Data
Traindata
Newdata
Dataset

Model
class EncoderRNN(nn.Module):def __init__(self, input_size, hidden_size):super(EncoderRNN, self).__init__()self.hidden_size = hidden_sizeself.embedding = nn.Embedding(input_size, hidden_size)self.gru = nn.GRU(hidden_size, hidden_size)def forward(self, input, hidden):embedded = self.embedding(input).view(1, 1, -1)output = embeddedoutput, hidden = self.gru(output, hidden)return output, hiddendef initHidden(self):return torch.zeros(1, 1, self.hidden_size, device=device)
class AttnDecoderRNN(nn.Module):def __init__(self, hidden_size, output_size, dropout_p=0.1, max_length=MAX_LENGTH):super(AttnDecoderRNN, self).__init__()self.hidden_size = hidden_sizeself.output_size = output_sizeself.dropout_p = dropout_pself.max_length = max_lengthself.embedding = nn.Embedding(self.output_size, self.hidden_size)self.attn = nn.Linear(self.hidden_size * 2, self.max_length)self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)self.dropout = nn.Dropout(self.dropout_p)self.gru = nn.GRU(self.hidden_size, self.hidden_size)self.out = nn.Linear(self.hidden_size, self.output_size)def forward(self, input, hidden, encoder_outputs):embedded = self.embedding(input).view(1, 1, -1)embedded = self.dropout(embedded)attn_weights = F.softmax(self.attn(torch.cat((embedded[0], hidden[0]), 1)), dim=1)attn_applied = torch.bmm(attn_weights.unsqueeze(0),encoder_outputs.unsqueeze(0))output = torch.cat((embedded[0], attn_applied[0]), 1)output = self.attn_combine(output).unsqueeze(0)output = F.relu(output)output, hidden = self.gru(output, hidden)output = F.log_softmax(self.out(output[0]), dim=1)return output, hidden, attn_weightsdef initHidden(self):return torch.zeros(1, 1, self.hidden_size, device=device)
比较值得借鉴的就是这里使用了Attention机制
关于Attention机制可以看我先前的笔记
这里相当于对之前的理论的一次实践(之前其实没完全看懂图片例子,这里对应就可以理解)
Attention Note
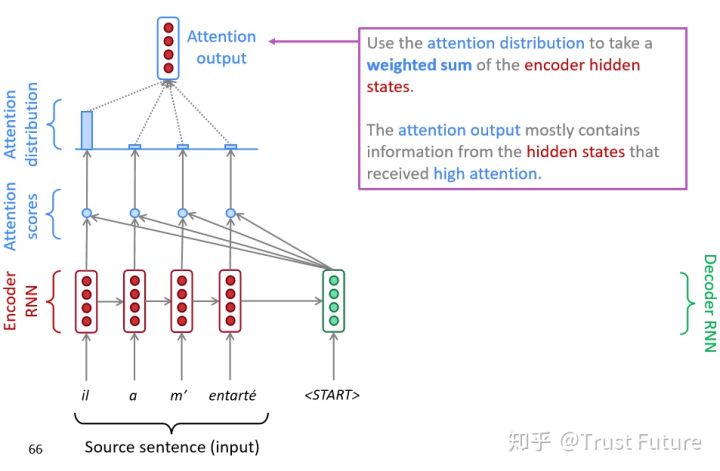
对应的是上面的代码20-23行的位置。
可以看到利用嵌入向量和隐藏状态全连接层规约到hiddensize之后利用softmax进行计算权重
然后利用权重比对encode得到的全句序列向量加权(22行的代码)
