论文综述《Extractive Summarization as Text Matching》
1. Abstract
原来的模型独立的分析句子关系,对句子单独抽取
这里把摘要生成建模成一个文本语义匹配问题,是在原文和多个候选的摘要里做匹配
基于句子级别和摘要整体级别的抽取性能上有所差距
2. Introduction
现有的神经网络抽取式摘要生成聚焦于对句子评分和抽取(或者是在更小的维度上)
对句子的抽取和生成摘要看作是一个序列标签的生成过程
这些模型对句子独立的进行二分判断
上述的各种方法和改进都局限于句子级别的分析
为了评估和区分这两种粒度的句子摘要生成手段,我们设置了6个标准数据集评估,发现了二者的性能差异,进而产生了继续研究的想法
最后的问题就转化为了对句子语义相似的求解,传统的方法就是用相似矩阵去得到句子矩阵,然后求余弦相似度
3. Related Work
抽取式摘要
两阶段摘要
第一阶段抽取片段,第二阶段选择和修改片段的主要部分
很多模型都是使用了这样的两个网络
这里可以看作是抽取和匹配两个的框架,使用抽取来删除不必要信息
4. 句子级别还是摘要级别
之前已经指出了句子级别的抽取的缺点
这里调查了二者的差距,使用的句子级别的抽取器没有加上去除容易的过程以对比摘要级别的消除冗余能力,这种调查方式是有泛化性的,能够用在其他的摘要水平的方法上
5. 定义
句子级别得分

摘要级别打分

珍珠摘要
摘要有着较低的句子级别分数和较高的摘要分数
一个候选摘要如果有另一个候选摘要满足上述条件就是珍珠摘要
这种摘要对于句子级别的抽取器是一种挑战
最佳摘要
最佳摘要排序
对所有的候选摘要进行排序,用句子级别的评分结果
其中最佳摘要的位置就是z
简单的说,如果最佳摘要z=1,也就是最佳摘要是由分数最高的句子构成
z>1说明最佳摘要是珍珠摘要
于是开始调查珍珠摘要的比例
使用了6个Benchmark数据集如下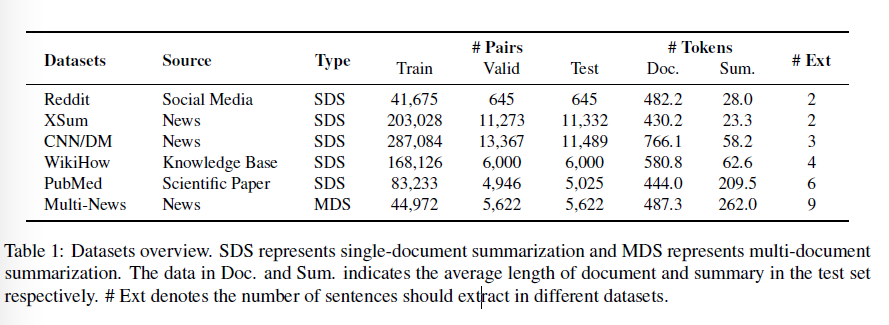
可以观察到多数的最佳摘要不是句子级别的最佳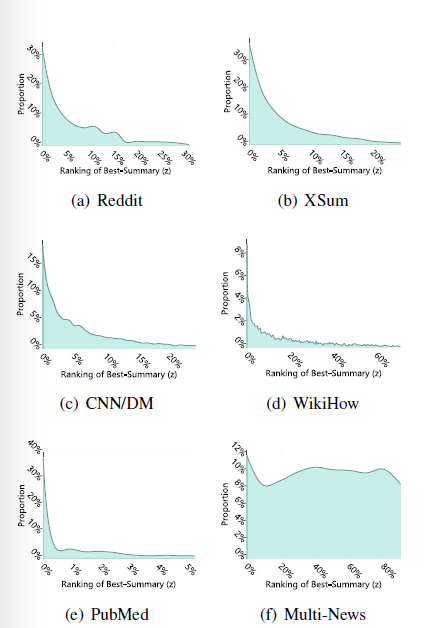
两个粒度抽取的Gap
如下分别计算候选摘要里两个粒度的分数Max之后计算差值
结果如下
显示的结果就是过长和过短的文章都使得没有大的改进,对于中等长度的有了意义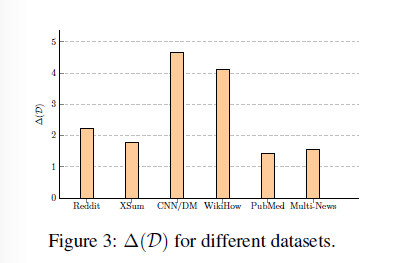
6. Summarization as Matching
Siamese-BERT
直接使用原Bert对文档和候选摘要进行评分,使用CLS处的向量作为句子的编码向量
然后使用余弦相似度对二者进行相似度评分
为了对上述的模型进行微调,使用了”margin-based triplet loss to update the weights”
Loss Function
第一个损失函数:
对于标注摘要显然是语义最为接近原文档的
第二个损失函数:
对候选文档使用ROUGE进行排序之后
对于排名差距大的候选句子对应该由更大的Margin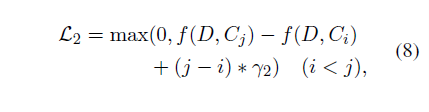

