考虑到之前的Prefix-Prompt的方法都是单独训练多个prompt,因此这里提出了一个方法可以同时训练多个Prefix,考虑到了之间的关系
设计的Prefix其实就是连续的Prompt,然后每一层都有 N _D _ M维度,分别是个数,层数和隐藏维度
训练方法
全监督方法
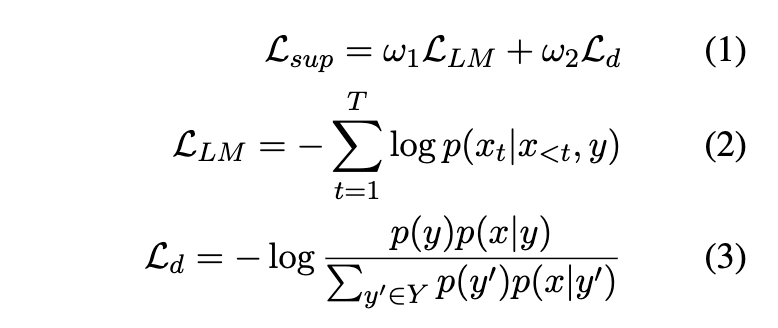
全监督就是给定了Prefix应该是哪个,因此这个index是固定的,只需要直接优化当前prefix的生成Text的概率,以及作为对比学习降低其他prefix可以生成text的概率。
无监督学习
没有指定prefix,则需要估计出prefix的下标,于是用一个概率去估计
估计方法就是用Encoder编码X,然后和每一个下标做距离后Softmax
假设了下标的概率分布是一个平均分布,因此用了一个KL Loss要求分布和平均分布看齐



若有收获,就点个赞吧
0 人点赞
