Insight & target problem
很多之前的工作都只关注做事实不一致的检测
这篇论文瞄准了事实不一致的修改
Solution
做法就是人工构造负例作为训练样本
然后用BART
input:Document + May Fake summary
output Target :Summary
训练数据集使用CNNDM,选择30%的样例为负例
,
测试使用的是K2019,一个之前构造的,由多个系统产生的摘要,已经被标注了正确还是错误
Highlight
效果有点一般般
手工构造的和下游任务的真实使用环境有一点的gap
识别的正确率和修改的正确性都有一点问题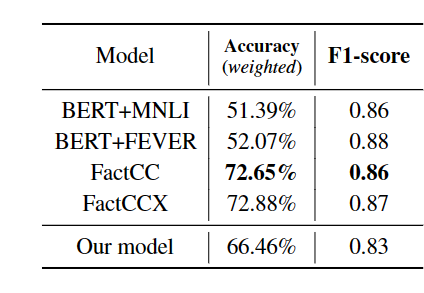
400多个正确的样例,改了39个,把5个改错了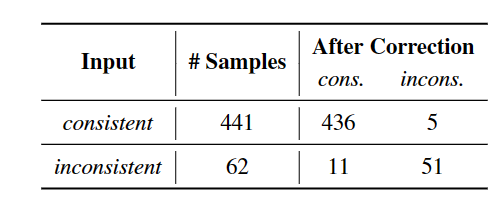
Others

若有收获,就点个赞吧
0 人点赞
