利用模型权重直接记住所有的数据是不大可能的,需要考虑去用外部知识,即检索增强的NLP
最直接的KNN-MT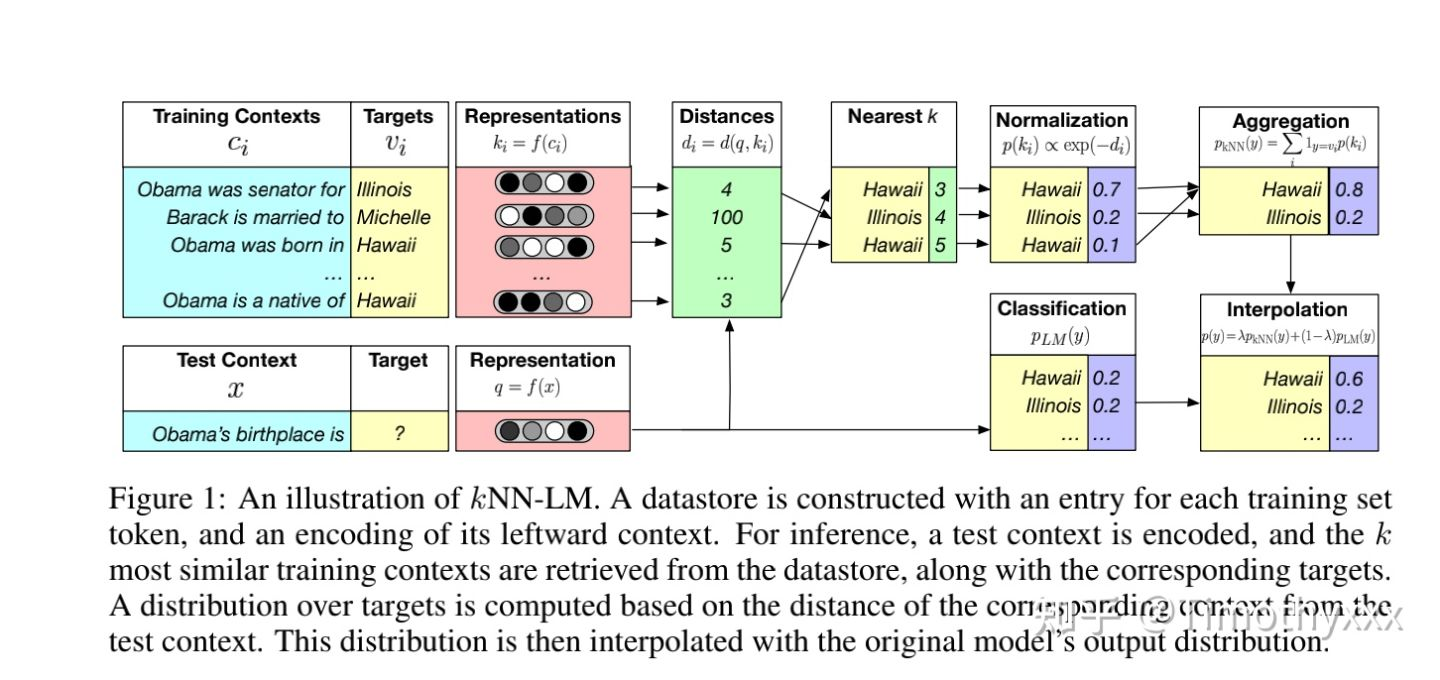
然后是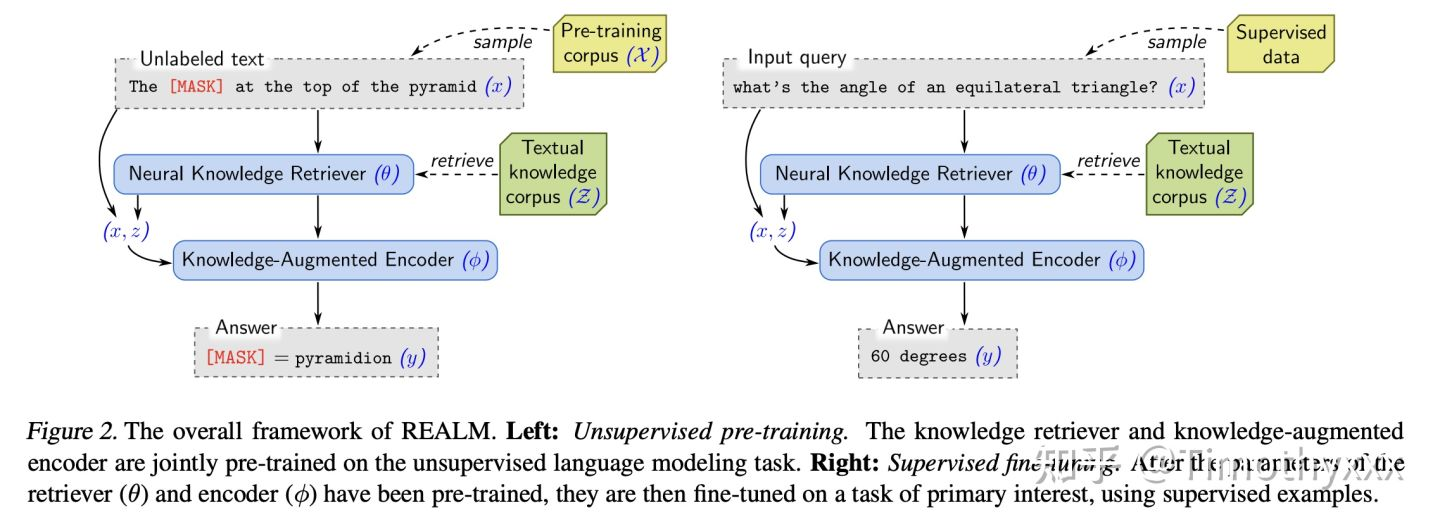
FID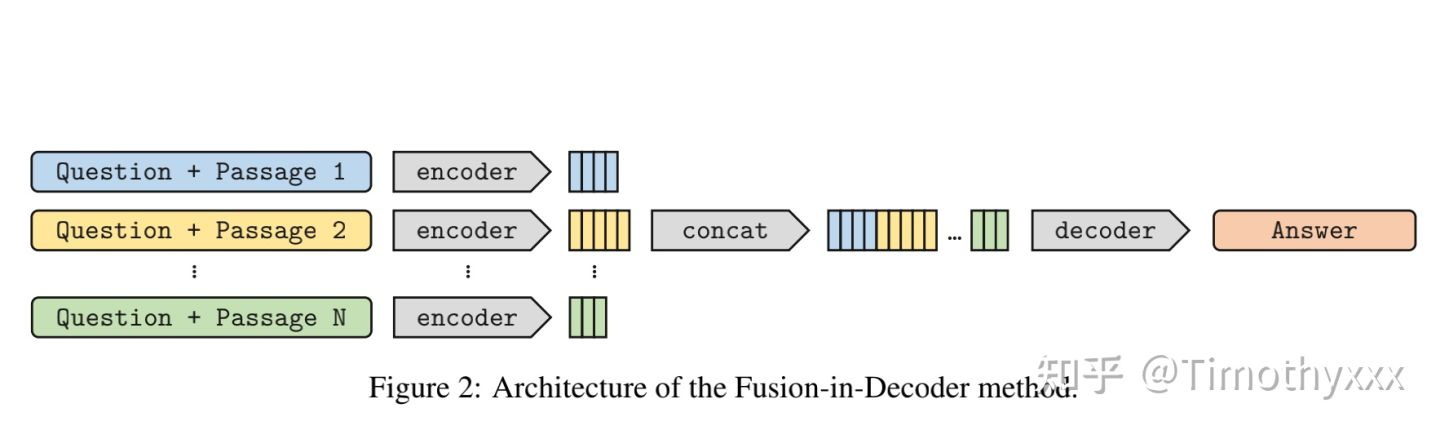
FID-KD
在发完FiD不久,统一团队就对FiD进行了迅速的补充提出了KD的FiD。这个方法解决的痛点是,我们很难去监督我们retrieve出来的结果,因为我们几乎没有对到底检索出来哪些文档有有监督的标注,之前的REALM和RAG也对这个根本没有监督。FiD-KD对此进行改进。 作者注意到在FiD中将所有的encoding拼接之后接下来继续完成seq2seq,会进行一下cross attention,(如果对cross attention不熟悉那么就可以去看看huggingface transformers的BART源码,看不懂可以参考我之前的解读),作者直觉地认为,cross attention的attention值的大小是一个很好的监督信号。cross attention的值这个可以对检索出来的文章进行一个打分,进而作为信号被我们用来拉近retriever的结果和retriever打分的分布。具体的attention怎么处理的,怎样拉近分布比较好详情见论文。
基于检索的预训练
TLM:Task-driven Language Modeling (TLM)
RETRO
TODO

若有收获,就点个赞吧
0 人点赞