基本的思路就是标注摘要的得分最高,然后好的候选摘要应该有更高的分数
最后的摘要就是有最好分数的候选摘要
Candidates Pruning
如何选择句子候选集还是全部评分
推出一个简单的句子选择策略:对每一个句子设置一个语义值,然后删除不相关的句子
最后就会得到EXT个句子,然后直接形成候选集(用原文档里的语序顺序进行组合,排列组合)
7. Experiment
数据集
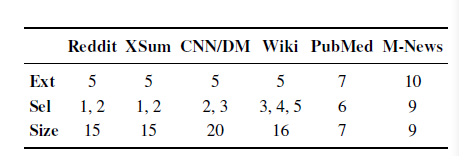

实现细节
使用基本的Bert,以及Adam优化器和Warm_up步骤

使用验证集保存三个最好的模型数据,然后记录在测试集上的表现
数据的处理:移出空的句子,然后把文档的长度截断到512
实验结果
即便是RL算法使用了对整个句子的评分依旧对效果没有太多的改进,可能是由于还是没有摆脱一个句子一个句子选择的方法。Trigram Blocking在CNN/DM上有出奇的好效果。
模型把句子映射到语义空间,所以可以自由的选择句子的长度,而不是只能够抽取固定长度的摘要
原论文对长摘要和短摘要的数据集进行了分析
实验分析
模型表现是否和数据集特征有关?
为何不同数据集的模型表现不一致?
做法:对有大的表现提升的数据集根据Z做了切分为5块,然后对子集测试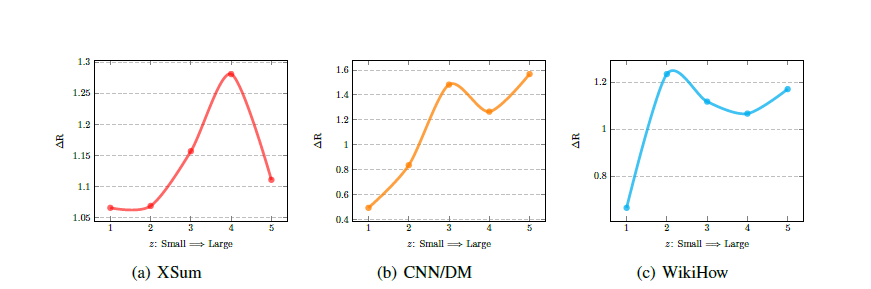
对于珍珠摘要的比例多的数据集能够有更好的效果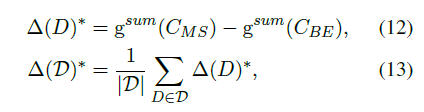

这个学习比例和z以及标注摘要的长度有关系
长度越长越难达到上界
如果标注摘要的长度差不多,那珍珠摘要比例高的数据集模型表现更好
明白了数据集特征对模型表现的影响有利于理解模型的长处和缺点

若有收获,就点个赞吧
0 人点赞
