这篇论文主要使用对比学习的框架来提升摘要生成的正确性
首先是对比学习框架,需要构造正例和负例,训练方法就是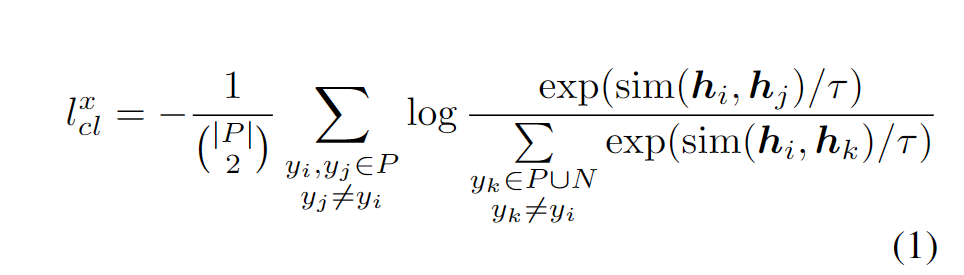
我的理解就是编码正例负例,然后要求正例的相似度占比大,取负即要求损失最小,把这个损失和常规交叉熵合在一起。
然后问题就成了
- 怎么构造负例?
- 怎么表示正例负例?即 h_i的获取方式
- 怎么评估我的结果
首先是构造正例和负例,构造正例就简单的用回译做的,先翻译到德语,然后翻译回来
负例怎么构造?这里引入了很多种的做法。也是论文的重点。
本文的insght是从概率上手的
首先把事实正确性进行了重新的分析
- 内部错误:原文有的,生成结果里没有
- 外部错误:原文没有的,但是生成的结果里有,同时这个生成的结果信息不能在Wiki里验证
- 外部知识:原文没有,生成有,但是可以在Wiki里验证正确

然后作者就分析,什么时候会有这些现象?
于是作者抽取模型生成的外部错误中(外部错误一般是一个Span,一个短语),错误的短语第一个词语是出生成名词或者是数字的时候,模型的概率分布,置信度。发现模型在生成外部知识的时候,是很有信心的,但是生成外部错误的时候,置信度很低。即图里的extri和intri都集中在低概率的位置。
于是作者认为在生成负例的时候,可以考虑使用生成模型来构造
负例构造策略
- SWAPENT:交换实体,保证实体类型的情况下随机采样(之前的论文是不管实体类型的)
- MASK-and-Fill:
- MASKENT:用BART,在reference的一些实体MASK,然后输入reference(其实和BART pretrian的操作是一样的)
- MASKREL:首先用这种实体关系抽取模型抽取,然后把关系两端的实体mask,要求fill-mask之后的关系必须要是一种新的关系,比如 A relatoin1 B,把A,B mask-fill之后得到的C和D之间的关系是新的一种关系
- REGENENT,REGENREL:基于source的重新生成,REGENENT这个思路是Encoder输入原文,decoder的输入是要生成的实体前面的句子作为prompt,然后生成实体以及后面的部分,要求生成新的实体。同样的可以做到REGENREL,即生成的部分是新的关系。
- SYSLOWCON:即基于上面的模型概率分析,在生成名词和数量词的时候,假如置信度过低,就把这个样本构造为一个负样本
评估
评估实际上用了一些我不大熟悉的东西(可能需要进一步的补充事实证确性的paper)
