模型设计
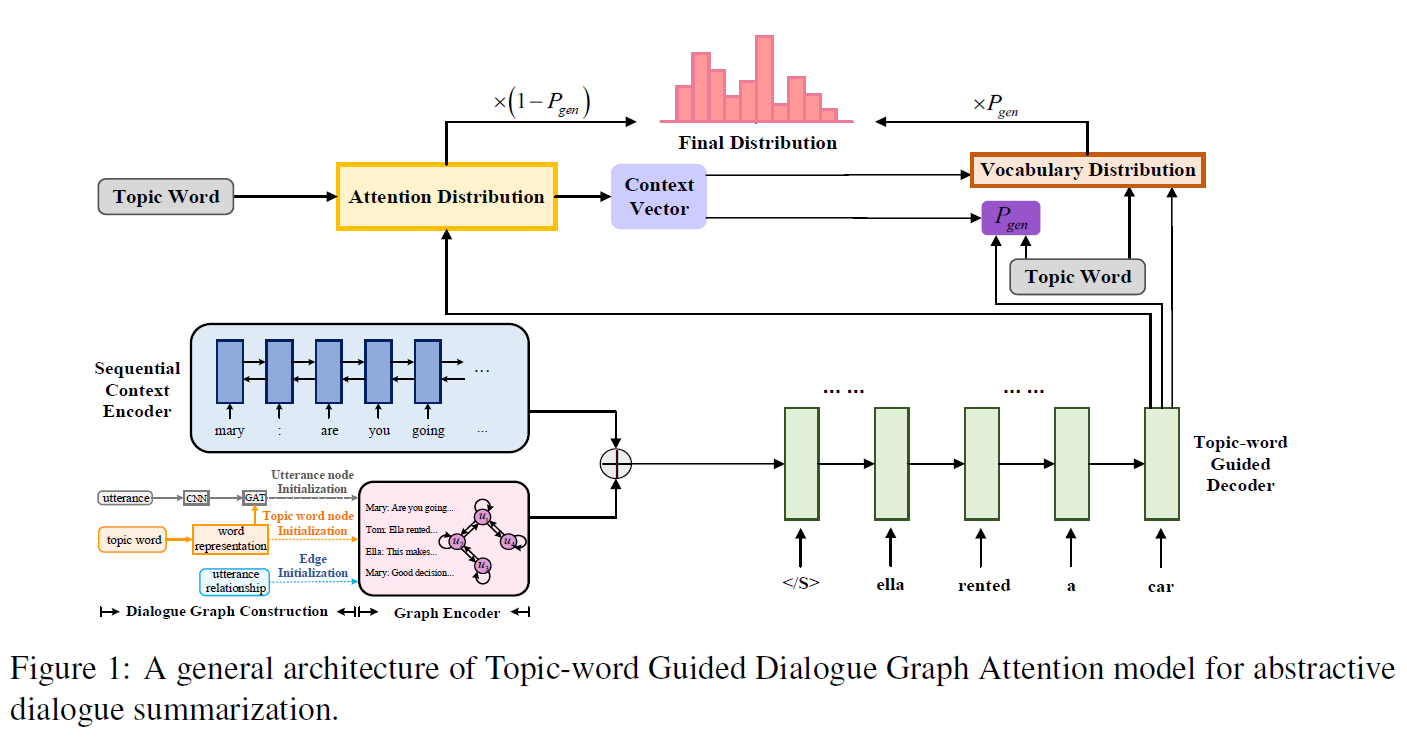
亮点1:使用了GNN的策略来建模各个句子,最后把LSTM表示和GNN联合
亮点2:关键词抽取之后,参与了Attention比例的生成和p_gen的计算以及最后decoder的输出(coverage)
GNN结构设计:
- 节点Node是句子和主题词
- 边Edge就是节点之间
- 初始化,关键词节点用词向量初始化,句子用CNN,用一种可以衡量相关度的注意力机制shared graph attention mechanism。边的初始化,不使用完全图,只在有共享关键词的节点之间建立一条边
