这里的置信度和不确定性和我之前想的不一样,这里的置信度指的是模型在更换了一些随机因素之后结果上的变化。比如说在测试阶段也开着Dropout,然后看看输出的差异,假如输出差异大,那就认为是一个out of domain的样本。不确定性高的样本不是一个好的样本,可以过滤数据。
测试这种不确定性方法的算法是:
对测试集的所有样本计算他们的不确定性,然后我们丢弃X%的测试样本,理论说来说不确定性高的数据表现差,对应的就会被丢弃,因此丢弃的越多,表现越好。假如估计不确定性的方法好,那应该同样丢X%的样本的时候,指标应该更高(丢掉的样本是更差的)
这样的不确定性方法,最起码可以估计出模型的表现,是一个reference free的方法
实验部分有点意思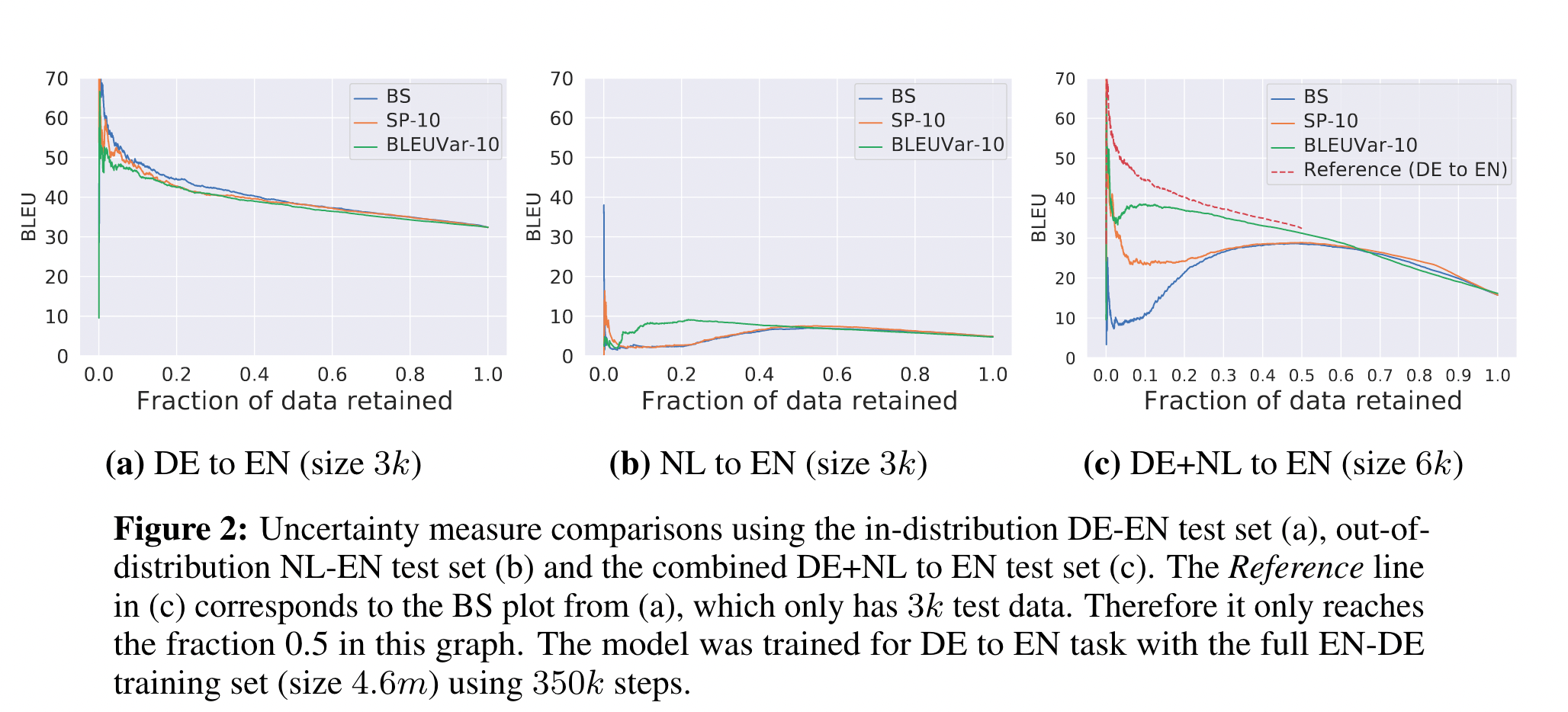
荷兰语和德语共享的词表,因此对于德英翻译来说,荷兰语的输入就是OOD的,
然后他在分别在德语输入测试集,荷兰语输入测试集,混合输入测试集上测试
红色的线就是德语输入的线,越靠近说明多数的德语数据都被保存的很好,在全集上保留同样的数据,保留的数据很相近。
另一个就是看看他们的分布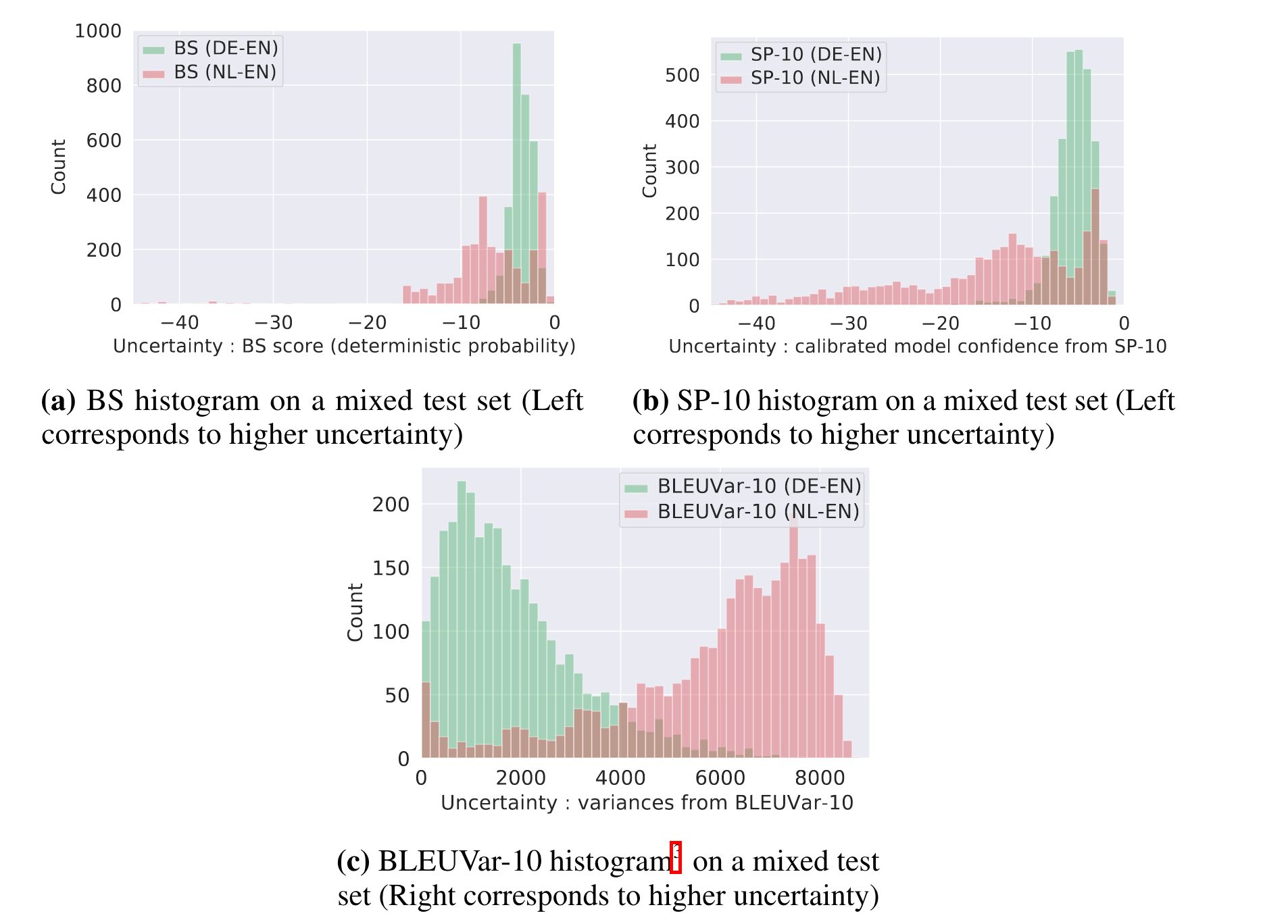
另外一个提到了句子长度的影响,因为ID和OOD的数据长度不一样,需要测试证明说模型不是依靠长度来划分的。

若有收获,就点个赞吧
0 人点赞
