摘要(文本生成)一直存在一个问题:重复生成
为啥会重复生成?因为Attention一直集中在某一个区域,模型眼睛一直不动。
因此有人提出用全局语义来辅助模型的视野。但是全局语义又太大了,容易直接覆盖了。
因此还要用一个Gate机制,决定到底多少全局语义要流入。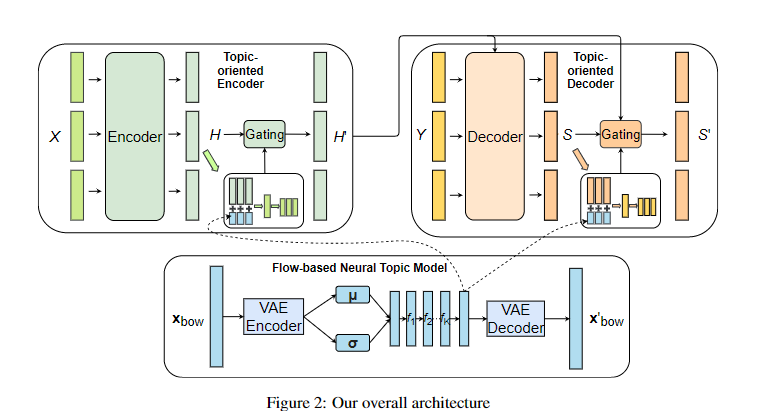
简单的来说,模型利用原文构造BOW Feature,然后用VAE Encoder提取。
经过若干的非线性变化作为Topic Feature,分别注入到Encoder和Decoder。
注入过程利用了Gate机制:
- 先和Hidden State拼接,然后再用线性变化回原始大小,即加入了全局语义后的表示
- 再用输入头部插入的CLS Token对应的向量线性变化后经过Sigmoid即Gate的权重
- 然后利用 G x +(1-G)y 这种形式(G为Gate权重)
- Decoder端类似
最后训练损失为摘要生成损失+下面VAE Encoder-Decoder结构损失
VAE的损失其实没看懂。。。
然后不知道是不是因为VAE没看懂,导致了他为啥要用VAE作为所谓的Topic Extractor我没看到论文有进一步的说明。以及Flow Based和单独的VAE有啥区别?加了几个non linear transform?感觉很奇怪,后面把flow based和VAE进行了对比,,,但是论文用的不就是VAE吗。
最后的对比就是和一些传统的主体模型对比,LDA,LSA之类的

若有收获,就点个赞吧
0 人点赞
