模型简述
模型结构
GRU1 输入词embed获取句子embed
GRU2 输入句子embed获取document embed
用上次选中的句子表示和文档表示两个向量输入GRU得到h_t
把h_t和每一个还没有选中的句子用MLP得到一个分数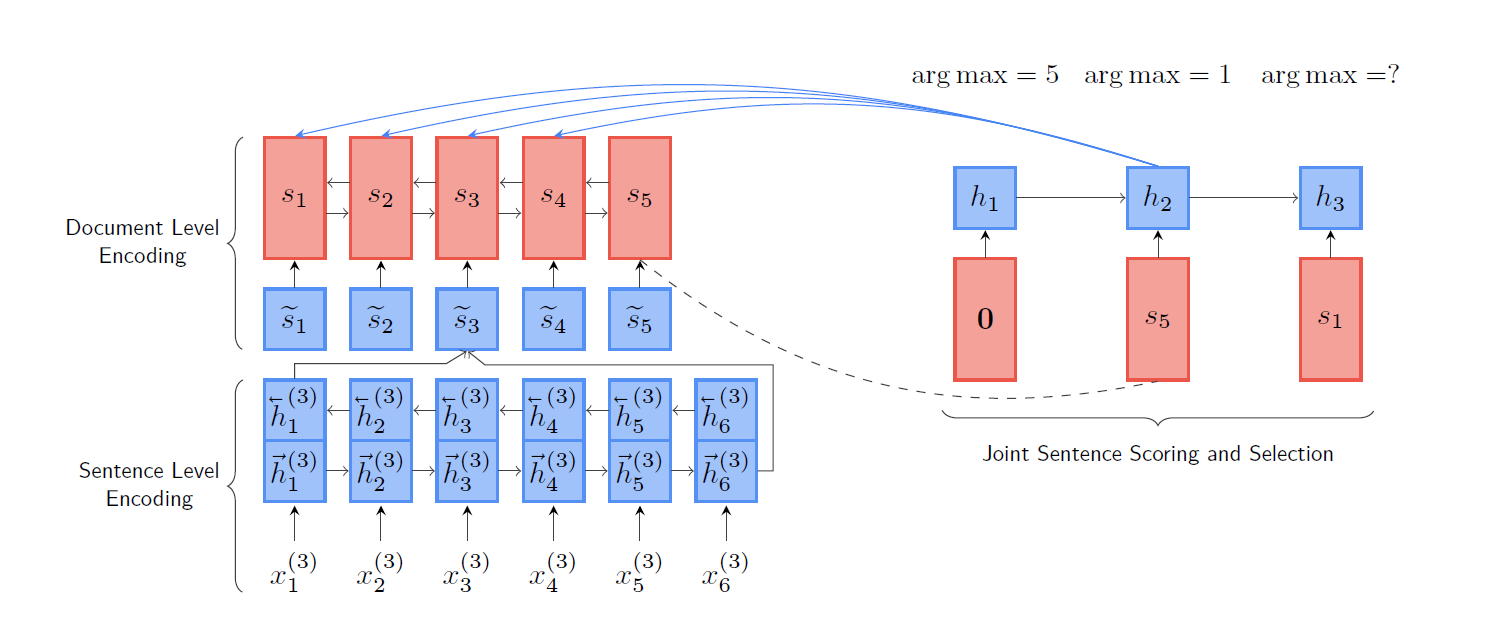
训练目标
上文得到的分数,通过softmax得到prob分布
同时计算每一步的得分,即选择句子加入前后ROUGE F1的变化值
由于F1变化可能是负数,所以做了一些处理归一到0-1,然后用带参数的softmax得到真实分数分布a
最后最小化真实分数和prob分布的KL散度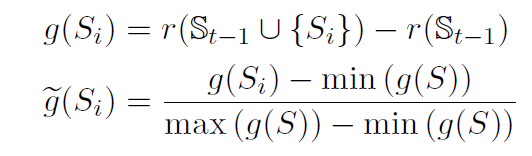
分析
分析1
NEUSUM固定了抽取的句数,直接抽取三句,于是对每一步的正确率进行分析,正确率就是抽取句子在oracle中的概率。这个分析对于体现NEUSUM的特性(考虑历史信息)还是很有意思的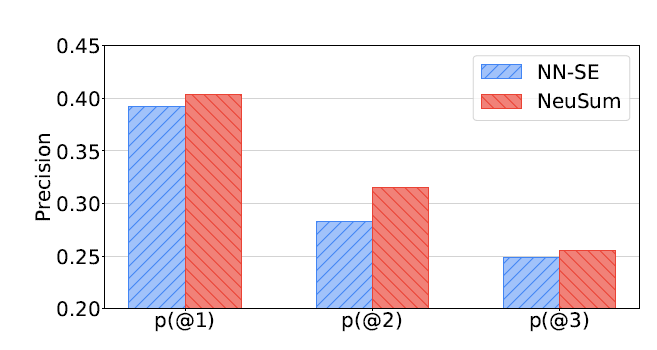
- 可以看到NEUSUM最亮眼的就是第二步的抽取,可能是由于计算score引入了上一步抽取的句子,所以在第二部的时候考虑了第一步的信息,进而考虑了冗余等等的因素
可以看到两个模型都随着步数,大幅下降正确率。作者认为是Error的累计,第一步错影响第二步等等。同时因为之前选对了,对后面的选择变难了(好选的被选走了)
分析2
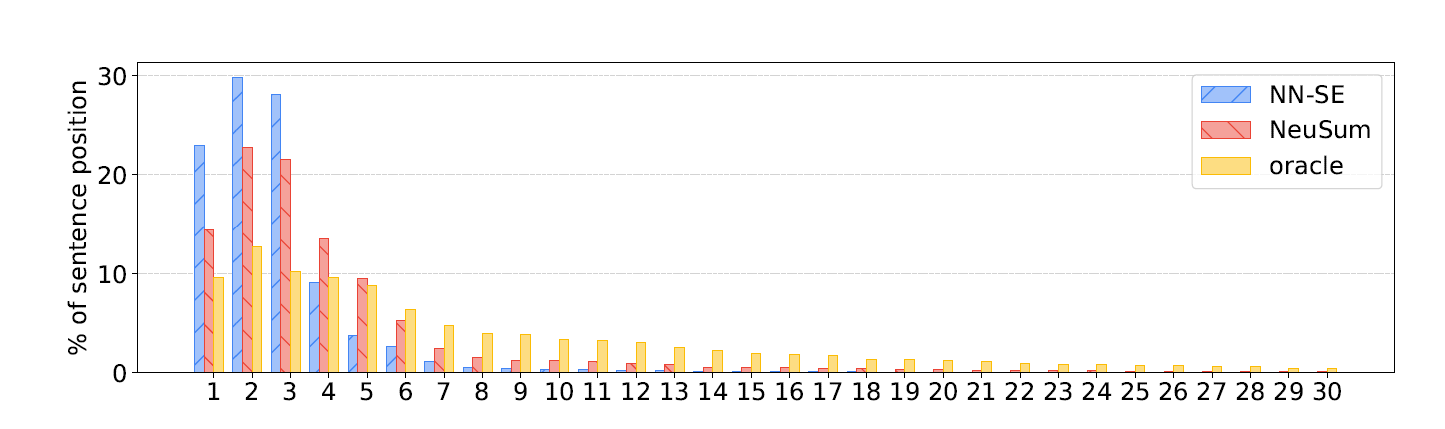
另一个分析就是之前也提到过的句子位置分布
Oracle的分布比较平均
- NEUSUM相对的比较摆脱前三句的魔咒,分布相对靠近oracle,这也是能够超过lead3的原因
- NN-SE相对差一些,和lead3就差不多了
以上可能由于
- lead3确实强,前三句子确实很有吸引力,尤其是在CNN/DM这种新闻上,前5句有50+%标注为该选
