Insight & target problem
认为有很多的幻觉是来源于数据自己的问题
这个论文用的是GigaWord和一个日语的数据集
Solution
作者用摘要词在文中出现的比例作为估计事实一致性的指标
然后探究了一下,到底Document能不能够支持summary(他怀疑不能)
于是发现还真不能,只有70%的可以被支持,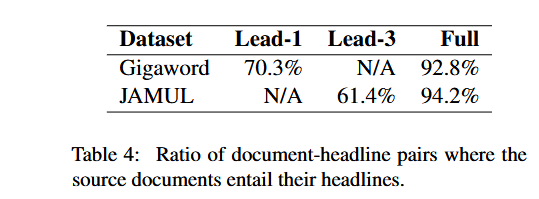
于是想了一种办法来过滤,过滤就是用NLI模型去判断是不是entail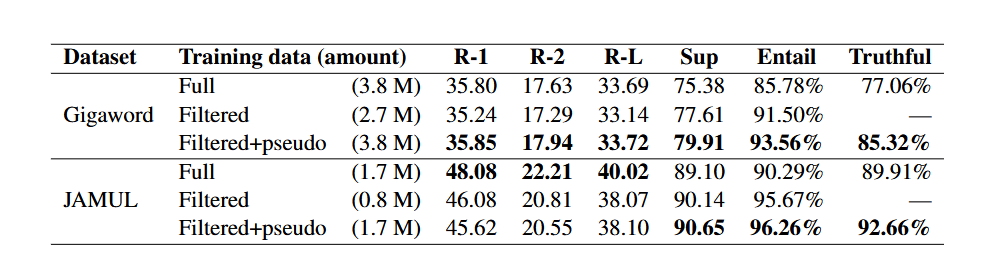
Highlight
Others

若有收获,就点个赞吧
0 人点赞
