Introduction
- 强调文档级别编码的重要性
- 很多的工作如:复制机制,强化学习,多重交流encoder,但是作者的效果最好,且没有用这些机制
- 在抽取式和生成式任务都能够高效的部署预训练模型
- 推出的模型可以作为进一步提高总结性能的垫脚石,也可以作为测试新idea的baseline
作者同时推出了抽取式和生成式的模型
- 抽取式模型建立在encoder的顶部,又堆叠了若干层的句间transformer层
- 生成式模型使用了encoder-decoder框架,encoder用的pretrain的bert,decoder是随机初始化的transformer
- 由于encoder和decoder有的有预训练,所以训练的时候应用了不同的学习率
- 作者借鉴了我之前看的远古论文SummaRunner的思路,使用了2-stage的train,先抽取后生成使得encoder被fine-tuning两次
BackGround
抽取式方法
- REFRESH强化学习方法
- LATENT直接选择人类标注的句子(而不是在Select oracle)
- SUMO建立结构Attention和Multi-Root依存树
- NEUSUM打分和选择jointly
生成式方法
- PTGEN,point-generator network可以从原文复制词语
- Coverage mechanism 追踪已经被摘要的词语
- 多encoder编码原文之上Attention再decode
- BUTTOMUP,先预先决定要用的短语,再在候选短语上用Copy mechanism
抽取式模型
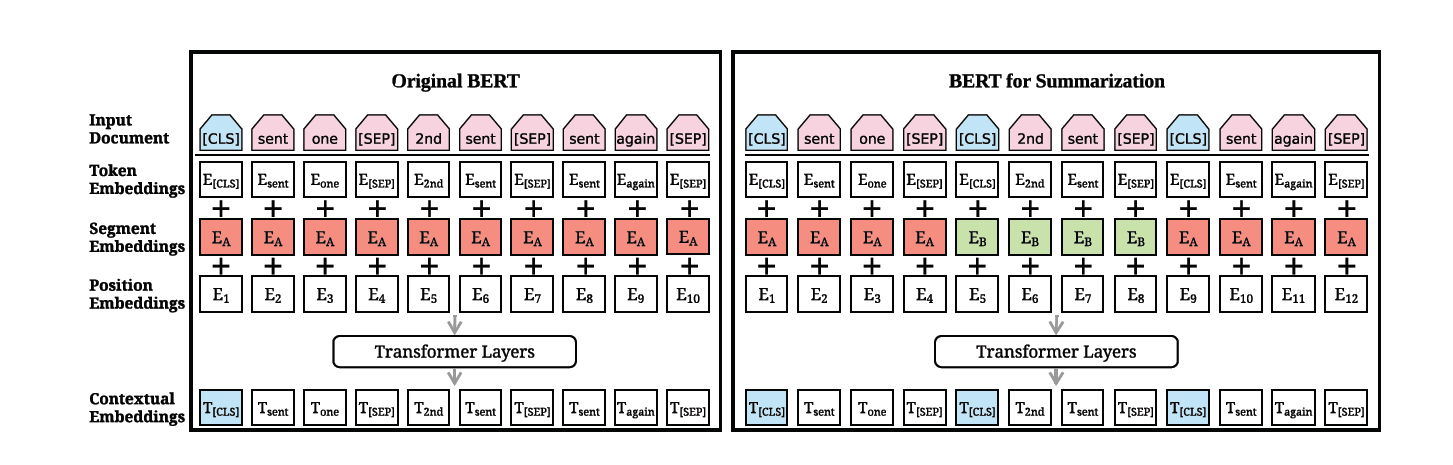
原先的Bert还是Token级别的,但是Summary一般是句子级别的
对原bert改进
- 输入一个document,但是在每一个句子的句首和句尾都加上了CLS和SEP
- segment embedding句子间间隔使用【EA,EB,EA,EB····】
- 增加了position embedding(突破512),随机初始化,然后训练中确定
这里的魔改版Bert被称为BERTSUM
用BERTSUM的每一个CLS作为句向量,然后句向量混在一起加上Position Embedding送到transformer里
最后一层的output用Sigmoid
经过实验在BERTSUM上层的Transformer两层比较合适
这里的模型被称为BERTSUMEXT (原bert的原理,结合Attention is All you Need笔记看)
(原bert的原理,结合Attention is All you Need笔记看)
生成式模型
encoder-decoder框架
encoder用BertSUM
decoder随机初始化的6层transformer
二者不匹配,使用不同的学习率
双阶段的fine-tuing
先在extractive上微调encoder,再在abstractive上进一步微调
普通的单阶段的模型:BERTSUMABS
双阶段微调:BERTSUMEXTABS
**
experimental Setup
数据集分析维度