- 相对靠后的句子可能更重要,但是和前面的句子margin差的不是很多,单独打分和选择的模型看不出来,就会去选择更加保险的lead句子,导致了退化。NEUSUM是考虑了历史信息,同时头尾的句子相互竞争,于是能够选到这种句子。
问题
- 为什么只用了上一次抽取的句子加入计算分数,而不是用已抽取的部分加入计算过程?(计算分数的时候原文把上一次抽取的句子和文档表示放进了GRU算ht,ht用于score计算,为啥不编码全部的已抽取部分)
- 这个暂时看不出有matchsum中类似的相似度偏好,为什么matchsum没有用这种方式(MLP+KL散度)而是使用了Cos-similarity+MarginLoss?因为那样子更好?更能捕获这种score信息?如果把MatchSum的损失换为这个会咋样。或者说我直接在MatchSum里用MSE Loss拟合ROUGE分数呢。
- 这里为什么不用Attention来主导这个过程,类似于生成式的seq2seq结构,只不过基本单元是句子表示,encoder每一个原文句子,然后decoder用已抽取的部分作为hidden state和encode state做attention来计算整体的hidden state,然后再和句子算分数呗,感觉会比原结构好一点(没啥依据,瞎想的)
- 有没有人用了BERT重复一样的过程。结果咋样。
- 如果按照这里的思路,BERTSUM感觉也有问题,BERTSUM魔改BERT结构,然后句子之间Attention,直接sigmoid选分数高的,这里也没有应用到已经选择的历史信息,也是独立的选择,只有句子间的Attention建模了少量的句子间信息。
- 如果按照这么分析,抽取式摘要有太多的bias了,包括在这里和BERTSUM都提到的位置分布,oracle仅仅是少量的倾向LeadN,更多的前n句只是次优解,但是很多模型都被带偏到坑里了。难以摆脱这种分布。

若有收获,就点个赞吧
0 人点赞