GNN内部使用了自注意力和FFN
把关键词向量做平均池化之后作为feature加入Coverage机制里的C的计算
在计算p_gen的时候同样处理
特色
特征词加入了生成,专门用LDA找到关键词
然后在Coverage机制里加入了关键词
在Point Copy机制里也加入了关键词的参与
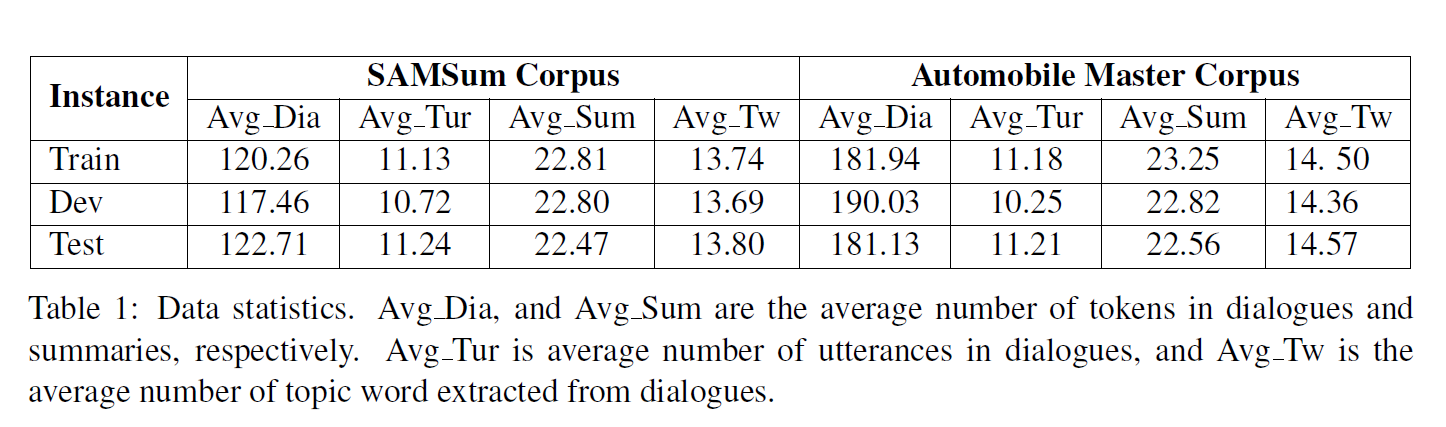
数据
SAMSum数据集:什么都有,生活化
Automobile Master Corpus:客服和顾客的对话,包括图片和Speech