- 句子长度,数目
- % novel bi-grams:指示的在原文中没有,但是在标注摘要中出现,这个比例高意味着这个数据集可能更加倾向于使用生成式模型来解决

抽取式训练加上了Trigram Block 来移出冗余(正在考虑的句子和已经在摘要里的句子的相似度低)
生成式训练用了长度惩罚,和trigram block,没有使用流行的copy和coverage机制
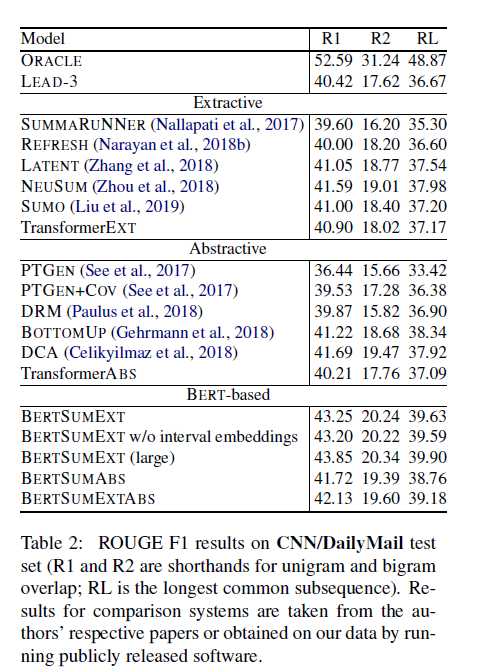
- 注意到CNN/DM的 novel bi-grams的比例并不高。或许就是因为这个导致了abstractive的分数没有extractive的高
- 另一个是观察到了TransformerEXT使用了和BERTSUM一样的架构(no-pretrain,参数少一些,hiddensize只有512),注意到了效果的巨大差距(2个点的分差)
- TransformerABS用的是一样的decoder,encoder就是普通的6层,768和2048的transformer,也发现了和BERTSUMABS的差了一个点的分数,或许可以证明BERTSUM对BERT的改进是有效的?
- BERTSUMEXTABS比BERTSUMABS有0.5左右的分差,或许可以证明2-stage的train有效
在NYT的数据集上使用了Limited-length ROUGE,用的还是recall的值,最后的结果几乎达到Oracle(不过Extractive方法还没有达到oracle,大致还有3个点的分差,BERTSUMABS和BERTSUMEXTABS分别达到了48.92和49.02,在ROUGE1上几乎达到Oracle)
其实我觉得分数能这么好,一个是本身ABS方法的上限就高(ROUGE上限100即和标注一模一样),另一个他的这个计算方法也很奇怪,计算的ROUGE是把自己的摘要砍的和标注一样长再计算,为啥这么做?第三点就是这个表格的值用的还是Recall,这个更加倾向于把词全都预测出来?具体可能还得再去他引用的那篇论文看看
XSUM上由于摘要只有一句,所以抽取式比较吃亏
Model Analysis
- 学习率分析:对不对等的encoder和decoder的学习率分析
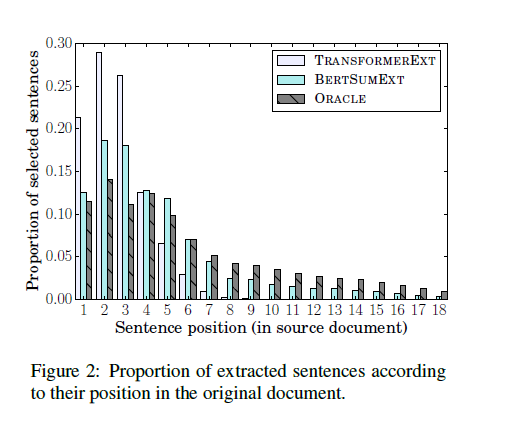
- 抽取句子位置分析:分析得到了
- Oracle的分布更均匀
- TransformerEXT的位置倾向于前几句,这个从Transformer的效果和Lead类似也可以看出来(模型只会选前几句)
- BERTSUMEXT的分布更加均匀更像ORACLE,看起来摆脱了位置关系,得到深层语义
- Oracle的分布更均匀
- Novel N-grams,分析摘要生成中不在原文,但是在摘要里的比例,
- 发现CNN/DM上相对比reference低,但是在XSUM这种模型上就会表现的更好
- 同时发现BERTEXTABS产生的比例少,可能是由于在extractive上训练了,使得更加的倾向于在原文里找句子和词语
- 发现CNN/DM上相对比reference低,但是在XSUM这种模型上就会表现的更好

若有收获,就点个赞吧
0 人点赞