这里补充torch.bmm用法
Torch.bmm(A,B)
下面是Attention图例
Training
比较诡异的就是训练的时候,每一次输入一个句子
然后一个字一个字的输入模型,每次把输出的向量放在列表里
所以就会很慢,想改成用Dataloader直接多batchsize的计算,但是不知道怎么改。
def train(input_tensor, target_tensor, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):encoder_hidden = encoder.initHidden()encoder_optimizer.zero_grad()decoder_optimizer.zero_grad()input_length = input_tensor.size(0)target_length = target_tensor.size(0)encoder_outputs = torch.zeros(max_length, encoder.hidden_size, device=device)loss = 0for ei in range(input_length):encoder_output, encoder_hidden = encoder(input_tensor[ei], encoder_hidden)encoder_outputs[ei] = encoder_output[0, 0]decoder_input = torch.tensor([[SOS_token]], device=device)decoder_hidden = encoder_hiddenuse_teacher_forcing = True if random.random() < teacher_forcing_ratio else Falseif use_teacher_forcing:# Teacher forcing: Feed the target as the next inputfor di in range(target_length):decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)loss += criterion(decoder_output, target_tensor[di])decoder_input = target_tensor[di] # Teacher forcingelse:for di in range(target_length):decoder_output, decoder_hidden, decoder_attention = decoder(decoder_input, decoder_hidden, encoder_outputs)topv, topi = decoder_output.topk(1)decoder_input = topi.squeeze().detach() # detach from history as inputloss += criterion(decoder_output, target_tensor[di])if decoder_input.item() == EOS_token:break#print("not use decoder_output.size() ", decoder_output.size())loss.backward()encoder_optimizer.step()decoder_optimizer.step()return loss.item() / target_length
Result
原数据集数据较大
有135824个句子对
训练仅仅是用了75000个,本地GPU大约1小时半
同时数据集的句式相对分布集中,感觉对结果有一定的影响
(例如:下面的句子的句式都是人称代词,然后be动词,然后接一些句子,于是在训练的过程中很明显的,训练没多久就可以做到人称代词和be动词翻译出来,但是后面翻译的很糟,要么不对,要么缺少词语)
下图是随机抽取句子进行预测翻译
观察训练结果,可以发现句子基本翻译和Label一致,少数的翻译有不同,但是意思基本一致或者是比较相近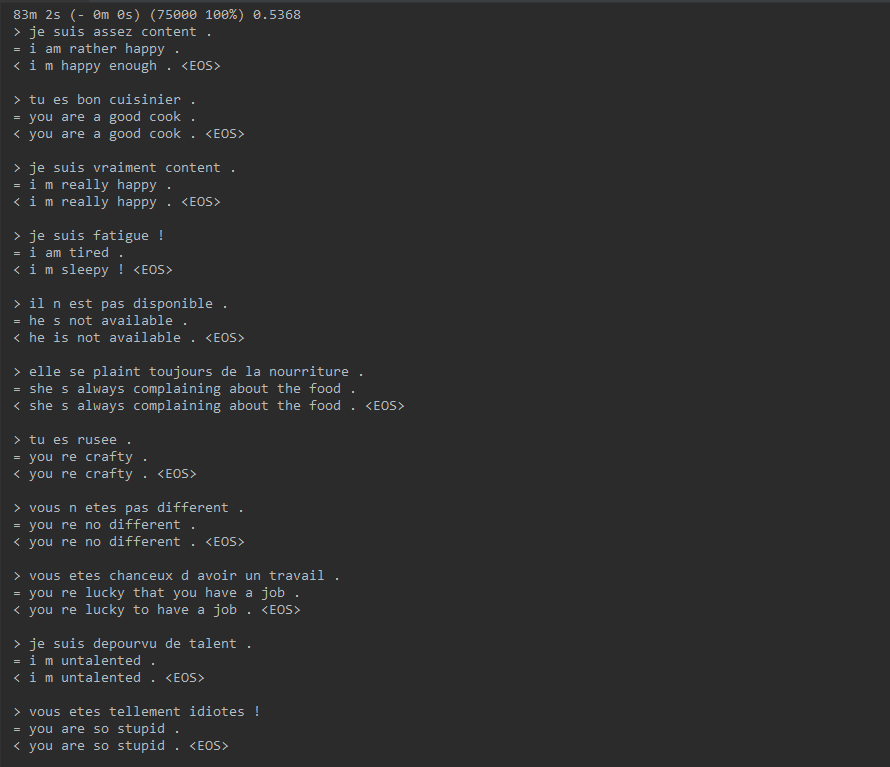
其他
有点想魔改一下中英翻译
中英翻译的数据集也已经找好了
双语的语句对的数据集,30+M,还是很大的。
毕竟法语看不懂,也没啥直观的感受,也没啥实用性(。。。)

若有收获,就点个赞吧
0 人点赞
