QA思路1
我的理解是从原文里找到答案的开始和结束位置
基于SQuaD里的问题:答案在原文的特性,对问题找到答案的开始和结束位置
**
- 这是一个封闭的数据集,也就是说,问题的答案始终是原文(context)中上下文的一部分,并且是连续的一段
- 因此,找到答案的问题可以简化为找到与答案相对应的上下文的开始索引和结束索引
- 75%的答案少于4个单词
**
应用领域:Question Answer(QA,问答系统)与阅读理解 QA中文一般叫做问答系统,是NLP的一个重要应用领域,也是个具有很长历史的子领域了,我记得我读书的时候,差一点就选了这个方向做博士开题方向……好险……当时的技术发展水准,我记得是各种trick齐飞, 靠谱共不靠谱技术一色…..当然,其实我最终还是选择了一个更糟糕的博士开题方向 …….这应该是墨菲定律的一个具体例子?“选择大于努力”,这个金句,一直被证明,从未被颠覆。在读博士们请留心下这句肺腑之言,一定选好开题方向。当然,有时候能够选什么方向也由不得你,上面是说在你有选择自由的时候需要注意的地方。 QA的核心问题是:给定用户的自然语言查询问句Q,比如问“美国历史上最像2B铅笔的总统是谁?”,希望系统从大量候选文档里面找到一个语言片段,这个语言片段能够正确回答用户提出的问题,最好是能够直接把答案A返回给用户,比如上面问题的正确答案:“特·不靠谱·间歇脑抽风·朗普”。 很明显,这是个很有实用价值的方向,其实搜索引擎的未来,很可能就是QA+阅读理解,机器学会阅读理解,理解了每篇文章,然后对于用户的问题,直接返回答案。 QA领域是目前Bert应用效果最好的领域之一,甚至有可能把“之一”都能拿掉。我个人认为,可能的原因是QA问题比较纯粹。所谓的“纯粹”,是说这是个比较纯粹的自然语言或者语义问题,所需要的答案就在文本内容里,顶多还需要一些知识图谱,所以只要NLP技术有提升,这种领域就会直接受益。当然,可能也跟QA问题的表现形式正好比较吻合Bert的优势有关。那么Bert特别适合解决怎样的问题?在本文后面专门会分析这个事情。 目前不同的在QA领域利用Bert的技术方案大同小异,一般遵循如下流程:
QA应用Bert,从流程角度,一般分为两个阶段:检索+QA问答判断。首先往往会把比较长的文档切割成段落或者句子n-gram构成的语言片段,这些片段俗称Passage,然后利用搜索里的倒排索引建立快速查询机制。第一个阶段是检索阶段,这个和常规的搜索过程相同,一般是使用BM25模型(或者BM25+RM3等技术)根据问句查询可能的答案所在候选段落或者句子;第二个阶段是问答判断。在训练模型的时候,一般使用SQuAD等比较大的问答数据集合,或者手上的任务数据,对Bert模型进行 Fine-tuning;在应用阶段,对于第一阶段返回的得分靠前的Top K候选Passage,将用户问句和候选passage作为Bert的输入,Bert做个分类,指出当前的Passage是否包括问句的正确答案,或者输出答案的起始终止位置。