比如
- QuestEval(用QA做质量评估)
- FactCC
- ROUGEL
- 还有一些略过。
总之有很多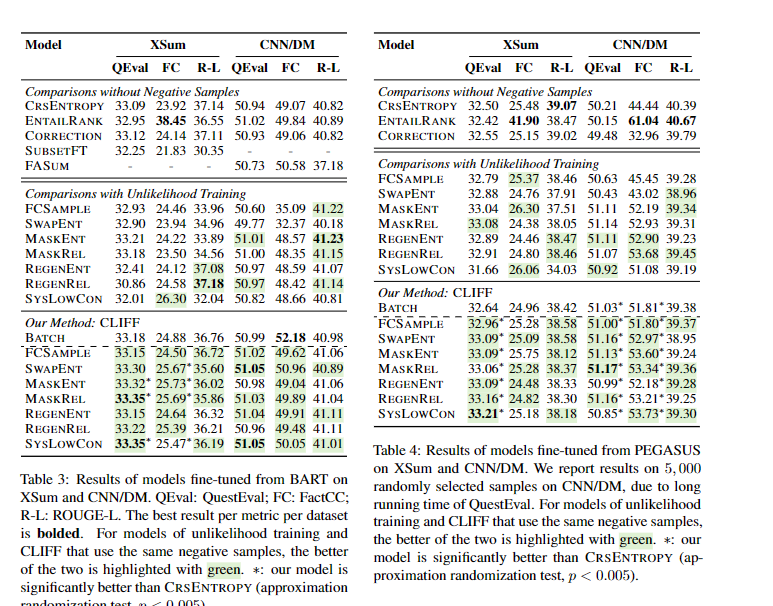
由于我不大熟悉其中的很多工具和对比,所以这里主要概括一下我能理解的一些insight
除了常规的对于错误类型的标注和分析之外(就是请语言学家来看看每一个模型的结果打分)
还进行了修正类型的标注,即请语言学家对比常规模型,新的模型结果的改变
主要有三种,一种是修正错误,第二种是删除错误,第三种是二者都做了
对比结果可以看出,新的模型(CL开头,对比学习的缩写)做了比较多的修正,尤其是一些替代修正,可能和负例的构造模式有关,由于是对实体进行修改,可以比较好的修改错误,而不是直接删除
Feature如何获得
怎么表示摘要来做对比学习?简单的做法即把decoder-output作为表示。
这里的表示是[batch,Seqlen,hiddensize]。然后需要从整个生成结果的表示里聚合得到一个表示。他考虑了多种方法,比如只拿出实体所在的表示平均,整个的表示平均,或者是加上一层MLP来实现。
论文分析是发现,实体是一个好的信号,但是最好的是用MLP,避免模型的退化。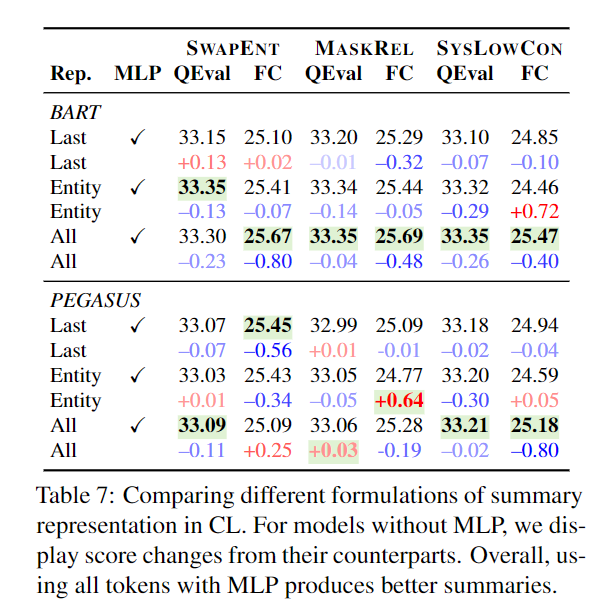
个人理解
我个人感觉,使用模型来预测以及构造负例是很不错的想法,在其他领域应该很早就有应用(我之前在半年前的一次活动里,就有看到用BERT来构造新数据的方法,更早的我就不知道了)
这相当于
- 对预训练模型里面包含的信息的再利用,和prompt一个目的
- 预训练模型含有大量的先验知识,这很有可能是影响了模型的生成。就比如在预训练语料中,A这个人往往和某个事件相关。那模型可能在生成的时候,更多的依靠了自己的预训练知识,而没有看到原文。那么在构造负例的时候,这种情况的数据就会被构造为负例,很好的避免了模型的偏置
- 就是论文里说的这种模型行为的分析,在生成外部错误,而不是外部知识的时候。模型是没有信心的。这也是构造的一个理论依据。
- 以及利用对比学习去教会模型什么是好的,什么是有错误的。这个思路其实和我最早进组接触的MatchSum是类似的,MatchSum是把20个可能候选的抽取式摘要以及标注摘要作为对比学习的对象,标注摘要ROUGE最高,以此排序所有的候选,本质也是在做对比学习,让模型知道什么是好的,什么是差的。这种灵活的思路让复杂的问题简单化,简单化到一个Match的问题。

若有收获,就点个赞吧
0 人点赞
