https://www.cnblogs.com/mengnan/p/13658021.html
标签平滑(Label Smoothing)
标签平滑适用于在分类问题中,类别数较多的情况下,防止过拟合,本质是一种正则化策略,显式添加噪音防止模型对自己的判断过于自信。如果使用Fairseq,只需要在训练时指定使用label_smoothed_cross_entropy损失函数即可。一个简单的例子:python fairseq_cli/train.py <DataPath:str> --max-token <MaxToken:int> --arch transformer --criterion label_smoothed_cross_entropy --label-smoothing 0.1
平均模型参数
对训练获得的,一定训练步数范围内的模型参数进行平均,通常也会有提升,这一点有点像集成学习,但是集成学习一般是对模型的输出结果进行投票或者平均,但是此处是直接对模型本身的参数进行平均。一般可以平均训练末期的,最后10~30轮的模型参数。注意,在平均模型参数时,一定要对模型训练充分,如果待平均的模型本身就没有充分训练,平均模型参数相反可能有害。
如果使用Fairseq,可以使用fairseq/scripts/average_checkpoints.py,其它框架可以参照此代码。python scripts/average_checkpoints.py --inputs <CheckpointDir:str> --output <AvgCheckpointPath:str> --num-epoch-checkpoints 10
集束搜索(Beam Search)
相比于分类任务,生成任务通常是一个时间步一个时间步依次获得,且之前时间步的结果影响下一个时间步,也即模型的输出都是基于历史生成结果的条件概率。在生成序列时,最暴力的方法当然是穷举所有可能的序列,选取其中连乘概率最大的候选序列,但该方法很明显计算复杂度过高。一个自然的改进想法是,每一个时间步都取条件概率最大的输出,即所谓的贪心搜索(Greedy Search),但这种方法会丢弃绝大部分的可能解,仅关注当下无法保证最终得到的序列最优。集束搜索实际是这两者的折中,简言之,在每一个时间步,不再仅保留当前概率最高的1个输出,而是每次都保留num_beams个输出。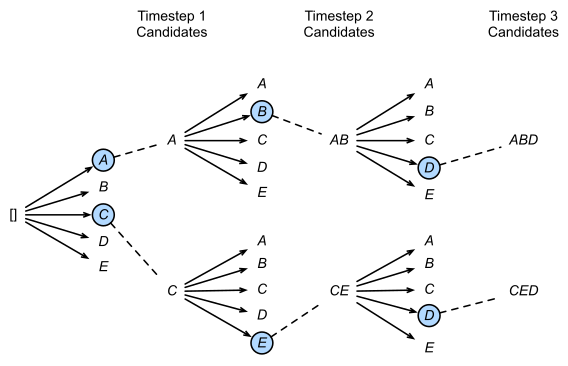
如上图所示,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止,条件概率最优的2个序列。
如果使用fairseq,可以直接在生成时指定参数--beam即可。一个例子:python fairseq_cli/interactive.py <DataDir:str> --path <CheckpointPath:str> --batch_size 128 --beam 5
集束搜索在fairseq中的具体实现位于fairseq/search.py中。

若有收获,就点个赞吧
0 人点赞