这是一个比较通用的利用Bert优化QA问题的解决思路,不同方案大同小异,可能不同点仅仅在于Fine-tuning使用的数据集合不同。 QA和阅读理解,在应用Bert的时候,在某种程度上是基本类似的任务,如果你简化理解的话,其实可以把上述QA流程的第一阶段扔掉,只保留第二阶段,就是阅读理解任务应用Bert的过程。当然,上面是简化地理解,就任务本身来说,其实两者有很大的共性,但是也有些细微的区别;一般普通QA问题在找答案的时候,依赖的上下文更短小,参考的信息更局部一些,答案更表面化一些;而阅读理解任务,要正确定位答案,所参考的上下文范围可能会更长一些,部分高难度的阅读理解问题可能需要机器进行适当程度的推理。总体感觉是阅读理解像是平常QA任务的难度加大版本任务。但是从Bert应用角度,两者流程近似,所以我直接把这两个任务并在一起了。我知道,上面的话估计会有争议,不过这个纯属个人看法,谨慎参考。 前面提过,QA领域可能是应用Bert最成功的一个应用领域,很多研究都证明了:应用Bert的预训练模型后,往往任务都有大幅度的提升。下面列出一些具体实例。
而阅读理解任务,应用Bert后,对原先的各种纷繁复杂的技术也有巨大的冲击作用,前几年,我个人觉得尽管阅读理解领域提出了很多新技术,但是方法过于复杂了,而且有越来越复杂化的趋向,这绝对不是一个正常的或者说好的技术发展路线,我觉得路子有可能走歪了,而且我个人一直对过于复杂的技术有心理排斥感,也许是我智商有限理解不了复杂技术背后的深奥玄机?不论什么原因,反正就没再跟进这个方向,当然,方向是个好方向。而Bert的出现,相信会让这个领域的技术回归本质,模型简化这一点会做得更彻底,也许现在还没有,但是我相信将来一定会,阅读理解的技术方案应该是个简洁统一的模式。至于在阅读理解里面应用Bert的效果,你去看SQuAD竞赛排行榜,排在前列的都是Bert模型,基本阅读理解领域已经被Bert屠榜了,由这个也可以看出Bert在阅读理解领域的巨大影响力。


QA思路2
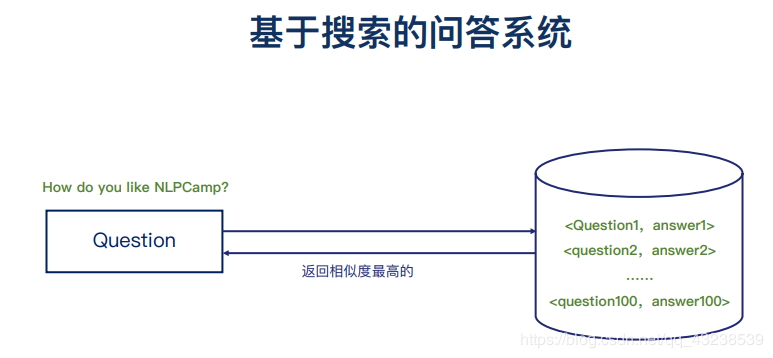
这个思路基本是有一个问题和已有的答案库
然后对问题做语义分析,找到已有问题中语义中最相近的
如何根据这个语料库匹配问题答案呢?
基于用户输入的文本和语料库中的问题文本进行相似度对比,选择一个相似度高的来实现问题与答案的匹配。(相似度的实现后面会解释)
综合来说 问答系统的模型可以表示为下边这个图
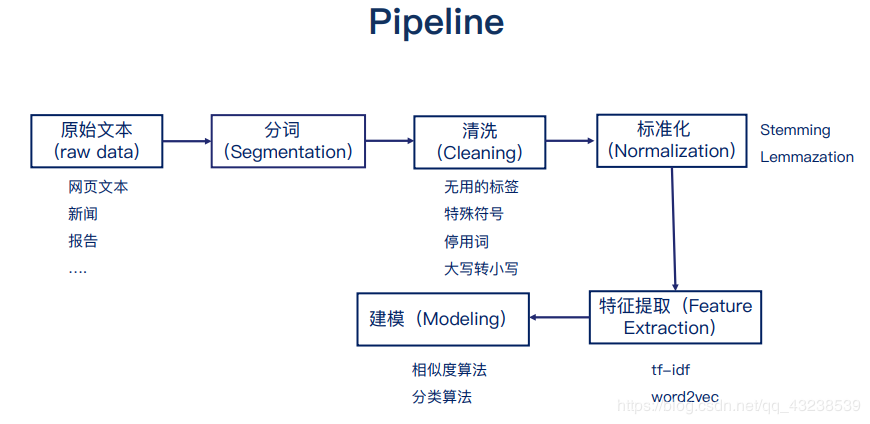
问答系统的整体流程:
(1)根据输入文本 进行分词(segmentation)
(2) 分词完会进行预处理
{①spell correction(拼写纠错 ,一般英文单词进行拼写纠错)