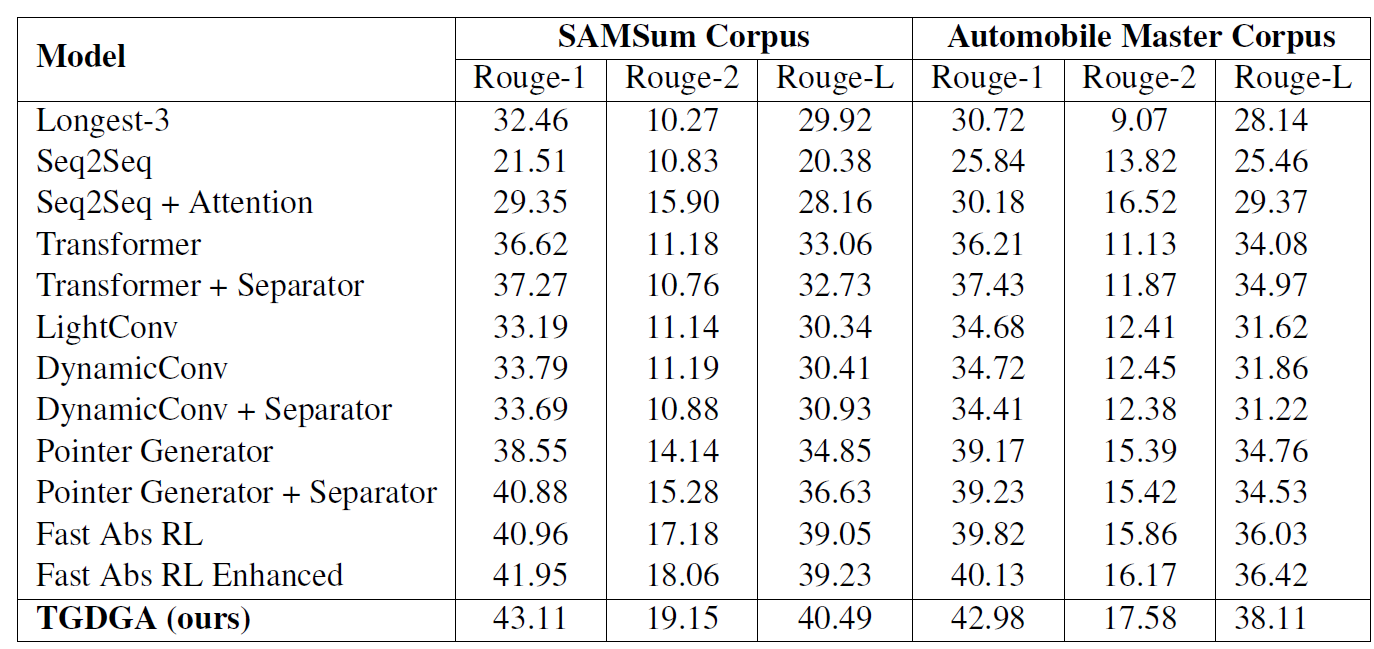
结果
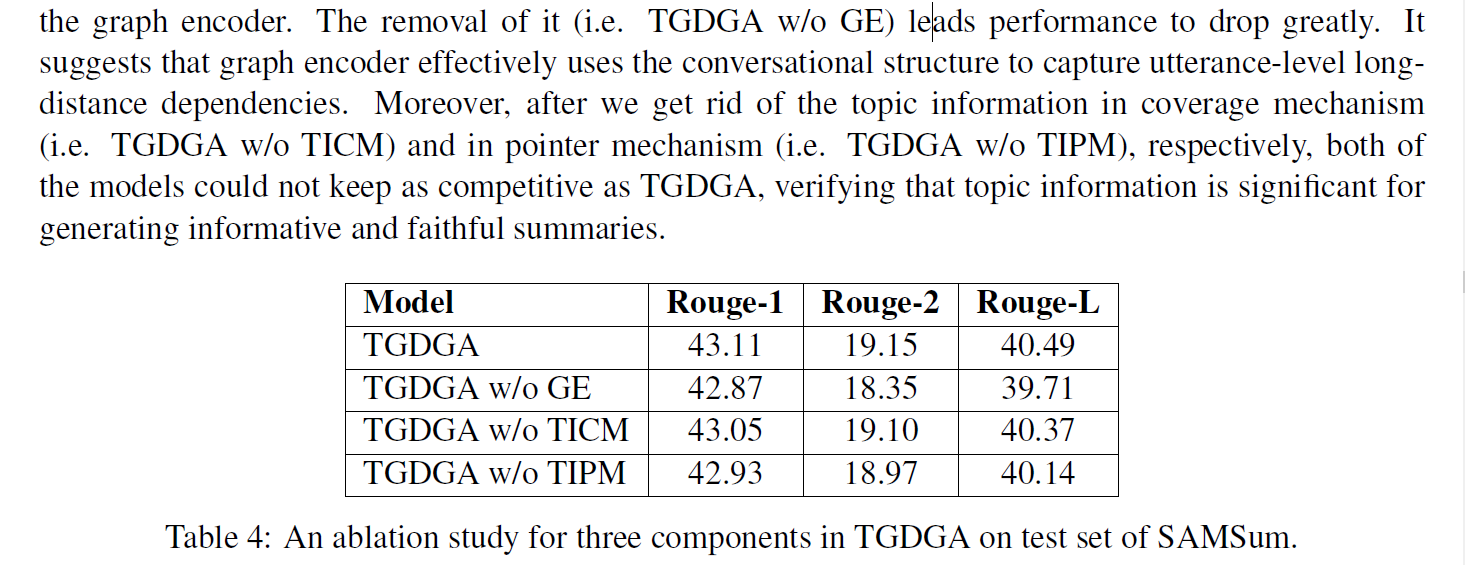
消融实验
分别测试了没有图结构编码器以及主题信息不参与coverage和不参与point copy的结果
- GNN捕获句子级别信息
- 主题信息重要
Case Study 和Attention可视化
Fast Abs RL Enhanced model删除了一部分的上下文导致信息缺失,摘要的动作主体可能错误
PGN Baseline容易造成重复和冗余

若有收获,就点个赞吧
0 人点赞
