Model
encoder
对原文序列分块
每一块通过对块内的文字序列输入RNN计算得到
全文表示通过把每一块序列表示的表示输入RNN得到(原文这里都是用BiLSTM)
Discourse-aware decoder
首先是Decoder state和每一个分段的表示计算权重
每一段的每一个词都和Decoder state计算权重,然后这个权重乘分段权重
有了每一个词的权重过之后做一个word-level的Attention得到上下文的信息表示 c_t
最后这个权重和Decoder-state,乘上一个词汇矩阵权重,预测下一个词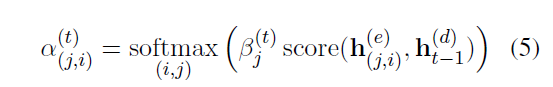
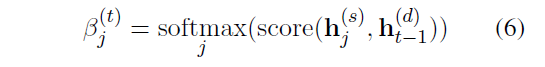

最后加上了copy和coverage机制
copy就是在选词的时候加上了一个从原文选词的概率
coverage就是在选的时候加上了一个已有信息的向量
Data
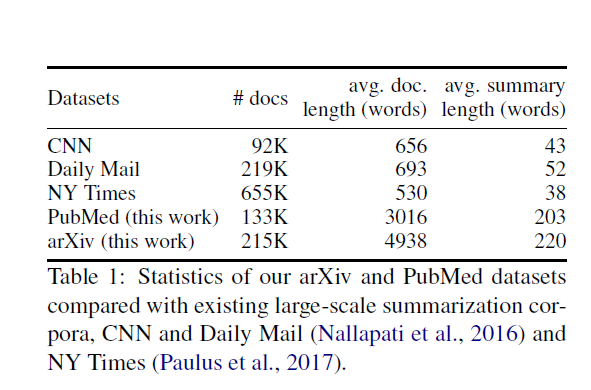
论文用的数据是PubMed和Arxiv的论文
最基本的特点就是
- 有很明显的分块信息
- 文章非常的长
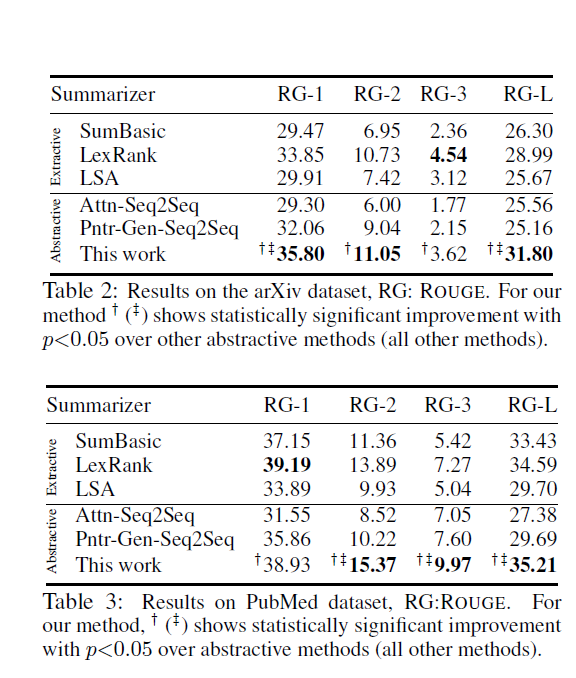
Result
两个数据集实验,只听说过PubMed,找来MatchSum的结果对比
ROUGE1 提高了大致2.5个点,ROUGE2提升5个点,ROUGE-L1个点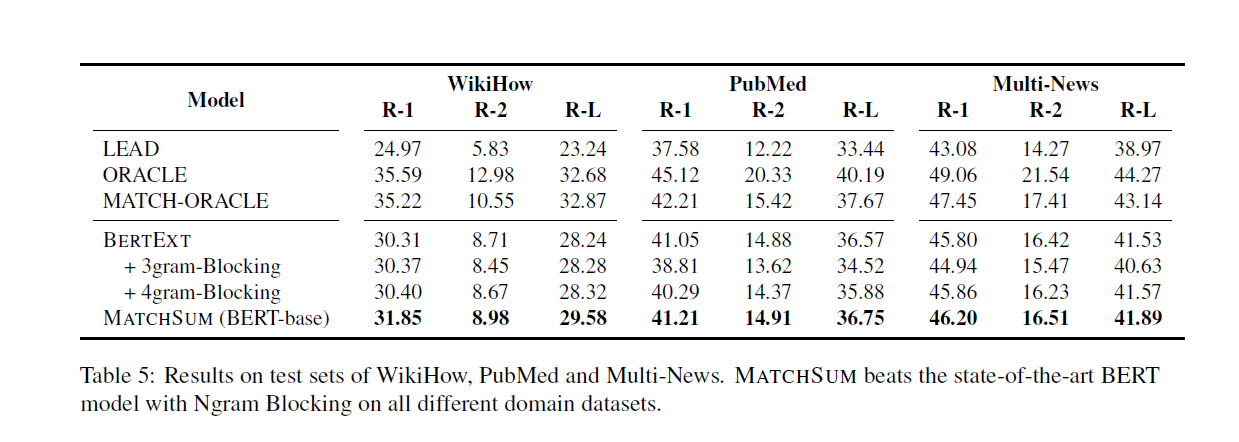

若有收获,就点个赞吧
0 人点赞