②steming/Lemmazation (对单词进行还原 英文中的时态问题 都将单词还原为原型 例如 going went gone 还原为go)
③stop word(停用词 去掉停用词 不影响大概的语义,提高处理速度)
④word filter(单词过滤,过滤一些无用词 例如这类)
⑤同义词 (同义词转换为语料库问题里边使用的同义词)
⑥(…)
}
(2)预处理完后需要将 文本转换为向量
{
①Boolean vector (1,0,1,0,0,0,1 … bool类型的向量)
②count vector(2,3,6,1 … 具体的数字来表达)
③tf-idf(0.7,0.1,0.1,…词频表示)
④word2vec
⑤seq2seq
}
(3)计算相似度
①余弦相似度(Cosine Similarity)
②欧氏距离(Euclidean Distance)
③马氏距离(Mahalanobis Distance)
(4)排序(对相似度排序)
(5)返回结果
大部分的NLP项目都可以按照下边的流程进行
本次介绍的问答系统也不例外 问答系统不像其他的NLP项目,他不依赖与大量的数据和机器学习模型。

QA思路3
基于外部的知识库,结合原文的知识对解答进行优化
**
补充的外部知识从何而来
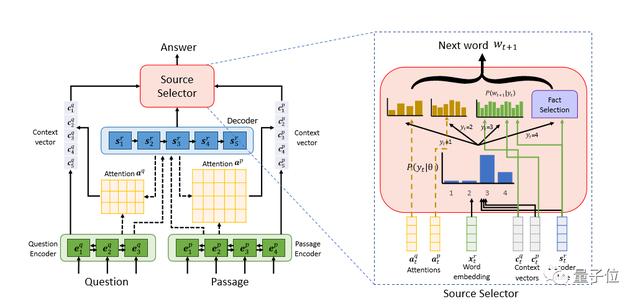
阿里研究团队称新的神经模型为知识丰富的答案生成器,简称KEAG,它能够利用知识库中的符号知识来生成答案中的每个单词。特别是,研究人员假设每个单词都是从以下四个信息源中的一个生成的:1、问题,2、段落,3、词汇和4、知识。
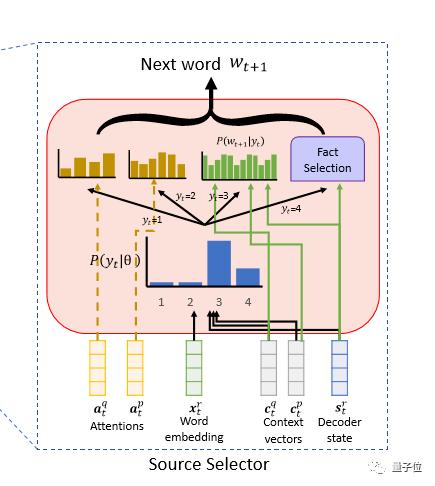
如何从来源中选取需要的知识
为了实现这个目标,研究人员引入了“源选择器”,它是KEAG中的一个定点组件,允许灵活地决定寻找哪个源来生成每个答案词。在阿里研究团队看来,“源选择器”实现的功能是至关重要的。虽然外部的知识的确在答案的某些部分中起着重要作用,但是在答案的其余部分,给定的文本信息还是应该优先外部知识进行考虑。
QA思路4
这个思路比较切合项目的实际,基于NLPCC-ICCPOL 2016比赛
对问题的格式进行了限制,问题基本围绕着是什么和是不是
解决思路就是利用知识库,NER,Relation Extraction技术
下图为参考,相对而言对于NER技术,本项目已经有一定的技术积淀,可以相对好的完成NER,参考链接对于Relation Extraction也有比较明确的解决思路。可行性比较高,思路比较明确。
**
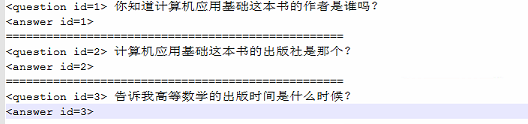
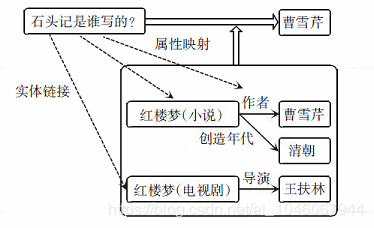

参考链接

若有收获,就点个赞吧
0 人点赞
